HBase建表的基本准则
常见rowKey设计遇到的问题以及相应的解决方案
建模案例分析:电商中宝贝点击量建模示例
HBase客户端的使用
HBase优化
HBase连续分页问题查询的参考解决方案
分享的目的:
合理地使用HBase,发挥HBase本身所不具有的功能,提高HBase的执行效率
一、HBase建表的基本准则
1. family数量的控制:
不能太多,建议不要超过2个,一般的情况 下,一张表,一个family最好, 可以避免在刷缓存的时候一个Region下多个Store的相互影响,减少不必要的IO操作;
2. rowKey的设计:
- rowKey写入不能连续,尽量散开,避免写入region热点的问题, 导致regionServer负载不均衡,不能充分发挥HBase集群高并发写入的性能,极端情况下会出现regionServer宕机下线;
- 在满足业务的情况下,rowKey的长度越短越好,rowkey的长度越短,越节约内存和硬盘的存储空间;
- 设置好rowKey的分割符,多个业务字段拼接,设置好分隔符,如#, $(方便前缀范围查询, 又没有热点问题)
3. 版本数量的控制:
业务上没有特别要求的情况 下,用一个版本,即最大版本和最小版本一样,均为1;
4. 失效时间的控制:
根据具体业务的需求,合理的设置好失效时间,从节约存储空间的情况考虑,当然是在满足业务的情况下存储的时间越短越好,永久保存的情况除外
二、常见rowKey设计遇到的问题以及相应的解决方案
1. 连续rowKey导致的region热点问题:
解决方案:
-
rowKey整个逆序, 主要针对流水数据,前缀的范围查询变得不可用
逆序前分别是: 20170227204355331和20170227204355339 (同一个region) 逆序后分别是: 13355340272207102 和93355340272207102 (不同的region) -
rowKey的部分逆序, 主要针对一些特征的流水数据,而且还可以实现部分前缀的范围查询
逆序前分别是: 20170227204355TNG和20170227204355TFF (同一个region) 逆序后分别是: GNT20170227204355 和FFT20170227204355 (不同的region) - 对rowKey取MD5 Hash, 相领的值做md5 Hash之后,完全不同
- 直接使用UUID , 完全散列开
2. 相同rowKey的问题, 即业务 上没唯一字段:
- 加随机字符串后缀;
- 加时间戳后缀, 根据需要实现按时间递增或递减;
注意:加前缀和后缀,最好设置好分隔符,方便业务上的处理,因为大部分用是的是26个大小写字母和数字,非常适合常见的分割符如 $, #
三、建模案例分析:电商中宝贝点击量建模示例
需求: 统计电商中某个宝贝最近一周的点击量
表的设计:
- 以分钟为单位的近实时统计表 rowKey=itemId + ‘#’+’yyyyMMddHHmm’
- 历史点击量汇总表 rowKey = itemId;
- 最近一周点击量近似汇总表 rowKey = itemId;
在业务上层每半个小时做定时更新
1.新的一周点击量= 最近的半个小时量-7天前的半小时量 + 原来一周的历史量
2.新的历史点击量 += 最近半个小时的点击量;
四、HBase客户端的使用
1 原生客户端Api
1.1连接
Configuration conf = HBaseConfiguraton.create();
conf 设置 HBase zk 和其它参数;
HTable table = new HTable(conf, “test.testTable”);1.2 单个操作
Put put = new Put(Bytes.toBytes(“row1”));
put.add(Bytes.toBytes(“colfam1”), Bytes.toBytes(“qual1”), Bytes.toBytes(“val1”));
put.add(Bytes.toBytes(“colfam1”), Bytes.toBytes(“qual2”), Bytes.toBytes(“val1”));
table.put(put);
// delete操作
Delete delete = new Delete(toBytes(“row2”));
table.delete(delete);
// Get操作
Get get = new Get(toBytes(“row1”));
Result result = table.get(get);1.3 批量操作
List<Put> puts = new ArrayList<Put>(2);
Put put2 = new Put(Bytes.toBytes(“row2”));
put2.add(Bytes.toBytes(“colfam1”), Bytes.toBytes(“qual1”), Bytes.toBytes(“val2”));
put2.add(Bytes.toBytes(“colfam1”), Bytes.toBytes(“qual2”), Bytes.toBytes(“val2”));
Put put3 = new Put(Bytes.toBytes(“row3”));
put3.add(Bytes.toBytes(“colfam1”), Bytes.toBytes(“qual1”), Bytes.toBytes(“val3”));
put3.add(Bytes.toBytes(“colfam1”), Bytes.toBytes(“qual2”), Bytes.toBytes(“val3”));
puts.add(put2);
puts.add(put3);
table.put(puts);1.4 原子自增操作
Long result = table.incrementColumnValue(toBytes(“row1”), toBytes(“colfam1”), 1.5 过滤器的使用
Bytes.toBytes(“qual3”), 3);
PageFilter pageFilter = new PageFilter(1);
Scan scan = new Scan();
scan.setFilter(pageFilter);
Long start = System.currentTimeMillis();
String rowKey = hbaseTemplate.find(tableName, scan, new MinRowKeyMapperExtractor());注意: 不到万不得已,不要使用Filter, 有的Filter的查询 效率很低,最好是结合rowKey范围扫描进行查询
1.6 HBase 管理接口API
管理API, 查找一个HBase集群所有表
HBaseAdmin admin = new HBaseAdmin(configuration);
HTableDescriptor[] htds = admin.listTables();2 Spring集成HBase客户端
1. 添加maven依赖
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>0.98.6-hadoop2</version>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-jpa</artifactId>
<version>1.6.0.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-hadoop</artifactId>
<version>2.0.2.RELEASE</version>
</dependency>2.引入Spring HBase工具类
HbaseConfigurationSpringFactoryBean (二次开发的封装类)
/**
* hbase工厂类
* @author tiandesheng
*
*/
public class HbaseConfigurationSpringFactoryBean implements InitializingBean, FactoryBean<Configuration> {
private static Logger logger = LoggerFactory.getLogger(HbaseConfigurationSpringFactoryBean.class);
private Configuration configuration;
private Properties properties;
public Configuration getObject() throws Exception {
return configuration;
}
public Class<Configuration> getObjectType() {
return Configuration.class;
}
public boolean isSingleton() {
return true;
}
public void afterPropertiesSet() throws Exception {
configuration = HBaseConfiguration.create();
addProperties(configuration, properties);
if (logger.isInfoEnabled()) {
logger.info("Hbase连接初始化完毕!");
}
}
public void addProperties(Configuration configuration, Properties properties) {
if (properties != null) {
for (Entry<Object, Object> entry : properties.entrySet()) {
String key = entry.getKey().toString();
String value = entry.getValue().toString();
configuration.set(key, value);
}
}
}
public void setConfiguration(Configuration configuration) {
this.configuration = configuration;
}
public Configuration getConfiguration() {
return configuration;
}
public void setProperties(Properties properties) {
this.properties = properties;
}
}HTableInterfacePoolFactory (二次开发的封装类)
/**
* 基于线程池的HTable实现工厂
*/
@SuppressWarnings("deprecation")
public class HTableInterfacePoolFactory implements HTableInterfaceFactory, DisposableBean, InitializingBean {
private static final Logger logger = LoggerFactory.getLogger(HTableInterfacePoolFactory.class);
private int poolSize = 50;
private HTablePool pool = null;
private Configuration configuration;
private Map<String, AtomicInteger> initLock;
public void releaseHTableInterface(HTableInterface table) {
close(table);
}
public HTableInterface createHTableInterface(Configuration config, byte[] tableName) {
if (tableName == null) {
return null;
}
if (initLock != null) {
AtomicInteger tlock = initLock.get(new String(tableName).trim());
if (tlock != null && tlock.get() == 0) {
if (logger.isInfoEnabled()) {
logger.info("get Htable:{} connection lock", new String(tableName));
}
tlock.getAndAdd(1);
return pool.getTable(tableName);
}
}
return pool.getTable(tableName);
}
public void afterPropertiesSet() throws Exception {
// 初始化HTablePool
if (pool == null) {
pool = new HTablePool(configuration, poolSize);
if (logger.isInfoEnabled()) {
logger.info("hbase 连接池创建并初始化完毕!");
}
}
}
private void close(HTableInterface hTableInterface) {
if(hTableInterface != null) {
try {
hTableInterface.close();
} catch(Throwable t) {
logger.error("close异常 {},", t);
}
}
}
public void destroy() throws Exception {
initLock.clear();
if (logger.isInfoEnabled()) {
logger.info("Hbase连接池已经关闭!");
}
}
public void setPoolSize(int poolSize) {
this.poolSize = poolSize;
}
public void setConfiguration(Configuration configuration) {
this.configuration = configuration;
}
}HbaseTemplate (核心类)
Spring的模板设置模式, 用法类型于JdbcTemplate, JmsTemplate, TransactionTemplate)
通过以Spring 配置文件方式和纯代码的方式都可以实现Spring集成HBase客户端,不管以那种试,都是要首先设置HBase连接的几个参数,其中zk和zk的端口这两个参数一定要包含,然后依次
初始化上面三个类的对象,最终得到的HbaseTemplate对象就是我们要直接要对HBase进行操作对
象, spring配置文件 和纯代码实现方式如下:
1. spring配置文件的方式:
<bean id="hBaseConfiguration" class="com.xxx.hbase.client.HbaseConfigurationSpringFactoryBean>
<property name="properties">
<props>
<prop key="hbase.zookeeper.quorum", value="${hbase.zookeeper.quorum}" />
<prop key="hbase.zookeeper.property.clientPort" ,
value="${hbase.zookeeper.property.clientPort}" />
<prop key="hbase.master.port",value="${hbase.master.port}" />
</props>
</property>
</bean>
<bean id="hTableInterfacePoolFactory" class="com.xxx.hbase.client.HTableInterfacePoolFactory" >
<property name="configuration" ref="hBaseConfiguration" />
<property name="poolSize" value="${poolSize}" />
</bean>
<bean id="hbaseTemplate" class="org.springframework.data.hadoop.hbase.HbaseTemplate">
<property name="encoding" value="utf-8" />
<property name="configuration" ref="hBaseConfiguration" />
<property name="tableFactory" ref="hTableInterfacePoolFactory" />
</bean>2. 纯代码的方式:
public HbaseTemplate getHbaseTemplate(String hbaseClusterName) {
HbaseTemplate hbaseTemplate = hbaseTemplates.get(hbaseClusterName);
if (hbaseTemplate == null ) {
DcHbaseCluster dcHbaseCluster =
dcHbaseClusterDao.selectByHbaseClusterName(hbaseClusterName);
if (dcHbaseCluster == null) {
throw new RuntimeException("getHbaseTemplate(String hbaseClusterName1) 出错
hbaseClusterName=" + hbaseClusterName);
}
String hbaseZookeeperQuorum = dcHbaseCluster.getHbaseZookeeperQuorum();
String hbaseZookeeperPropertyClientPort =
dcHbaseCluster.getHbaseZookeeperPropertyClientPort();
String hbaseMasterPort = dcHbaseCluster.getHbaseMasterPort();
Integer poolSize = dcHbaseCluster.getPoolSize();
this.addHbaseTemplate(hbaseClusterName, hbaseZookeeperQuorum,
hbaseZookeeperPropertyClientPort, hbaseMasterPort, poolSize);
hbaseTemplate = hbaseTemplates.get(hbaseClusterName);
if (hbaseTemplate == null) {
throw new RuntimeException("getHbaseTemplate(String hbaseClusterName2) 出错
hbaseClusterName=" + hbaseClusterName);
}
}
return hbaseTemplate;
}
public boolean addHbaseTemplate(String hbaseClusterName,String hbaseZookeeperQuorum,
String hbaseZookeeperPropertyClientPort,
String hbaseMasterPort,
Integer poolSize) {
HbaseConfigurationSpringFactoryBean hbaseConfigurationSpringFactoryBean =
new HbaseConfigurationSpringFactoryBean();
Properties properties = new Properties();
//设置zk地址
properties.put(“hbase.zookeeper.quorum”, hbaseZookeeperQuorum);
// 设置zk 端口
properties.put(“hbase.zookeeper.property.clientPort”, hbaseZookeeperPropertyClientPort);
// 设置Hmaster端口
properties.put(“hbase.master.port”, hbaseMasterPort);
hbaseConfigurationSpringFactoryBean.setProperties(properties);
try {
// 初始化
hbaseConfigurationSpringFactoryBean.afterPropertiesSet();
hbaseConfigurationSpringFactoryBean
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException("hbaseConfigurationSpringFactoryBean.afterPropertiesSet()出错");
}
Configuration configuration = null;
try {
// 得到连接Configuration对象
configuration = (Configuration)hbaseConfigurationSpringFactoryBean.getObject();
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException("hbaseConfigurationSpringFactoryBean.getObject()出错!");
}
HTableInterfacePoolFactory hTableInterfacePoolFactory = new HTableInterfacePoolFactory();
hTableInterfacePoolFactory.setConfiguration(configuration);
hTableInterfacePoolFactory.setPoolSize(poolSize);
try {
hTableInterfacePoolFactory.afterPropertiesSet(); // 初始化hTableInterfacePoolFactory对象
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException("hTableInterfacePoolFactory.afterPropertiesSet()出错!");
}
HbaseTemplate hbaseTemplate = new HbaseTemplate();
hbaseTemplate.setEncoding("UTF-8");
hbaseTemplate.setConfiguration(configuration);
hbaseTemplate.setTableFactory(hTableInterfacePoolFactory);
try {
hbaseTemplate.afterPropertiesSet(); // 初始化hbaseTemplate 对象
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException("hbaseTemplate.afterPropertiesSet()出错!");
}
configurations.put(hbaseClusterName, configuration);
hbaseTemplates.put(hbaseClusterName, hbaseTemplate);
return true;
}单个Get读数据操作代码示例
public Map<String, String> find(HbaseTemplate hbaseTemplate,
String tableName,
final String rowKey,
final List<String> columns) {
if (logger.isInfoEnabled()) {
logger.info("find method tableName={}, rowKey={}", tableName, rowKey);
}
Result result = hbaseTemplate.execute(tableName, new TableCallback<Result>() {
public Result doInTable(HTableInterface table) throws Throwable {
// 1.产生Get对象
Get get = getObjectGenerator.generateGet(rowKey, columns);
// 2.单个查询hbase
Long start = System.currentTimeMillis();
Result result = table.get(get);
if (logger.isInfoEnabled()) {
logger.info("find method 消耗时间:{}ms", System.currentTimeMillis() - start);
}
return result;
}
});
if (result == null) {
return null;
}
Map<String, String> res = mapFrom(result);
return res;
}批量Get读数据操作代码示例
public List<Map<String, String>> batchFind(HbaseTemplate hbaseTemplate,
String tableName,
final List<String> columns,
final List<String> rowKeys) {
if (logger.isInfoEnabled()) {
logger.info("batchFind method tableName={}, rowKey={}", tableName, rowKeys);
}
Object object = hbaseTemplate.execute(tableName, new TableCallback<Object>() {
public Object doInTable(HTableInterface table) throws Throwable {
List<Get> listGets = new ArrayList<Get>(10);
for (String rowKey : rowKeys) {
// 1.产生Get对象
Get get = getObjectGenerator.generateGet(rowKey, columns);
listGets.add(get);
}
// 2.批量查询hbase
Long start = System.currentTimeMillis();
Result[] results = table.get(listGets);
if (logger.isInfoEnabled()) {
logger.info("batchFind method 消耗时间:{}ms", System.currentTimeMillis() - start);
}
return results;
}
});
if (object == null) {
return null;
}
Result[] results = (Result[])object;
List<Map<String, String>> res = new ArrayList<Map<String, String>>(10);
for (Result result : results) {
Map<String, String> map = mapFrom(result);
if (map != null) {
res.add(map);
}
}
return res;
}
Spring集成HBase的本质
从上面代码,可以 看出,Spring集成HBase客户端的本质还是对原始的Spring Client进行封装, 从HBase Template的execute方法主要有三个重要的步骤:
- 根据表名,获得或创建HBase表连接实例 HTableInterface;
- 执行业务 上实现的doInTable回调方法, 即执行真正读写HBase操作;
- 把HBase连接实例放回到表池中;
五、HBase优化
1.JVM参数优化:
- –Xmn=12G –Xms=24G -Xmx=24G 根据实际机器情况调整,一般为整个机器内存的一半,同时建议regionServer的堆内存建议不要超过32G ;
- -XX:PermSize=512M -XX:MaxPermSize=512M;
- -XX:+UseConcMarkSweepGC -XX:+UseParNewGC (建议使用CMS垃圾收集器, 其它JVM参数使用默认比较好)
2.HBase客户端使用优化:
- 用表池或创建多个客户端,适当提高HBase客户端写入的并发性;
- 尽可能批量写和批量读,减少RPC交互的次数;
- 不要读取不必要的列数据, 限定scan的数据范围;
- 读取到客户端的结果后,一定要关闭结果集, 即关闭Results和ReultsScanner;
- 根据HBase CPU的利用率,合时设置压缩算法,前提是要服务需要安装压缩算法包;
6.关闭AutoFlush , 设置setAutoToFlush(false) 不建议,有丢数据的风险;
7.关闭WAL Flag,设置setWriteToWAL(false), 不建议,有丢数据的风险;
3. 建表时优化:
1.根据不同的业务,合理地设置好HBase表命名空间;
- 创建预分区, 减少region分裂的次数,并且写入的负载也比较 好;
- 动态添加分区, 在HBase后面新的稳定版本中会有这个功能,华为、阿里、facebook公司内部二次开发的HBase已经添加了这个功能;
4. 运维时优化:
- 业务低峰期时,手动或定进均衡;
- 业务 高峰期时,关闭自动负载(不建议使用);
5 .配置参数优化:
- 设置StoreFile的大小: 根据业务场景适当增大hbase.hregion.max.filesize减少写入过程中split的次数,同时也减少了Region的数量,新版本默认是10G,老版本默认是512M,新版本建议用默认值;
- 设置memstore固定缓冲区块的大小:hbase.hregion.memstore.mslab.chunksize, 默认是2M, 最好是根据一次写入数据大小进行评估,建议用默认值;
- 减少Zookeeper超时的发生: zookeeper.session.timeout, 默认是3分钟, 可以修改为一分钟或半分钟, 加快HMaster发现故障的regionServer;
- 增加处理线程: hbase.regionserver.handler.cout, 默认值为10, 如果批量写,这个值可以设置小些,如果是单 个读写,这个值可以适当设置大些;
- 启用数据压缩: 推荐使用Snappy或者LZO压缩, 前提是需要安装这个压缩算法的jar包,然后再进行配置,重启;
- 适当增加块缓存的大小: perf.hfile.block.cache.size 默认为0.2,这个需要查看内存刷写到磁盘的频率,如果不是很频繁,可以适当增加这个值的设置,建议0.2 ~ 0.3之间;
- 调整memStore限制: hbase.regionsever.global.memstore.upperLimit 默认为0.4 hbase.regionsever.global.memstore.lowerLimit 默认为0.35, 建议把这两个值设置近些或相等;
- 增加阻塞时存储 文件数目: hbase.hstore.blockingStoreFiles 默认值 为7,当一个region的StoreFile的个数超过值的时候,更新就会阻塞, 在高并写的情况 下,设置 为10左右比较 为合理;
- 增加阻塞倍率 : hbase.region.memstore.block.multiplier 默认值是2, 当memstore达到multiplier 乘以flush的大小时,写入就会阻塞, 对于写压力比较大,可以增加这个值,一般 为设置为2-4;
- 减少最大日志 文件 限制: hbase.regionserver.maxlogs 默认是32, 对于写压力比较大的情况 ,可以减少这个值的设置, 加快后台异步线程的定时清理工作;
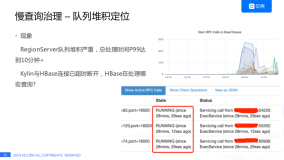
六、HBase连续分页问题查询的参考解决方案
在实际的应用中,有很多少分页查询显示的功能,但HBase中分页过滤器在跨region的时候,会出现各种无法预测的问题,导致读取的数据丢失,为了解决这个问题,需要在业务端进行多次连续查询 ,在基于region根据rowKey连续递增的情况下,给出如下的解决方案:

源代码如实现如下:
public Map<String, Map<String, String>> prefixScanOfPageFilter(HbaseTemplate hbaseTemplate,
String tableName,
List<String> columns,
String prefix,
String startRow,
int pageSize,
final String isProcessedNostringColumn,
final Set<String> tableColumnSet) {
if (logger.isInfoEnabled()) {
logger.info("prefixScanOfPageFilter method tableName={}", tableName);
}
// 每次都要重新查询
TreeSet<HbaseRegionInfo> hbaseRegionInfos = new TreeSet<HbaseRegionInfo>(new Comparator<HbaseRegionInfo>() {
@Override
public int compare(HbaseRegionInfo o1, HbaseRegionInfo o2) {
if (o1 == null && o2 == null) {
return 0;
} else if (o1 != null && o2 == null) {
return 1;
} else if (o1 == null && o2 != null) {
return -1;
}
return Bytes.compareTo(o1.getStartRow(), o2.getStartRow());
}
});
try {
HBaseAdmin admin = new HBaseAdmin(hbaseTemplate.getConfiguration());
List<HRegionInfo> regionInfos = admin.getTableRegions(tableName.getBytes());
if (regionInfos == null) {
return null;
}
for (HRegionInfo hRegionInfo : regionInfos) {
HbaseRegionInfo hbaseRegionInfo = new HbaseRegionInfo(hRegionInfo.getStartKey(), hRegionInfo.getEndKey() );
hbaseRegionInfos.add(hbaseRegionInfo);
}
} catch (Exception e) {
e.printStackTrace();
}
StringBuffer buffer = new StringBuffer(2);
String endRow = buffer.append((char)((int)prefix.charAt(0) + 1)).toString();
// 确定region区间范围
TreeSet<HbaseRegionInfo> regionInfoRanges = decideRegionRange(hbaseRegionInfos, startRow, endRow);
// 返回结果
Map<String, Map<String, String>> result = new HashMap<String, Map<String, String>>(pageSize+1);
Long start = System.currentTimeMillis();
byte[] byteBegin = toBytes(startRow);
byte[] byteEnd = toBytes(endRow);
HbaseRegionInfo first = regionInfoRanges.first();
while (result.size() < pageSize + 1 ) {
// 分页过滤器
PageFilter pageFilter = new PageFilter(pageSize + 1 - result.size());
// 当前查询的结果
Map<String, Map<String, String>> currentResult = null;
byte[] firstEndRow = first.getEndRow();
// 考虑为空的情况 1 >> 结束
if (firstEndRow == null || firstEndRow.length == 0) {
Scan scan = new Scan( byteBegin, byteEnd );
scan = getObjectGenerator.generateScan(scan, columns);
scan.setFilter(pageFilter);
currentResult = hbaseTemplate.find(tableName, scan,
new MapperAndRowKeyDetailExtractor(isProcessedNostringColumn, tableColumnSet));
result.putAll(currentResult);
if (logger.isInfoEnabled()) {
logger.info("findByPageFilter2 method 消耗时间:{}ms", System.currentTimeMillis() - start);
}
return result;
}
// 比较确定区间
int cmp = Bytes.compareTo( byteEnd, firstEndRow );
if ( cmp < 0 ) {
// 在region范围之内, 1 >> 结束
Scan scan = new Scan( byteBegin, byteEnd );
scan = getObjectGenerator.generateScan(scan, columns);
scan.setFilter(pageFilter);
currentResult = hbaseTemplate.find(tableName, scan,
new MapperAndRowKeyDetailExtractor(isProcessedNostringColumn, tableColumnSet));
result.putAll(currentResult);
if (logger.isInfoEnabled()) {
logger.info("findByPageFilter2 method 消耗时间:{}ms", System.currentTimeMillis() - start);
}
return result;
} else if ( cmp == 0 ) { // 还有特殊处理(暂时不要和1的情况合并)
// 刚好在region范围之内, 2 >> 结束
Scan scan = new Scan( byteBegin, byteEnd );
scan = getObjectGenerator.generateScan(scan, columns);
scan.setFilter(pageFilter);
currentResult = hbaseTemplate.find(tableName, scan,
new MapperAndRowKeyDetailExtractor(isProcessedNostringColumn, tableColumnSet));
result.putAll(currentResult);
if (logger.isInfoEnabled()) {
logger.info("findByPageFilter2 method 消耗时间:{}ms", System.currentTimeMillis() - start);
}
return result;
} else {
// 在范围之外(跨region), 需要再次查询
Scan scan = new Scan( byteBegin, firstEndRow );
scan = getObjectGenerator.generateScan(scan, columns);
scan.setFilter(pageFilter);
currentResult = hbaseTemplate.find(tableName, scan,
new MapperAndRowKeyDetailExtractor(isProcessedNostringColumn, tableColumnSet));
result.putAll(currentResult);
if (result.size() < pageSize + 1) {
if ( first.getStartRow() == null || first.getStartRow().length == 0 ) {
HbaseRegionInfo tmp = new HbaseRegionInfo(first.getEndRow(), first.getEndRow());
first = regionInfoRanges.ceiling(tmp);
} else {
first = regionInfoRanges.higher(first);
}
if (first == null) {
return result;
}
byteBegin = first.getStartRow();
} else {
// 数量满足要求 4 >> 结束
if (logger.isInfoEnabled()) {
logger.info("findByPageFilter2 method 消耗时间:{}ms", System.currentTimeMillis() - start);
}
return result;
}
}
}
return null;
}
/**
* 确定region的范围
* @param sets
* @param startRow
* @param endRow
* @return
*/
private TreeSet<HbaseRegionInfo> decideRegionRange(TreeSet<HbaseRegionInfo> sets, String startRow, String endRow) {
HbaseRegionInfo first = new HbaseRegionInfo(toBytes(startRow), toBytes(startRow));
HbaseRegionInfo second = new HbaseRegionInfo(toBytes(endRow), toBytes(endRow));
HbaseRegionInfo firstLower = sets.lower(first);
HbaseRegionInfo firstHigher = sets.ceiling(first);
HbaseRegionInfo secondLower = sets.lower(second);
HbaseRegionInfo secondHigher = sets.ceiling(second);
HbaseRegionInfo firstRegion = null;
HbaseRegionInfo secondRegion = null;
if ( (firstLower != null && (firstLower.getEndRow() == null || firstLower.getEndRow().length == 0) ) &&
firstHigher == null) {
TreeSet<HbaseRegionInfo> result = new TreeSet<HbaseRegionInfo>(new Comparator<HbaseRegionInfo>() {
@Override
public int compare(HbaseRegionInfo o1, HbaseRegionInfo o2) {
if (o1 == null && o2 == null) {
return 0;
} else if (o1 != null && o2 == null) {
return 1;
} else if (o1 == null && o2 != null) {
return -1;
}
return Bytes.compareTo(o1.getStartRow(), o2.getStartRow());
}
});
result.add(firstLower);
return result;
}
// 连续相连的情况
// if (firstLower.getEndRow().equals(firstHigher.getStartRow())) {
if (startRow.equals(firstHigher.getStartRow())) {
// 在region边缘,即第一个值
firstRegion = firstHigher;
} else {
// 在region区间
firstRegion = firstLower;
}
// }
if ((secondLower != null && (secondLower.getEndRow() == null || secondLower.getEndRow().length == 0) ) &&
secondHigher == null) {
secondRegion = secondLower;
}
// if (secondLower.getEndRow().equals(secondHigher.getStartRow())) {
if (endRow.equals(secondHigher.getStartRow())) {
secondRegion = secondHigher;
} else {
secondRegion = secondLower;
}
// }
return (TreeSet<HbaseRegionInfo>)sets.subSet(firstRegion, true, secondRegion, true);
}
因为region一般都比较大,在实践中,我们发现绝大数查询,是不存在跨页查询,跨页查询的情况下,大部分也是跨1 个页,跨2个以上页的情况非常罕见,因此查询效率没有感觉到明显变慢