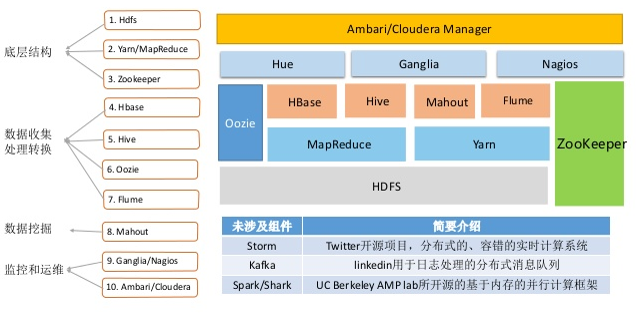
一、Hadoop系统架构图
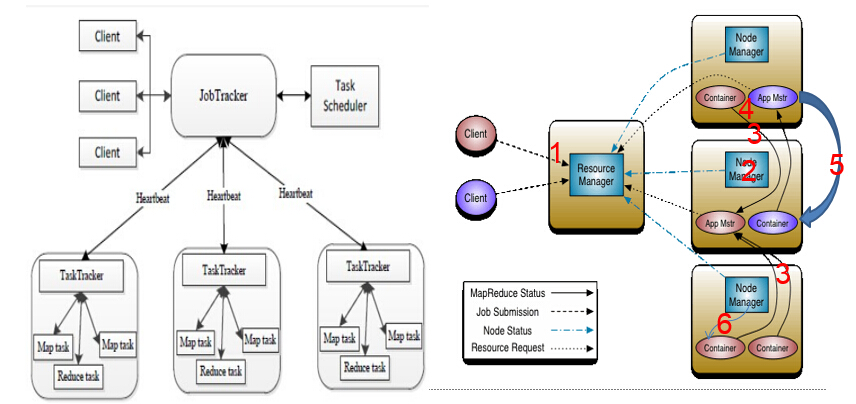
Hadoop1.0与hadoop2.0架构对比图
YARN架构:
ResourceManager
NodeManager
ApplicationMaster
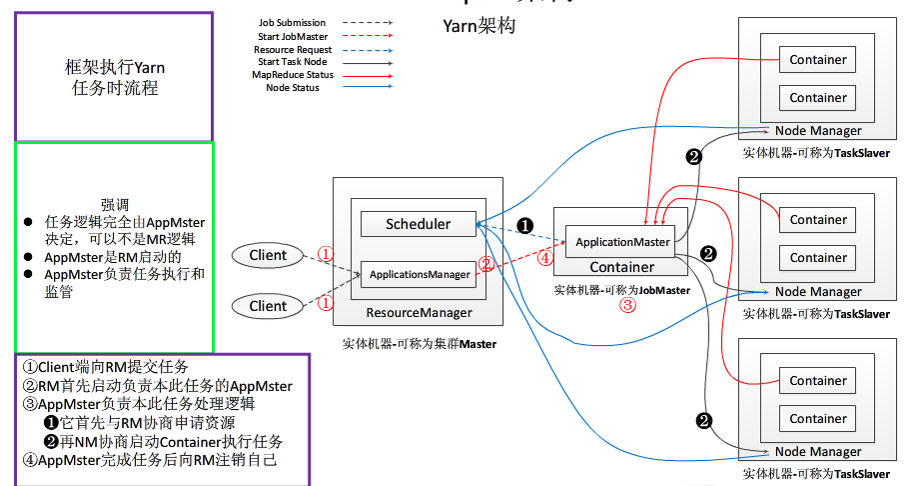
步骤1 用户向YARN 中提交应用程序, 其中包括ApplicationMaster 程序、启动ApplicationMaster 的命令、用户程序等。
步骤2 ResourceManager 为该应用程序分配第一个Container, 并与对应的NodeManager 通信,要求它在这个Container 中启动应用程序的ApplicationMaster。
步骤3 ApplicationMaster 首先向ResourceManager 注册, 这样用户可以直接通过ResourceManage 查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤4~7。
步骤4 ApplicationMaster 采用轮询的方式通过RPC 协议向ResourceManager 申请和领取资源。
步骤5 一旦ApplicationMaster 申请到资源后,便与对应的NodeManager 通信,要求它启动任务。
步骤6 NodeManager 为任务设置好运行环境(包括环境变量、JAR 包、二进制程序
等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
步骤7 各个任务通过某个RPC 协议向ApplicationMaster 汇报自己的状态和进度,以让ApplicationMaster 随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC 向ApplicationMaster 查询应用程序的当
前运行状态。
步骤8 应用程序运行完成后,ApplicationMaster 向ResourceManager 注销并关闭自己。
运行在YARN上带来的好处 :
利用共享存储在两个NN间同步edits信息,如NFS等中高端存储设备内部的各种RAID以及冗余硬件
DataNode同时向两个NN汇报块信息,让Standby NN保持集群最新状态
用FailoverController watchdog进程监视和控制NN进程,防止因 NN FullGC挂起无法发送heart beat
防止脑裂(brain-split):主备切换时由于切换不彻底等原因导致Slave误以为出现两个active master,通常采用Fencing机制:
-共享存储fencing,确保只有一个NN可以写入edits
-客户端fencing,确保只有一个NN可以响应客户端的请求
- DN fencing,确保只有一个NN可以向DN下发删除等命令
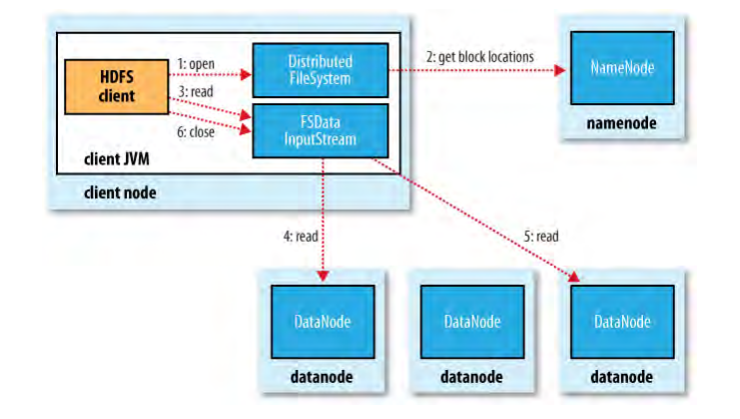
HDFS文件读取:
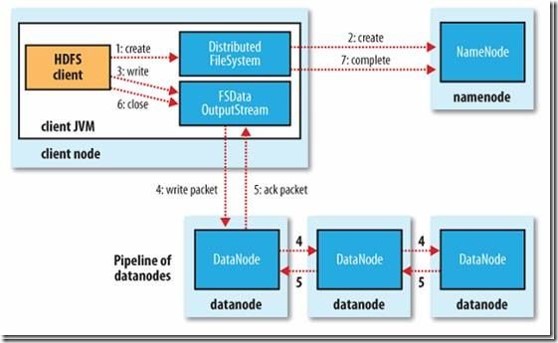
HDFS文件写入:
MapReduce基本流程:
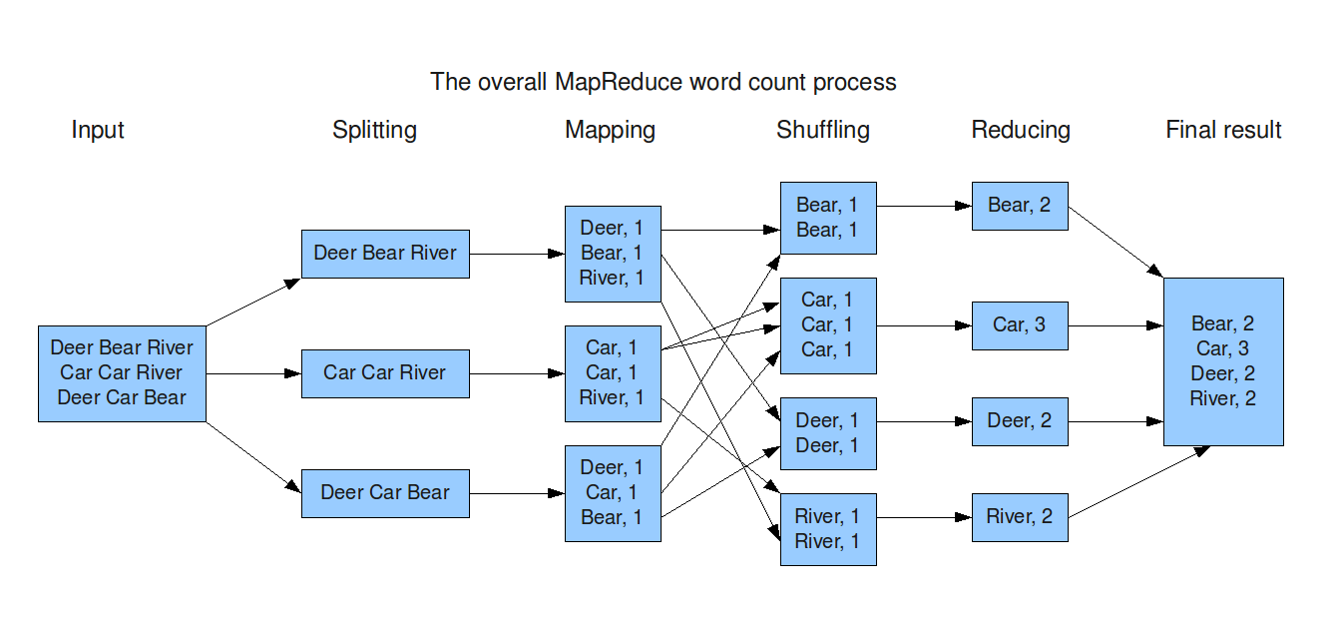
从MapReduce 自身的命名特点可以看出, MapReduce 由两个阶段组成:Map 和Reduce。用户只需编写map() 和 reduce() 两个函数,即可完成简单的分布式程序的设计。
map() 函数以key/value 对作为输入,产生另外一系列 key/value 对作为中间输出写入本地磁盘。 MapReduce 框架会自动将这些中间数据按照 key 值进行聚集,且key 值相同(用户可设定聚集策略,默认情况下是对 key 值进行哈希取模)的数据被统一交给 reduce() 函数处理。
reduce() 函数以key 及对应的value 列表作为输入,经合并 key 相同的value 值后,产生另外一系列 key/value 对作为最终输出写入HDFS
hello world --WordCount
用户编写完MapReduce 程序后,按照一定的规则指定程序的输入和输出目录,并提交到Hadoop 集群中。作业在Hadoop 中的执行过程如图所示。Hadoop 将输入数据切分成若干个输入分片(input split,后面简称split),并将每个split 交给一个Map Task 处理;Map Task 不断地从对应的split 中解析出一个个key/value,并调用map() 函数处理,处理完之后根据Reduce Task 个数将结果分成若干个分片(partition)写到本地磁盘;同时,每个Reduce Task 从每个Map Task 上读取属于自己的那个partition,然后使用基于排序的方法将key 相同的数据聚集在一起,调用reduce() 函数处理,并将结果输出到文件中
