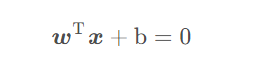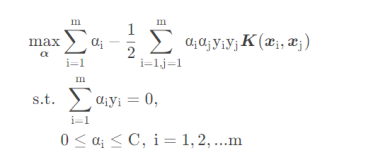在前面SVM我们讲到了线性可分SVM的硬间隔最大化和软间隔最大化的算法,它们对线性可分的数据有很好的处理,但是对完全线性不可分的数据没有办法。本文我们就来探讨SVM如何处理线性不可分的数据,重点讲述核函数在SVM中处理线性不可分数据的作用。
1. 回顾多项式回归
比如一个只有两个特征的p次方多项式回归的模型:
$$ h_\theta(x_1, x_2) = \theta_0 + \theta_{1}x_1 + \theta_{2}x_{2} + \theta_{3}x_1^{2} + \theta_{4}x_2^{2} + \theta_{5}x_{1}x_2 $$
我们令$x_0 = 1, x_1 = x_1, x_2 = x_2, x_3 =x_1^{2}, x_4 = x_2^{2}, x_5 = x_{1}x_2$ ,这样我们就得到了下式:
$$ h_\theta(x_1, x_2) = \theta_0 + \theta_{1}x_1 + \theta_{2}x_{2} + \theta_{3}x_3 + \theta_{4}x_4 + \theta_{5}x_5 $$
可以发现,我们又重新回到了线性回归,这是一个五元线性回归,可以用线性回归的方法来完成算法。对于每个二元样本特征$(x_1,x_2)$ ,我们得到一个五元样本特征$(1, x_1, x_2, x_{1}^2, x_{2}^2, x_{1}x_2)$,通过这个改进的五元样本特征,我们重新把不是线性回归的函数变回线性回归。
也就是说,对于二维的不是线性的数据,我们将其映射到了五维以后,就变成了线性的数据。
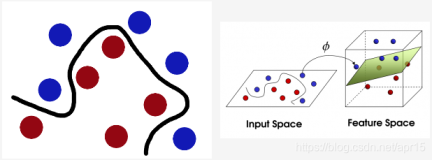
这给了我们启发,也就是说对于在低维线性不可分的数据,在映射到了高维以后,就变成线性可分的了。这个思想我们同样可以运用到SVM的线性不可分数据上。也就是说,对于SVM线性不可分的低维特征数据,我们可以将其映射到高维,就能线性可分,此时就可以运用前两篇的线性可分SVM的算法思想了。
2. 核函数的引入
上一节我们讲到线性不可分的低维特征数据,我们可以将其映射到高维,就能线性可分。现在我们将它运用到我们的SVM的算法上。回顾线性可分SVM的优化目标函数:
$$ \underbrace{ min }_{\alpha} \frac{1}{2}\sum\limits_{i=1,j=1}^{m}\alpha_i\alpha_jy_iy_jx_i \bullet x_j - \sum\limits_{i=1}^{m}\alpha_i \\ s.t. \; \sum\limits_{i=1}^{m}\alpha_iy_i = 0 \\ 0 \leq \alpha_i \leq C $$
注意到上式低维特征仅仅以内积$x_i \bullet x_j$的形式出现,如果我们定义一个低维特征空间到高维特征空间的映射$ϕ$(比如上一节2维到5维的映射),将所有特征映射到一个更高的维度,让数据线性可分,我们就可以继续按前两篇的方法来优化目标函数,求出分离超平面和分类决策函数了。也就是说现在的SVM的优化目标函数变成:
$$ \underbrace{ min }_{\alpha} \frac{1}{2}\sum\limits_{i=1,j=1}^{m}\alpha_i\alpha_jy_iy_j\phi(x_i) \bullet \phi(x_j) - \sum\limits_{i=1}^{m}\alpha_i \\ s.t. \; \sum\limits_{i=1}^{m}\alpha_iy_i = 0 \\ 0 \leq \alpha_i \leq C $$
可以看到,和线性可分SVM的优化目标函数的区别仅仅是将内积$x_i \bullet x_j$替换为$\phi(x_i) \bullet \phi(x_j)$。
看起来似乎这样我们就已经完美解决了线性不可分SVM的问题了,但是事实是不是这样呢?我们看看,假如是一个2维特征的数据,我们可以将其映射到5维来做特征的内积,如果原始空间是三维,可以映射到到19维空间,似乎还可以处理。但是如果我们的低维特征是100个维度,1000个维度呢?那么我们要将其映射到超级高的维度来计算特征的内积。这时候映射成的高维维度是爆炸性增长的,这个计算量实在是太大了,而且如果遇到无穷维的情况,就根本无从计算了。
怎么办?似乎我们刚提出了一种好的解决线性不可分的办法,接着就把自己否决了。
好吧,核函数该隆重出场了!
假设$ϕ$是一个从低维的输入空间$χ$(欧式空间的子集或者离散集合)到高维的希尔伯特空间的$H$映射。那么如果存在函数$K(x,z)$,对于任意$x,z∈χ$,都有:
$$ K(x, z) = \phi(x_i) \bullet \phi(x_j) $$
那么我们就称$K(x,z)$为核函数。
从上面的式子乍一看还是不明白核函数怎么帮我们解决线性不可分的问题的。仔细观察上式可以发现,$K(x,z)$的计算是在低维特征空间来计算的,它避免了在刚才我们提到了在高维维度空间计算内积的恐怖计算量。也就是说,我们可以好好享受在高维特征空间线性可分的红利,却避免了高维特征空间恐怖的内积计算量。
至此,我们总结下线性不可分时核函数的引入过程:
我们遇到线性不可分的样例时,常用做法是把样例特征映射到高维空间中去(如上一节的多项式回归)但是遇到线性不可分的样例,一律映射到高维空间,那么这个维度大小是会高到令人恐怖的。此时,核函数就体现出它的价值了,核函数的价值在于它虽然也是将特征进行从低维到高维的转换,但核函数好在它在低维上进行计算,而将实质上的分类效果(利用了内积)表现在了高维上,这样避免了直接在高维空间中的复杂计算,真正解决了SVM线性不可分的问题。
3. 核函数的介绍
事实上,核函数的研究非常的早,要比SVM出现早得多,当然,将它引入SVM中是最近二十多年的事情。对于从低维到高维的映射,核函数不止一个。那么什么样的函数才可以当做核函数呢?这是一个有些复杂的数学问题。这里不多介绍。由于一般我们说的核函数都是正定核函数,这里我们直说明正定核函数的充分必要条件。一个函数要想成为正定核函数,必须满足他里面任何点的集合形成的Gram矩阵是半正定的。也就是说,对于任意的$x_i in chi , i=1,2,3...m$, $K(x_i,x_j)$对应的Gram矩阵$K = \bigg[ K(x_i, x_j )\bigg]$ 是半正定矩阵,则$K(x,z)$是正定核函数。
从上面的定理看,它要求任意的集合都满足Gram矩阵半正定,所以自己去找一个核函数还是很难的,怎么办呢?还好牛人们已经帮我们找到了很多的核函数,而常用的核函数也仅仅只有那么几个。下面我们来看看常见的核函数, 选择这几个核函数介绍是因为scikit-learn中默认可选的就是下面几个核函数。
3.1 线性核函数
线性核函数(Linear Kernel)其实就是我们前两篇的线性可分SVM,表达式为:
$$ K(x, z) = x \bullet z $$
也就是说,线性可分SVM我们可以和线性不可分SVM归为一类,区别仅仅在于线性可分SVM用的是线性核函数。
3.2 多项式核函数
多项式核函数(Polynomial Kernel)是线性不可分SVM常用的核函数之一,表达式为:
$$ K(x, z) = (\gamma x \bullet z + r)^d $$
其中,$\gamma, r, d$都需要自己调参定义。
3.3 高斯核函数
高斯核函数(Gaussian Kernel),在SVM中也称为径向基核函数(Radial Basis Function,RBF),它是非线性分类SVM最主流的核函数。libsvm默认的核函数就是它。表达式为:
$$ K(x, z) = exp(-\gamma||x-z||^2) $$
其中,$γ$大于0,需要自己调参定义。
3.4 Sigmoid核函数
Sigmoid核函数(Sigmoid Kernel)也是线性不可分SVM常用的核函数之一,表达式为:
$$ K(x, z) = tanh(\gamma x \bullet z + r) $$
其中,$γ,r$都需要自己调参定义。
摘自:https://www.cnblogs.com/pinard/p/6103615.html
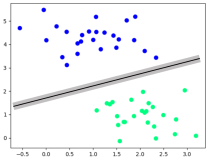
补充:关于使用核函数的一个例子: