整天说数据库有点腻歪,今天换个话题,讲讲关联性算法。本文首先简单介绍一下经典的apriori及其改进算法FP Growth,最后介绍一下当年咩叔写论文时候琢磨出的一个利用图论实现的在线实时计算的“图权重算法”。
说到算法…道友请留步,请留步……

老夫知道少侠们都很忙的,而且有时候一些东西确实令人不快,比如

讲真,老夫也不喜欢那些阿尔法贝塔啥的玩意!要不是因为穷,我研究什么算法啊。所以在此文中,我们只讲四则运算,坚决不烧脑。

本文标题“啤酒与尿布”是一个烂大街的MBA梗:沃尔玛通过数据分析发现很多买啤酒的年轻爸爸都要买尿布,从此将啤酒与尿布放一起,balabalabala…
讲真,老夫一直很怀疑这个梗的真实性,因为从没见超市中啤酒和尿布放一起啊。“啤酒配炸鸡”才是正确摆放方式,是吧。
嗯,标题虽老,但是经典,就好比一说到经典的苍老师,我们就会想起逝去的“青春”以及E盘“学习资料“文件夹。
这种“苍老师“→”青春“→”学习资料“之间的想象关联,体现的是人类的发散性思维(Divergent Thinking,是一种呈现扩散状态的思维模式),是创照性思维的核心,是创照力的体现。
你们看,以上“青春”与“学习资料”是高尚而纯洁的。老夫接下去就要介绍高尚而纯洁的“关联性算法“。
所谓关联性算法,一句话就能表述其核心思想:无非就是从一堆东西里面哪几个经常结对出现来判断其关联强弱。
这个道理太简单了。想想啊,这是当年高中班主任抓早恋用的算法啊,看班里哪两个经常腻歪在一起,一拿一个准!所以咩叔经常说,别整天以为会念个阿尔法贝塔就牛逼了,道在屎溺,算法往往只是生活中办法的归纳而已。
接下去正式扯算法。为免少侠关浏览器,我们展开想象的翅膀,假设一个场景:咩叔去东京加勒比(胡乱杜撰的啊)大学留学,他的导师伊库教授(日本人的名字好奇怪)要他使用关联算法,从与咩叔一起结伴做作业的行为上分析一下班上哪几位女同学之间有关联性(日本人的研究也好奇怪)。
在开始分析之前,教授说道:“咩桑,我们日本人在研究方面是很认真的,我们要先定义好专业名词。”
好的好的,咩桑明白日本人很专业,所以让我们开始关联性研究中的名词定义:
项(Item):指具体的一项事物。比如班级里的波多酱,小泽酱,樱井酱,都是项。
项集(itemset):项的集合,由n(n>=1)个项组成的一个整体,由k个项组成的项集叫k项集。比如 {波多酱,小泽酱}就是一个2项集。
事务(transaction):一个事务可以理解为发生的一次事件,比如一次做作业行为,用符号T表示。一般来说,T包含唯一的事务ID以及一个项集。若干个T构成一个数据挖掘样本库,用符号D表示。
关联规则(Association Rule):实体之间的相关关系,用A⇒B表示A和B之间存在相关关系(A、B可以是项或项集)。比如 波多酱⇒冲田酱 表示这两位同学存在关系(关系就关系了,为什么要用 ⇒ 呢?看下去就明白了)。
关联规则包含支持度(support)和置信度(confidence)两个指标。
先说支持度。支持度分两种:绝对以及相对支持度。
绝对支持度:又称支持度计数,指一个实体出现的次数,support(A) = A在全体事务数据库D中出现的次数。比方说,咩叔与同学们做作业的总次数是10次,泷泽酱出现了2次,那么泷泽酱的绝对支持度就是2。
相对支持度:所有事务中,A和B同时出现的次数与总事务数的比例,称为“相对支持度”。公式为:support(A∪B)=P(A∪B) 其中,P(A∪B)即事务中同时包含A和B的比例。比方说咩叔一共和同学做作业的次数是10次,其中与小泽酱和冲田酱一起作业的次数是8次,那么这一对的相对支持度是0.8。
(这里暂停,回想国内抓早恋的场景:在班主任的“抓早恋算法”中,只需要相对支持度就够了,瞅着指标高的那一对抓。这个算法简单粗暴但是直接有效,给无数少男少女留下不可磨灭的心理阴影,真是好讨厌好讨厌啊。)
恩,让我们从残酷青春的回忆中回到现实,继续讨论算法。
如果仅仅按“同时出现的比例“,也确实是能找到有关联性的项集的,这个没错。但是我们更深入一下,就会发现,关系之间也是有”方向“的。咩叔打个比方:
有一天叔想起曾经的班主任,就去google搜索了一下“陈老师“,结果出来这个奇怪的结果

奇怪,为什么“陈老师“和”硬盘“之间存在关联性?
带着这个疑问,叔又搜索了一下“硬盘“

唷,这回没有“陈老师“。
虽然至今咩叔也不知道为何这个结果如此奇怪,但是这个例子告诉我们,事物的关联之间是有方向的(现在知道为什么用 ⇒ 号了吧)。我们要搞清楚是“在买尿布的时候顺带买了啤酒“还是”在买啤酒的时候顺带买了尿布“。所以我们需要引入另一个指标:置信度。
置信度(confidence):A⇒B的置信度指在包含A的事务中,同时也包含B的事务所占的比例。用公式为:confidence(A⇒B)=P(B|A)=support(A∪B)/support(A)。
我们用这个公式看看在“陈老师“与”硬盘“之间谁起了”联想主导“作用。
以下是在google上查找各关键词的结果:
硬盘 约66,900,000 条结果
陈老师 约5,220,000 条结果
陈老师硬盘 约4,580,000 条结果
计算一下陈老师、硬盘之间的置信度:
Confidence(陈老师⇒硬盘)=4580000/5220000=0.877
Confidence(硬盘⇒陈老师)=4580000/66900000=0.068
很明显的是,在陈老师与硬盘的发散联想中,陈老师起了主导作用。
嗯,以上是一些专业名词的说明与解释。通过这些简单的解释,我们可以明白,在关联算法中:
1、相对支持度表示几个货经常一起出现的比例,越高则说明关系越强。
2、置信度说明经常出现在一起的货中谁是带头大哥。
关联性算法的目的,就是找出相对支持度(support)和置信度(confidence)满足预定义的最小支持度阈值(min_sup)和最小置信度阈值(min_conf)的项集。我们称这些项集之间存在“强规则”。而存在“强规则”的项集,必然是频繁在事务中出现的项集,该项集出现的次数满足最小支持度计数阈值。
所以,“找出所有频繁项集”是关联规则挖掘中最重要也是开销最大的一步。
接下去我们看一下经典的Apriori算法如何解决问题。
Apriori中文意义是“先验的、演绎的、推测的”,其核心思想归纳下来是:
任何频繁K项集都由频繁K−1项集组合而成,频繁K项集的所有K−1项子集一定都是频繁K−1项集。

Emmm,好吧好吧,咩叔只是装一下而已。我们用以下例子说明:
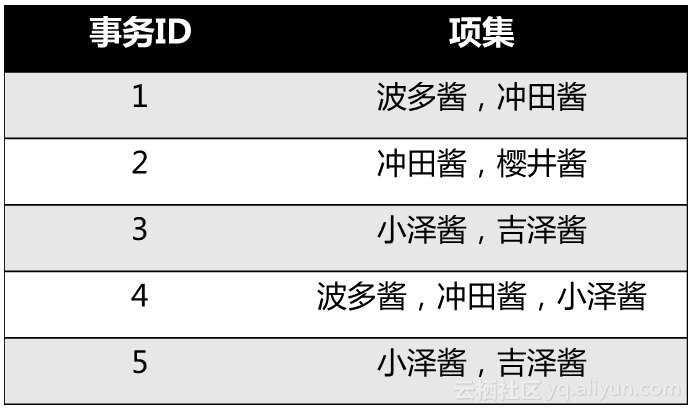
假设咩叔和同学做作业的数据如下:
设最小支持度阈值min_sup=0.4
设最小置信度阈值min_conf=0.7
Apriori计算步骤如下:
1、把所有事务中出现的同学每一个人都作为一个1项集,组成一个集合,记为C1。这里 C1 = {波多酱, 冲田酱, 小泽酱, 樱井酱, 吉泽酱}
我们列一下表统计一下每位同学的出现次数
| 同学 |
波多酱 |
冲田酱 |
小泽酱 |
樱井酱 |
吉泽酱 |
| 出现次数 |
2 |
3 |
3 |
1 |
2 |
2、将C1中各1项集与最小支持度计数阈值min_sup比较,筛除小于min_sup的项集,剩下频繁1项集组成的集合记为L1。
因为min_sup=0.4,则根据统计,樱井酱只出现了一次,占总事务比例为1/5=0.2,惨遭淘汰。此时的 L1={波多酱,冲田酱,小泽酱,吉泽酱}
3、接下去我们尝试根据L1生成C2。顾名思义,C2是由2项集组成的集合。
C2的生成就比较费脑了,需要经过连接、筛选才能完成。
我们先看如何连接。所谓连接,就是用两个频繁K−1项集,组成一个K项集,分为两步:
判断两个频繁K−1项集是否可连接。所谓可连接,指的是对于两个频繁K−1项集L1,L2,先对项集中的项进行排序(如字典序),若L1,L2的前K−2项都
相等则L1,L2可连接,用它们生成一个新的K项集。

哦哦,有点烧脑是吧,举例解释一下:
当K=2时,有2个1项集{A}与{B}需要连接。首先排序,额,1项集,没啥好排的。然后对比前K-2=0项是否相等,这里因为是0,所以不用比,直接连接,最终结果为2项集{A,B}。
当K=3时,有2个2项集{B,A}与{A,C}需要连接。首先排序,整理成{A,B}以及{A,C}。然后对比前K-2=1项是否相等,发现他们第一项都是A,可连接,最终结果为3项集{A,B,C}。
L1={波多酱,冲田酱,小泽酱,吉泽酱},经过连接,生成的C2={ {波多酱, 冲田酱},{[波多酱, 小泽酱},{波多酱, 吉泽酱}, {冲田酱, 小泽酱}, {冲田酱, 吉泽酱}, {小泽酱, 吉泽酱} }
注意,定理“频繁K项集的所有K−1项子集一定都是频繁K−1项集”,这时就派上了大用处。这个定理了保证用频繁K-1项集生成的K项集才“有可能”(注意,是有可能)是频繁的,算法在这一步直接排除了大量不可能的组合。
因为用频繁K-1项集生成的K项集“有可能”是频繁的,所以对K还是需要筛选的。
对C2进行统计,经过扫描数据库,统计结果如下:
| 同学 |
{波多酱, 冲田酱} |
[波多酱, 小泽酱} |
{波多酱, 吉泽酱} |
{冲田酱, 小泽酱} |
{冲田酱, 吉泽酱} |
{小泽酱, 吉泽酱} |
| 出现次数 |
2 |
1 |
0 |
1 |
0 |
2 |
去掉小于min_sup小于0.4的组合,
L2={ {波多酱, 冲田酱},{小泽酱, 吉泽酱} 。
重复执行以上步骤,用L2生成C3,再筛选C3得到L3,再用L3得到C4…直到找出的K项集CK为空集。
在样本数据中,找到L2后, L3已经是空集了。故已经找到了所有的频繁项集,
频繁项集={ {波多酱, 冲田酱},{小泽酱, 吉泽酱} }
接下去根据置信度做筛选。我们之前定义置信度=0.7,则
confidence(波多酱⇒冲田酱)= support(波多酱∪冲田酱)/support(波多酱)=2/2=1
confidence(冲田酱⇒波多酱)= support(波多酱∪冲田酱)/support(冲田酱)=2/3
confidence(小泽酱⇒吉泽酱)= support(小泽酱∪吉泽酱)/support(小泽酱)=2/3
confidence(吉泽酱⇒小泽酱)= support(小泽酱∪吉泽酱)/support(吉泽酱)=2/2=1
所以,在以上样本数据中,按照min_sup=0.4,min_conf=0.7的阈值,得到 关联项集={ {波多酱⇒冲田酱},{吉泽酱⇒小泽酱} }。
啊哈,听上去唬人的算法其实也就那么回事吧。搞定,美好的一天!

各位少侠也请休息一下补补脑子,我们一会继续。
----------------------------------分割线-------------------------------
书接上回,我们刚用Apriori算法得到了一份纯洁的同学关系,可喜可贺。不过呢,Apriori作为一个“老”算法,在性能上是有缺陷的。主要性能瓶颈有两个:
1、需要多次扫描数据集。
2、虽然算法中限制候选项集,但当数据量较大时,候选集(特别是候选2项集)仍然会非常庞大,在一些数据集较大并对时序要求较高的场景下往往需要使用并行计算才能弥补性能上的缺陷。
所以,Apriori算法由于时间和空间复杂度较大,在实际使用中往往性能低下。
韩家炜等人提出了FP-Growth算法,思路是将数据集中事务映射到一棵FP-Tree上,而后根据树找出频繁项集,构建过程只需要扫描两次数据集。
算法思路这里不再赘述,各位少侠请上度娘。

老夫这里简单描述一下步骤。
我们还是用纯洁的同学关系样本,并保持最小支持度阈值min_sup=0.4 ,最小置信度阈值min_conf=0.7
我们先来第1次纯洁的扫描,统计所有一次项的出现次数,将其降序排列
{冲田酱(3次),小泽酱(3次), 波多酱(2次),吉泽酱(2次),樱井酱(1次)}
嗯,在这里剔除可怜的樱井酱,最终得到 频繁项列表 L(列表中项按照支持度计数递减排序)
L={冲田酱(3次),小泽酱(3次), 波多酱(2次),吉泽酱(2次)}
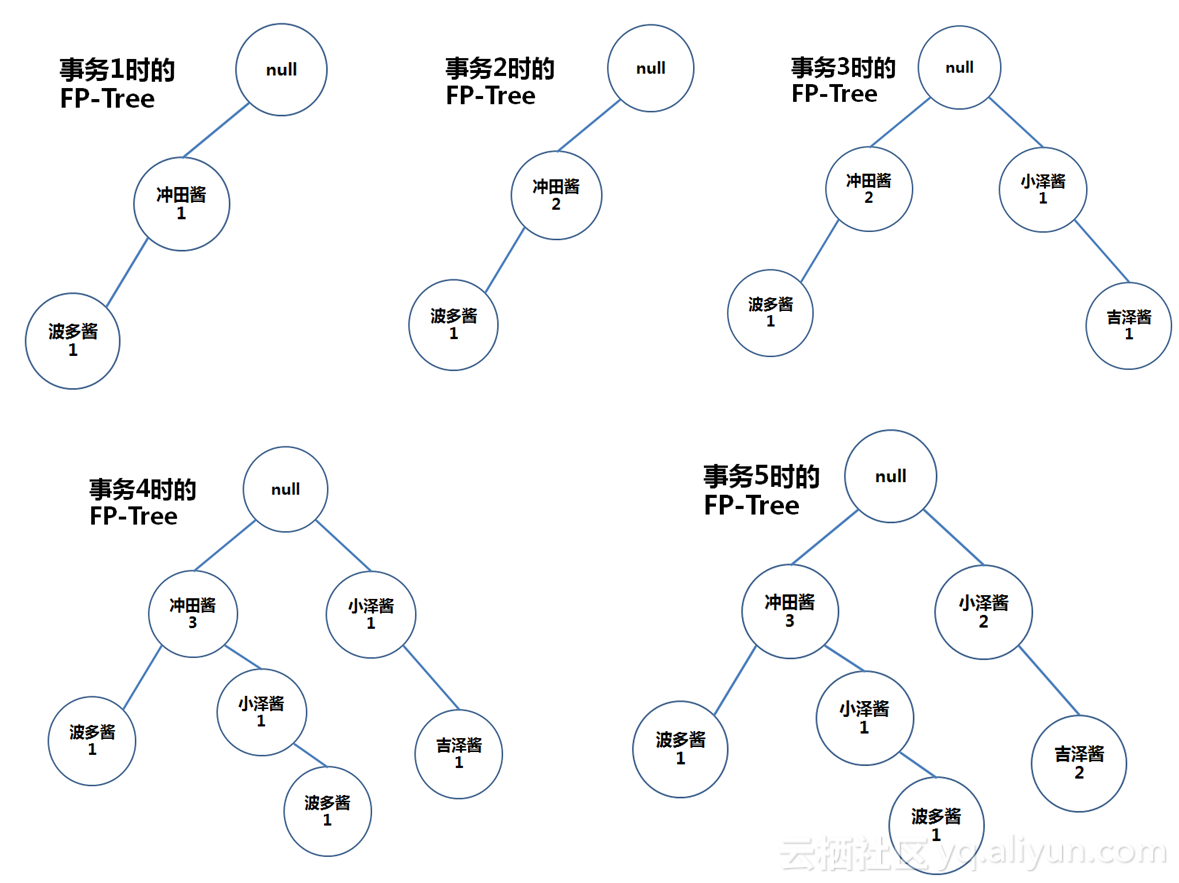
构建初始根节点为null的FP树,而后进行第2次扫描,从数据库中逐一取出事务,按照 L 排序,把每个项逐个添加到FP-Tree的分枝上去。
啊啊,说人话说人话,以下解释:
事务1排序后为{冲田酱, 波多酱},在根节点上加一棵子树“冲田酱-波多酱”,并设初始计数为1。
事务2中去掉已经被淘汰的樱井酱,得到排序后的项集{冲田酱},发现树中已经有“冲田酱“节点,嗯,这时候我们直接在“冲田酱“节点计数器上+1
事务3排序后得到{小泽酱,吉泽酱},这两个节点是原先树中没有的,所以我们在root后加上新的两个节点
事务4排序后得到{冲田酱,小泽酱,波多酱},我们发现头部数据“冲田酱”能与现有树中节点共用,则在树中“冲田酱”节点上+1,而后在其后面加上子节点 “小泽酱-波多酱”
事务5排序后得到{小泽酱, 吉泽酱},这两个节点树中已有,直接计数器+1
步骤流程如图:
那么接下去,我们尝试寻找“波多酱”的好姐妹。
1、首先需要找出 以根节点为头,以波多酱为结尾之间的所有路径。我们找到两条路径,分别是
{null,冲田酱(3),波多酱(1)}
{null,冲田酱(3),小泽酱(1),波多酱(1)}
2、其次掐头去尾,去掉根节点以及波多酱本身,得到以下两个项集
{冲田酱(3)}
{冲田酱(3),小泽酱(1)}
3、而后用波多酱的计数器作为项集计数器
{冲田酱}:1 (因为此路径结尾处波多酱计数器=1)
{冲田酱,小泽酱}:1 (因为此路径结尾处波多酱计数器=1)
而后,对以上2个项集建立FP-Tree:
先算 L={冲田酱(2次),小泽酱(1次,淘汰)},再用L得到FP-Tree:
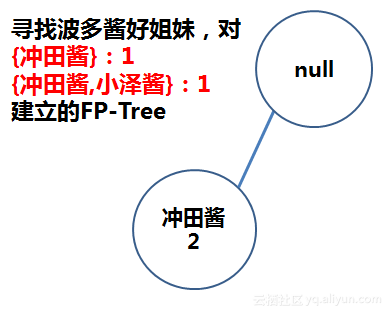
不断重复以上步骤,直到空集为止。在这个例子中,已经找到波多酱的好姐妹{冲田酱(2)},她与波多酱同时出现了2次。
从以上步骤可以看出,由于FP-Growth算法只需要对数据全集做两次扫描,(第一次统计1项集次数,第二次建立初始的FP-TREE),故在算法性能上优于Apriori。
对Apriori和FP-Growth两种算法进行分析,会发现它们都有一个问题,只能做离线计算,不能做在线计算。原因在于:
1、这两种算法都需要对数据进行全扫描以完成裁剪或排序。
2、因为每次计算都需要全集扫描,所以随着数据增长,计算会越来越慢…
在一个数据不断流入的场景下,以上两个算法是没有办法实时计算出事物关联的。
实时性有多重要呢?想想看,领导来视察,问你最近下雨天流行什么配什么:
你指着大屏幕:“哥,看这儿,大数据实时分析的。你看你看,会动哦”。
VS
你挠着头:“领导等两小时我给你算算”
请问哪种更Bigger?

为了少侠们更Bigger,老夫要在此献丑一下,介绍一个当初憋了好几天想出的算法:“图权重算法“,可以实现在线实时从访问日志中流式抽取数据计算关联关系(啊,好绕口,但是感觉瞬间Bigger了有没有?)。

这个算法建立在离散数学中的图论上面。但是很显然,咩叔如此清新脱俗的人物肯定不讲离散数学(又不是写论文,坚决不讲那一大堆理论)。
我们还是讲纯洁的同学关系。
有少侠发现没有,在介绍FP-Growth算法的时候,我们把这张二维表中的数据处理成了这个样子:
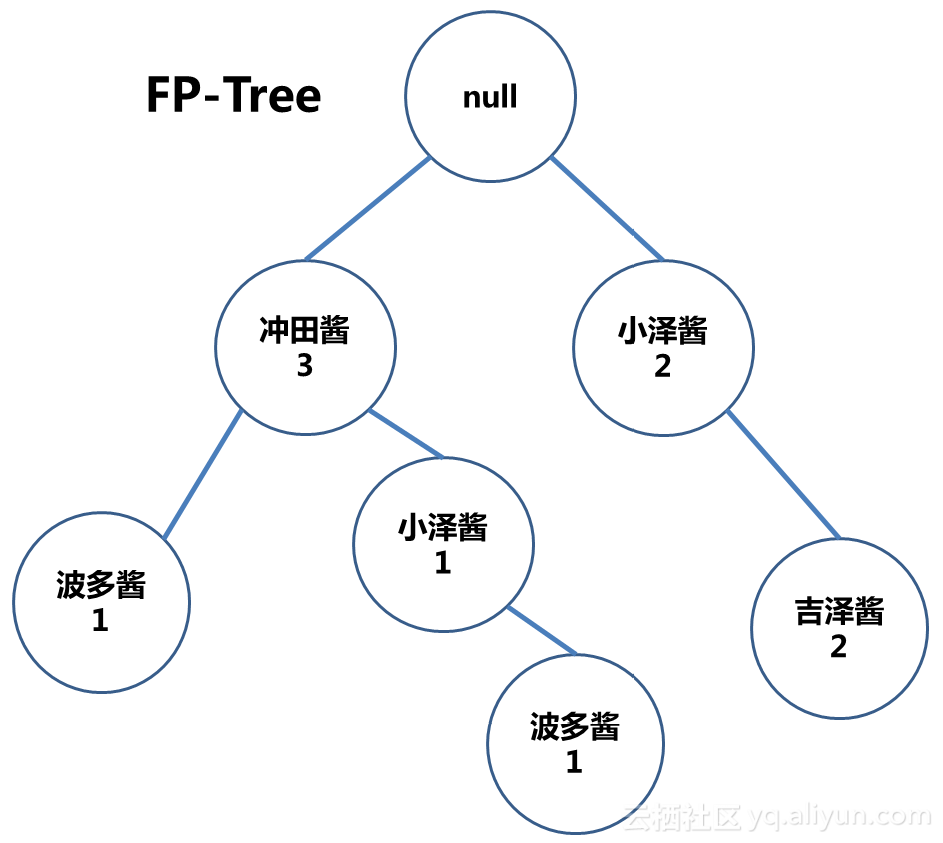
这种形态是不是比二维表更容易让人理解?
但是PF-Tree的形态对人不是最友好。看看,“波多酱“出现了两个节点,假如树上节点一多,岂不是要把人看精分了。
所以,我们要把“树“变成”图“。看老夫施法:
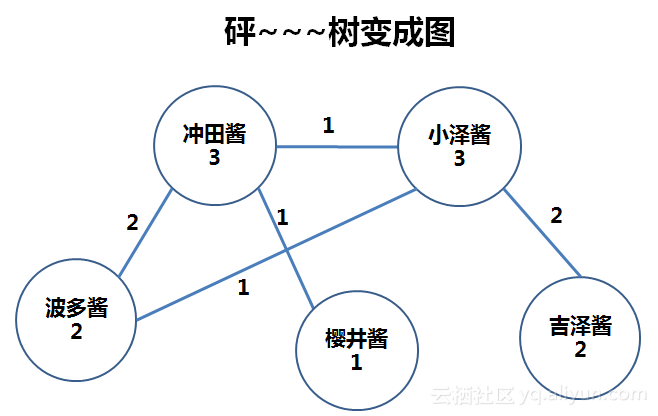
“树”变成了“图”,有何不同?仔细看看:
首先,原先树中分裂了的“波多酱”和“小泽酱”恢复了,在图中,一个项就是一个节点。当然,每一个节点的计数器也恢复了,体现了这个节点真正的绝对支持度计数。
其次,节点间的线多了,“小泽酱”节点引出了三条线——这是实际数据的体现,在数据样本中,小泽酱就是和另外三个女同学有关联。
最后,节点间的线上有了数字,比如“波多酱”和“冲田酱”之间的线上,数字为2,说明波多酱与冲田酱同时出现了2次。
简言之,在“图”中,真实的体现了项之间的关系。
同样的条件:最小支持度min_sup=0.4 最小置信度min_conf=0.7
让我们试试从这张图中找出“波多酱”的好姐妹。
1、波多酱本身的绝对支持度=2,通过验证。
2、从波多酱引出两条线,分别是
波多酱——冲田酱
波多酱——小泽酱
我们首先验证冲田酱与小泽酱本身的支持度是否通过min_sup验证。啊,耀西!通过。
再看她们之间的关系是否通过min_sup验证。嗯,遗憾遗憾,波多与小泽之间那根线只有弱弱的1,少女的羁绊不够哦。
此轮验证后只剩下 波多酱——冲田酱
你看,从“图”中找关联是不是很方便,而且是不是更符合“人”的认知习惯呢?
这里多说几句:事实上,这几年社交网络的发展,也大量使用了“图论”的知识。图的以下特征:
1、图含节点与边;
2、节点中可以有属性(比如上图的支持度计数器);
3、边可以有名字与方向,并可以有属性(比如上图中同时出现次数)。
可以轻松衍生出各种“关系”,不仅是社交网络,从道路系统到电路节点,从供应链到组织结构,甚至更多。有兴趣的少侠可以深入研究,很有趣哦。
好了,事前准备做完,接下去说说“图权重算法”怎么玩了。
有几个重要思路要说明:
1、关于流式数据的问题。之前举例的数据样本是这样的:
其实这份数据不是原始数据,已经经过处理归纳。在真实的在线环境中,你不会知道一个事务(比如用户的商品浏览行为)何时结束,所以根本无法基于全数据集做统计。在线环境中,我们的数据结构是这样的:
| 日志流水号 |
事务ID |
项 |
| 1 |
1 |
波多酱 |
| 2 |
2 |
冲田酱 |
| 3 |
1 |
冲田酱 |
| 4 |
3 |
小泽酱 |
| 5 |
2 |
樱井酱 |
| 6 |
3 |
吉泽酱 |
| 7 |
4 |
波多酱 |
| 8 |
4 |
冲田酱 |
| 9 |
4 |
小泽酱 |
| 10 |
5 |
小泽酱 |
| 11 |
5 |
吉泽酱 |
| … |
… |
… |
解释一下这个数据结构:
1、数据是实时不断流入的,根本不知道一个事务何时完成,原先经过汇总的 事务1={波多酱,冲田酱} 这种形式根本不存在。在流式数据中,每一条记录中只包含事务中的一个项。
2、从表中数据排列也能看出来,现实中数据是多并发,不断流入的,所以不存在“一个会话中的项都排在一起”的情况,数据是打乱无序的。
我们要在这些不断流入,无序的数据中实时计算出关联规则,所以算法天生就必须做到“不对数据集做任何 统计、裁剪、排序 操作”。

Mission impossible?不会的啦。事实上整个算法秉承了咩叔一贯的“简单粗暴,直接有效”风格,简单的不可思议呦,少侠。
接下去我们继续用一个示例说明。
啊,等一下!在与美少女一起做作业前,难道不需要准备一些必备的东西么,你懂的,对吧!

所以,我们要准备两个数据结构,你肯定也想到了,是吧,你想的果然也是数据结构,是吧少侠?
我们要准备的两个数据结构,一个是图,另一个是一张HashMap表。
图不用多说,我们的算法就是基于图的。
HashMap表用来做甚?做键值对存储。<key=事务ID , Value=事务中项集合>,比如 <key=1,Value={波多酱,冲田酱}>。
准备以上好两个数据结构后,说明一下数据处理流程。
数据如流水,一去不回头啊…啊,扯远了扯远了。数据是一行行传入的,每一行数据传入为一次处理流程。
假设传入数据为:事务ID=TX,项=IX 处理流程步骤为:
1、首先在HashMap表中检查,是否有key=TX 的键值对存在:
若不存在,则建立键值对 <key=TX,Value={IX}>,转入步骤2;
若存在,则检查IX是否已经包含在Value中项集合内。若是,则此次处理流程结束。若否,转入步骤2。
(注意:这里“检查IX包含在项集合中后即退出”,其用意在于“一个事务中同样的项不管出现多少次,都只做一次计算”。想想看,一个用户对一个商品疯狂点赞,难道说明所有人都喜欢这个商品?)
2、判断项IX是否已经在图中存在节点:
若不存在,则直接在图中创建IX节点,并设“支持度属性值”=1,此次处理流程结束。
若存在,则设置节点IX“支持度属性值”+1,进入步骤3
3、在图中,节点IX需要与事务TX项集中其他项对应的节点分别进行关系判断,看是否已经建立了边连接。假设TX中已有项IY,则需要在图中判断IX节点是否与IY节点之间已经建立边:
若尚未建立边,则建立之,并设边的“同时出现属性值“=1,转入步骤4。
若已经建立边,则设边的“同时出现属性值”+1,转入步骤4。
4、将IX加入HashMap中key=TX的项集合中去。
嗯,以上步骤400字,还是加了很多解释的。当年咩叔论文中阿尔法贝塔的,才用了200字,简单吧,哦呵呵呵。

明白明白,老夫没忍住…少侠请收起铁拳,我们说人话。
恩啊,让我们一步一步一步的分析和美少女做作业的纯洁行为吧…

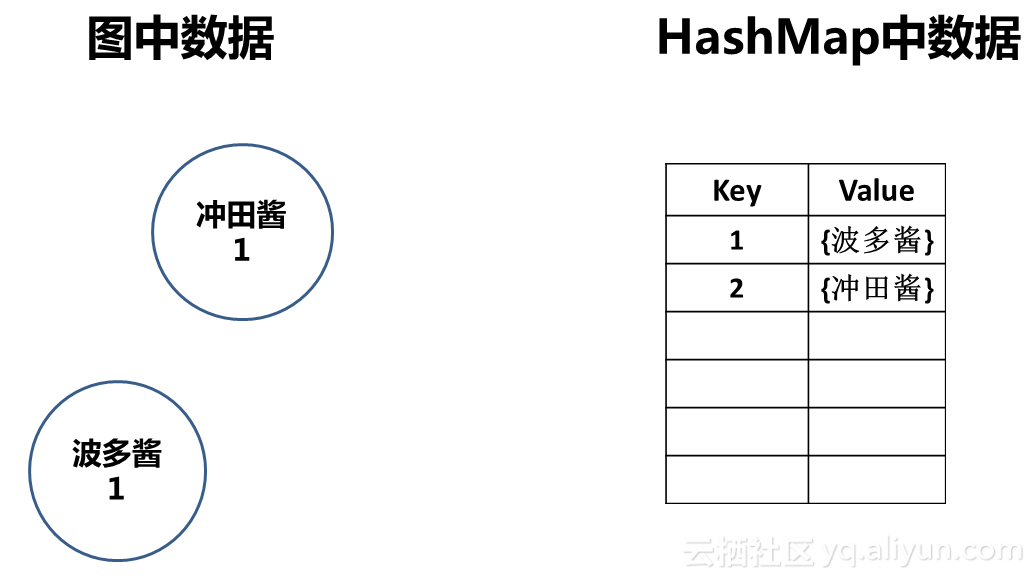
日志1 数据:事务ID=1,项=波多酱
处理流程如下:
步骤1
首先我们检查HashMap,是否存在Key=1的键值对。
哦,没有。所以我们建立一个<key=1,Value={波多酱}>,而后转入步骤2
步骤2
图中没有“波多酱”节点,所以直接在图中建立“波多酱”节点,并将“支持度“属性值设置为1。
流程处理结束。
--------------------------------------------------------------------------
日志2 数据:事务ID=2,项=冲田酱
处理步骤与日志1毛一样,不罗嗦了。
--------------------------------------------------------------------------
日志1、2处理完毕后,数据结构中内容如下:
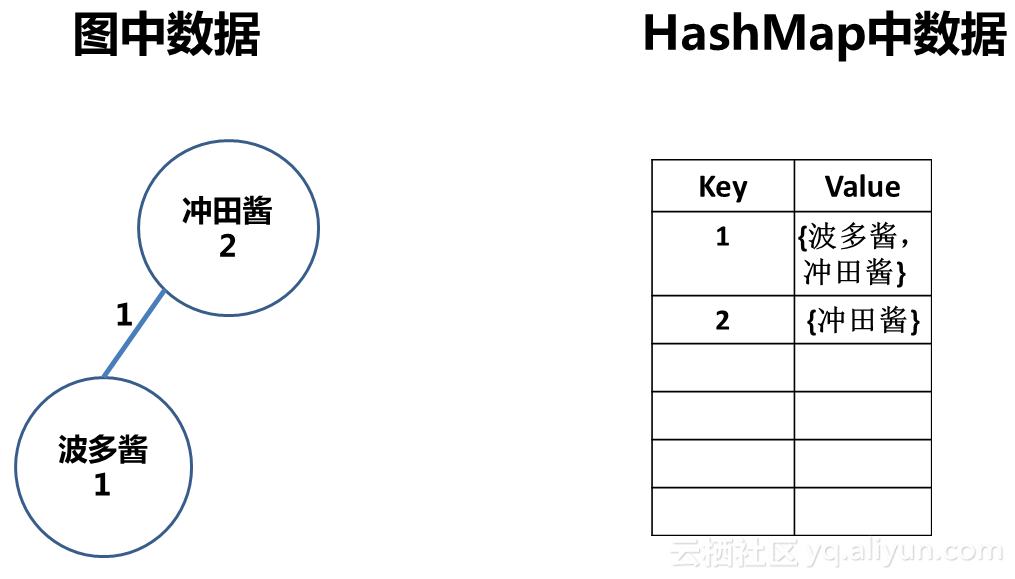
日志3 数据:事务ID=1,项=冲田酱
步骤1
发现已经有key=1的键值对,但是项集合中没有”冲田酱”,所以我们要转入步骤2。
步骤2
发现图中已经存在“冲田酱”节点,所以将其“支持度“属性值设置+1,进入步骤3。
步骤3
发现事务1项集中已经存在“波多酱”项,同一事务中的姐妹要有羁绊哦!所以我们在图中的“波多酱”和“冲田酱”节点之间建立了一条边,并设这条边的“同时出现“属性值为1,转入步骤4。
步骤4
将“波多酱“加入事务1的项集中,此时键值为<key=1,Value={波多酱,冲田酱}>,流程处理结束。
--------------------------------------------------------------------------
日志3处理完毕后,数据结构中内容如下:
进行到这一步,少侠们想必已经明白处理步骤了吧。老夫就不堆字了。少侠请自行尝试一番。最终结果应该是这样:
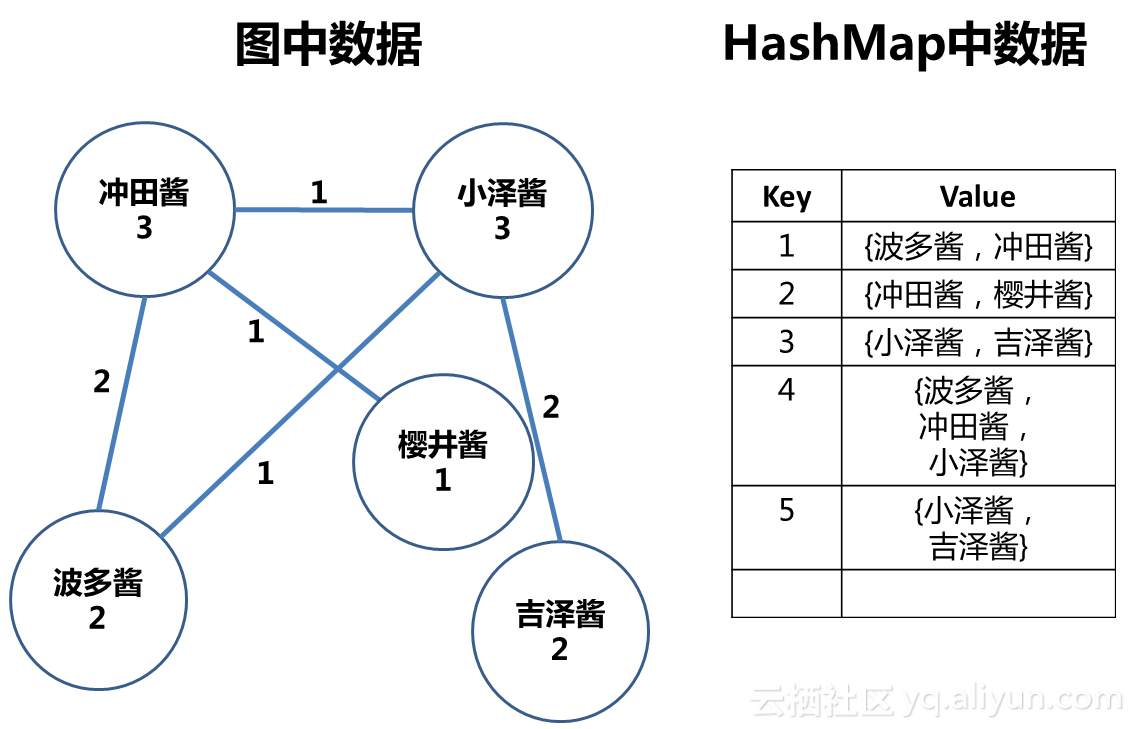
各位少侠请看,在这个算法中,果然没有全局扫描,也没有统计和排序吧。相比它的两位前辈,可以说在运算资源上是轻量级的,非常适合做在线计算。
以上仅仅是介绍了算法的基本思路和步骤。如果有少侠感兴趣想试试,有几个建议:
一、算法中两处关键点的实现:
1、传入一个项时需在HashMap中判断是否已在事务中出现过
建议用键值对数据库,比如Redis实现。当然直接用Java等高级语言自带的HashMap也无不可,但Redis的优势在于数据可以持久化,可以有效避免在系统重启后对历史数据再做一次全加载。
2、需要判断项是否在图中存在节点,节点间是否有边,以及从某一个节点出发寻找边“同时出现”属性大于阈值的相关节点等图操作。
可以使用图数据库Neo4j解决。这个产品是专门应对图论而开发的,对各种“图”相关的操作十分简单,并且建立了类似SQL语言的Cypher语言操作数据,学习成本很低。
二、算法存在缺点以及应对方式:
1、假如存在大量频繁度很低的项,就会在图中生成大量没啥毛用的节点;
2、一次事务中有K项,则在图中K个节点间需要建立K(K-1)/2条边,K值大的时候,想想蜘蛛网吧;
3、算法中数据处理是串行的,一旦大量日志涌入,性能瓶颈就将出现。
这些缺陷可以在实际处理中这样灵活避免:
1、实际生活中,大多数事务中不会包含太多项(包含大量项的一般是爬虫哦少侠),所以可以设置一个阈值,一个事务最多存储K个项,多余的丢弃。
2、对图中节点定时做清理,去掉一些长期不动的无价值低频繁度项,去掉相对支持度太低的边。
3、在日志流传入的时候做一些控制,限制每秒处理数量,防止把图处理服务给累死。
声明:为避免神圣的论文抽检系统找我麻烦,在此说明,此博文作者与复旦大学16222010099学生为同一人,“图权重算法”为作者原创,不管论文还是博文均无抄袭行为。