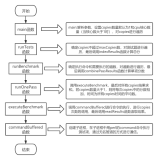
VPP支持多线程模式,其中区分为main线程和worker线程,这两种线程都运行vlib_main_or_worker_loop函数作为线程主函数,主要区别在于执行时的is_main参数。
主线程可以调度执行所有类型的node,工作线程只能调度 VLIB_NODE_TYPE_INTERNAL和VLIB_NODE_TYPE_INPUT类型的结点。
在设置工作线程的时候,工作线程数最好和网卡的收包队列数保持一致。
6.1 多线程架构
所有的VLIB_NODE_TYPE_PROCESS结点登记的任务均被处理为使用jmp机制的协程。
而worker线程由pthread_create新建是传统意义上的线程模型,每个worker线程都被绑定到相应的核上。
VPP进程
├── main线程
│ ├── process协程1
│ ├── process协程2
│ └── process协程3
├── worker线程1
└── worker线程2
具体的工作线程初始化操作由 static clib_error_t *start_workers(vlib_main_t *vm)函数负责
每个线程都有自己的线程堆栈vlib_thread_stacks,mheap,vlib_main_t,nodes,frames,next_frames,pengding frame等数据结构。
6.2. 线程间同步
VPP多线程之间同步采用的是类似于带信号和超时机制的自旋锁,主要有check、sync、release操作。
总体上类似于pthread_cond_timedwait中的互斥体改成自旋锁所提供的功能,超过BARRIER_SYNC_TIMEOUT时间的话说明可能发生死锁故直接abort。
其中:
vlib_worker_thread_barrier_check类似于pthread_cond_wait操作,等待vlib_worker_threads->wait_at_barrier条件。
vlib_worker_thread_barrier_sync类似于spin_lock操作,置位vlib_worker_threads->workers_at_barrier。
vlib_worker_thread_barrier_release类似于spin_unlock操作,复位vlib_worker_threads->workers_at_barrier。
6.2.1. vlib_worker_thread_barrier_check
vlib_main_or_worker_loop函数在开始时会调用vlib_worker_thread_barrier_check函数用以检查线程间的同步情况。
vlib_main_or_worker_loop代码片段:
while (1) {
vlib_node_runtime_t *n;
if (!is_main) {
vlib_worker_thread_barrier_check();
vec_foreach(fqm, tm->frame_queue_mains)
vlib_frame_queue_dequeue (vm, fqm);
}如果某个线程申请访问临界区那么本worker线程暂时不去处理数据,自旋等待。
vlib_worker_thread_barrier_check代码片段:
if (PREDICT_FALSE(*vlib_worker_threads->wait_at_barrier)) { // 某个线程申请访问临界区
clib_smp_atomic_add(vlib_worker_threads->workers_at_barrier, 1); // 本线程将进入自旋状态,登记workers_at_barrier
while (*vlib_worker_threads->wait_at_barrier) // 本线程进入自旋状态
;
clib_smp_atomic_add (vlib_worker_threads->workers_at_barrier, -1); // 本线程将退出自旋状态,取消登记workers_at_barrier4.2.2. vlib_worker_thread_barrier_sync
count = vec_len(vlib_mains) - 1; // 这里count数等于vlib_mains的vector长度 - 1 ,也就是worker线程总数 - 1
deadline = vlib_time_now(vm) + BARRIER_SYNC_TIMEOUT;
*vlib_worker_threads->wait_at_barrier = 1; // 本线程获得锁,所以将该条件变量标志置为1
while (*vlib_worker_threads->workers_at_barrier != count) {
// 自旋等待其他线程(在其他核上)将变量vlib_worker_threads->workers_at_barrier设为count
// 当count等于workers_at_barrier时,其他的worker线程均处于自旋状态,也就是其他线程被锁住操作,本线程可以开始访问临界区
if (vlib_time_now(vm) > deadline) {
fformat(stderr, "%s: worker thread deadlock\n", __FUNCTION__);
os_panic();
}
}4.2.3. vlib_worker_thread_barrier_release
deadline = now + BARRIER_SYNC_TIMEOUT;
*vlib_worker_threads->wait_at_barrier = 0; // 本线程释放锁,所以将该条件变量标志置为0
while (*vlib_worker_threads->workers_at_barrier > 0) {
// 自旋等待其他线程(在其他核上)将变量vlib_worker_threads->workers_at_barrier设为0
// 当count等于0时,其他的worker线程均处于工作状态,所有线程均退出临界区
if ((now = vlib_time_now (vm)) > deadline) {
fformat (stderr, "%s: worker thread deadlock\n", __FUNCTION__);
os_panic ();
}
}