
Blink任务核心结构
一个完整的Blink任务主要有三部分组成:
-
数据源(INPUT) - Blink外部数据源表
-
业务逻辑(QUERY) - Blink内部处理逻辑
-
结果表(OUTPUT),如下:Blink外部结果表

Blink如何描述INPUT和OUTPUT的数据结构
在一个Blink任务中 INPUT和OUTPUT都是Blink之外的外部存储系统,Blink要处理INPUT的数据必须要清楚的知道INPUT的数据格式,同时处理之后的数据要持久化到外部OUTPUT存储系统里面,也要知道写出的数据结构,那么Blink如果定义这些数据格式呢?Blink采取了传统数据库的做法,利用ANSI-SQL的DML定义INPUT和OUTPUT,在Blink内部采用ROW(行)数据结构进行数据流转,利用DML进行数据处理逻辑的表达。Blink内部的ROW(行)由一个或多个数据列组成,说道这里,大家很自然的想到了数据库的表了吧?哈哈,没错,Blink就是提供ANSI-SQL的支持,用户编写SQL就可以轻松的完成自己的流计算任务开发!
说了这么一串,不废话了,Blink既然支持用写SQL,势必要和传统数据库一样,拥有定义表的数据类型,没错,Blink SQL 遵守ANSI-SQL规范,目前Blink对ANSI-SQL中基础数据类型都有很好的支持,本篇将目前Blink所支持的所有数据类型进行说明,并对特殊的浮点类型进行深入说明。
ANSI-SQL和Blink-SQL数据类型
|
数据类型
|
说明
|
|
|
Blink-SQL
|
||
|
BOOLEAN(99)
|
BOOLEAN
|
逻辑值 [TRUE|FALSE]
|
|
BIT VARYING
|
TINYINT
|
1字节微整型 [-128, 127]
|
|
SMALLINT
|
SMALLINT
|
2字节短整型 [-32768, 32767]
|
|
INTEGER
|
INT
|
4字节整数 [-2147483648, 2147483647]
|
|
NUMBER
|
BIGINT
|
8字节长整型 [-9223372036854775808, 9223372036854775807]
|
|
FLOAT
|
FLOAT
|
4字节浮点型,7-8位小数位
|
|
DOUBLE PRECISION
|
DOUBLE
|
8字节浮点型,16-17位小数位
|
|
DECIMAL
|
DECIMAL
|
8或16字节小数型,0~38位小数位
|
|
DATE
|
DATE
|
日期类型
|
|
TIME
|
TIME
|
时间类型
|
|
TIMESTAMP
|
TIMESTAMP
|
时间戳(DATE+TIME)
|
|
CHARACTER,
CHARACTER VARYING
|
VARCHAR
|
变长字符类型
|
|
BIT, BIT VARYING
|
VARBINARY
|
变长二进制类型
|
|
-
|
ANY
|
对象类型
|
|
说明:ANSI-SQL 数据类型默认是SQL-92类型,99和2003标准类型添加了下标.
|
||
float double decimal 区别
要介绍浮点数必须先了解一下
IEEE754, IEEE(全称是Institute of Electrical and Electronics Engineers)中文名是电气和电子工程师协会,是一个国际性的电子技术与信息科学工程师的协会,是目前全球最大的非盈利专业技术学会。
IEEE754
标准是IEEE二进位浮点数算术标准(IEEE Standard for Floating-Point Arithmetic)的标准编号,等同于国际标准
ISO/IEC/IEEE 60559。
IEEE754 规范定义了两种浮点数格式:
-
float - 32位单精度
-
double - 64位双精度
IEEE754 规范定义任何一个浮点数都可以由如下方式表达:
|
V = (-1)^s * 2^E * M
|
||
|
^s
|
表示符号位,当s=0,V为正数;当s=1,V为负数。
|
|
|
M
|
M表示有效数字, 1≤M<2,也就是说,M可以写成1.xyz的形式,其中xyz表示小数部分。IEEE 754规定,在计算机内部保存M时,默认这个数的第一位总是1,因此可以被舍去,只保存后面的xyz部分。比如保存1.01的时候,只保存01,等到读取的时候,再把第一位的1加上去。这样做的目的,是节省1位有效数字。以32位浮点数为例,留给M只有23位,将第一位的1舍去以后,等于可以保存24位有效数字。
|
|
|
2^E
|
表示指数位, E为一个无符号整数(unsignedint)这意味着,如果E为8位,它的取值范围为0~255;如果E为11位,它的取值范围为0~2047。但是,我们知道,科学计数法中的E是可以出现负数的,所以IEEE 754规定,E的真实值必须再减去一个中间数,对于8位的E,这个中间数是127;对于11位的E,这个中间数是1023,其实就是上面的E=f(e)。
比如:2^10的E是10,所以保存成32位浮点数时,必须保存成10+127=137,即10001001。读取时候在2^E =2^(e-127)=2^(137-127) = 2^10。
分情况说明:
|
|
|
示例1
|
十进制的5.0,写成二进制是101.0,相当于1.01×2^2。那么,按照上面V的格式,可以得出s=0,M=1.01,E=2。 十进制的-5.0,写成二进制是-101.0,相当于-1.01×2^2。那么,s=1,M=1.01,E=2。
|
|
那么单精度和双精度浮点在计算机内部长度和表示格式如下:
|
精度类型
|
长度(bit)
|
符号位s(sign)
|
指数位e(exponent)
|
尾数位f(fraction)
|
E=f(e)
|
|
float 单精度
|
32
|
1
|
8
|
23
|
e-127
|
|
double 双精度
|
64
|
1
|
11
|
52
|
e-1023
|
所谓精度指数字的位数, 小数位数指小数点后的数字位数。 例如: 123.45 的精度是5,小数位数是2。 float double 和 decimal的主要区别在于数据的精度.
-
单精度 Floatfloat是单精度数据类型,一般在计算机中存储占用4字节,即32位,有效位数为6位(不含小数点),存储结构是1位符号,8位指数,23位小数,23位,除去全部为0的情况以外,最小为2的-23次方Math.pow(2,-23) = 1.1920928955078125E-7, 约等于1.19乘以10的-7次方,即有效数字为7位。具体如下图:
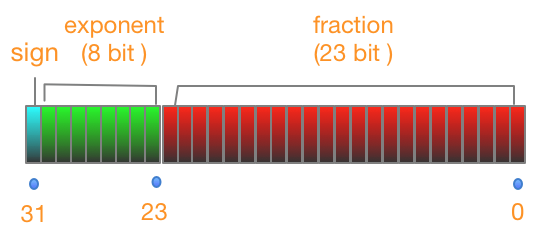
-
双精度double是双精度数据类型,一般在计算机中存储占用8字节,即64位,有效位是15位(不含小数点),存储结构是1位符号,11位指数,52位小数,除去全部为0的情况以外,最小为2的-52次方,Math.pow(2,-52) = 2.220446049250313E-16,约为2.22乘以10的-16次方,有效位数为16位,具体如下图:
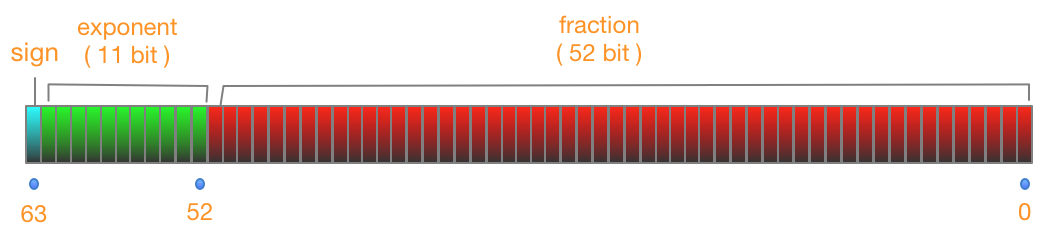
再说丢失精度
目前我们了解了浮点型在计算机内部的标识方式,很明显浮点型有丢失精度的可能,以示例说明:
CREATE TABLE helloWord_source(
col_int INTEGER
)WITH(
type='random'
) ;
CREATE TABLE helloWord_sink(
col_float FLOAT,
col_double DOUBLE
)WITH(
type = 'print'
) ;
INSERT INTO helloWord_sink
SELECT
cast(0.123456789*2 as FLOAT), // 0.2469136 7位
cast(0.123456789123456789 * 2 as DOUBLE) // 0.24691357824691357 //17位
FROM helloWord_source;
输出结果:
克隆
拷贝锚点
编辑锚点
删除
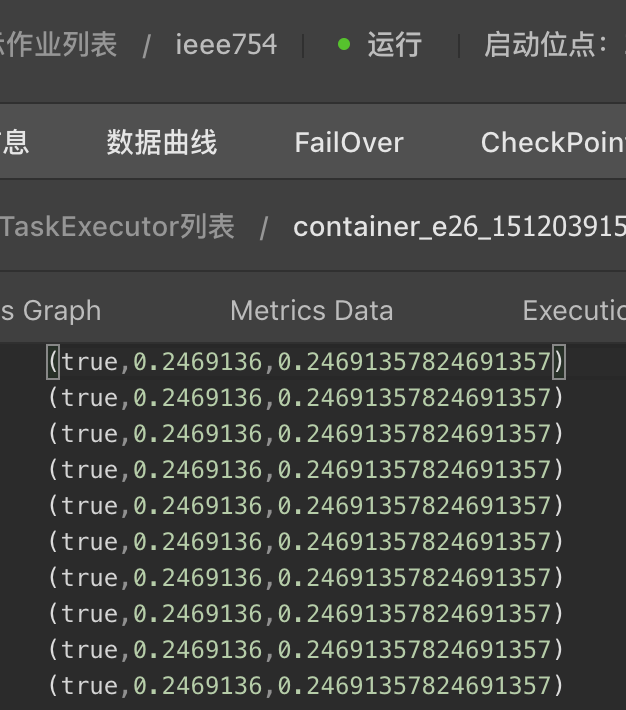
如上结果说明在Blink中 float中有7位有效位,double有17位有效位,decimal可以定义精度, 那么decimal在Blink中如何存储的呢?
-
更高精度 Decimal
decimal 数据类型最多可以存储 38 个数字,所有这些数字均可位于小数点后面。decimal 数据类型存储精确的数字表示形式,定义 decimal 有两种属性:
-
p - 指定精度
-
s - 指定可以放在小数点右边的小数位数
其中 p和s 必须遵守规则: 0<=s<=p<=38. 当 p<=19时候用8字节存储,当p>19时候用16字节存储。
小结
本篇概要介绍了Blink支持的数据类型,同时对比较特殊的float,double和decimal类型做了进一步的说明。更多关于Blink数据类型的认知,可以在后面的篇章中逐渐深入了解。




