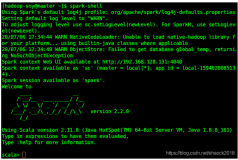
错误信息如下:
5/11/03 16:48:15 INFO spark.SparkContext: Running Spark version 1.4.1 15/11/03 16:48:15 WARN spark.SparkConf: In Spark 1.0 and later spark.local.dir will be overridden by the value set by the cluster manager (via SPARK_LOCAL_DIRS in mesos/standalone and LOCAL_DIRS in YARN). 15/11/03 16:48:15 WARN spark.SparkConf: SPARK_JAVA_OPTS was detected (set to '-verbose:gc -XX:-UseGCOverheadLimit -XX:+UseCompressedOops -XX:-PrintGCDetails -XX:+PrintGCTimeStamps -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/home/xujingwen/ocdc/spark-1.4.1-bin-hadoop2.6/1103164805.hprof'). This is deprecated in Spark 1.0+. Please instead use: - ./spark-submit with conf/spark-defaults.conf to set defaults for an application - ./spark-submit with --driver-java-options to set -X options for a driver - spark.executor.extraJavaOptions to set -X options for executors - SPARK_DAEMON_JAVA_OPTS to set java options for standalone daemons (master or worker) 15/11/03 16:48:15 WARN spark.SparkConf: Setting 'spark.executor.extraJavaOptions' to '-verbose:gc -XX:-UseGCOverheadLimit -XX:+UseCompressedOops -XX:-PrintGCDetails -XX:+PrintGCTimeStamps -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/home/xujingwen/ocdc/spark-1.4.1-bin-hadoop2.6/1103164805.hprof' as a work-around. 15/11/03 16:48:15 WARN spark.SparkConf: Setting 'spark.driver.extraJavaOptions' to '-verbose:gc -XX:-UseGCOverheadLimit -XX:+UseCompressedOops -XX:-PrintGCDetails -XX:+PrintGCTimeStamps -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/home/xujingwen/ocdc/spark-1.4.1-bin-hadoop2.6/1103164805.hprof' as a work-around. 15/11/03 16:48:15 WARN spark.SparkConf: SPARK_CLASSPATH was detected (set to ':ls $SPARK_HOME/lib/*.jar'). This is deprecated in Spark 1.0+. Please instead use: - ./spark-submit with --driver-class-path to augment the driver classpath - spark.executor.extraClassPath to augment the executor classpath 15/11/03 16:48:15 WARN spark.SparkConf: Setting 'spark.executor.extraClassPath' to ':ls $SPARK_HOME/lib/*.jar' as a work-around. 15/11/03 16:48:15 ERROR spark.SparkContext: Error initializing SparkContext. org.apache.spark.SparkException: Found both spark.driver.extraClassPath and SPARK_CLASSPATH. Use only the former. at org.apache.spark.SparkConf$$anonfun$validateSettings$6$$anonfun$apply$8.apply(SparkConf.scala:444) at org.apache.spark.SparkConf$$anonfun$validateSettings$6$$anonfun$apply$8.apply(SparkConf.scala:442) at scala.collection.immutable.List.foreach(List.scala:318) at org.apache.spark.SparkConf$$anonfun$validateSettings$6.apply(SparkConf.scala:442) at org.apache.spark.SparkConf$$anonfun$validateSettings$6.apply(SparkConf.scala:430) at scala.Option.foreach(Option.scala:236) at org.apache.spark.SparkConf.validateSettings(SparkConf.scala:430) at org.apache.spark.SparkContext.<init>(SparkContext.scala:365) at org.apache.spark.repl.SparkILoop.createSparkContext(SparkILoop.scala:1017) at $line3.$read$$iwC$$iwC.<init>(<console>:9) at $line3.$read$$iwC.<init>(<console>:18) at $line3.$read.<init>(<console>:20) at $line3.$read$.<init>(<console>:24) at $line3.$read$.<clinit>(<console>) at $line3.$eval$.<init>(<console>:7) at $line3.$eval$.<clinit>(<console>)
查看spark-env.sh 和spark-default.conf中的配置发现两边都写的有classpath
//spark-default.conf # Default system properties included when running spark-submit. # This is useful for setting default environmental settings. # Example: # spark.master spark://master:7077 # spark.eventLog.enabled true # spark.eventLog.dir hdfs://namenode:8021/directory # spark.serializer org.apache.spark.serializer.KryoSerializer # spark.driver.memory 5g # spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three" # # spark.serializer org.apache.spark.serializer.KryoSerializer spark.local.dir /home/xujingwen/data/pseudo-dist/spark/local,/home/xujingwen/data/pseudo-dist/spark/local spark.io.compression.codec snappy spark.speculation false spark.yarn.executor.memoryOverhead 512 #spark.storage.memoryFraction 0.4 spark.eventLog.enabled true spark.eventLog.dir hdfs://cdh5cluster/eventLog spark.eventLog.compress true spark.driver.extraClassPath /home/xujingwen/ocdc/spark-1.4.1-bin-2.6.0-cdh5.4.4/lib/mysql-connector-java-5.1.30-bin.jar:/home/xujingwen/ocdc/spark-1.4.1-bin-2.6.0-cdh5. 4.4/lib/datanucleus-api-jdo-3.2.6.jar:/home/xujingwen/ocdc/spark-1.4.1-bin-2.6.0-cdh5.4.4/lib/datanucleus-core-3.2.10.jar:/home/xujingwen/ocdc/spark-1.4.1-bin-2.6.0-cdh 5.4.4/lib/datanucleus-rdbms-3.2.9.jar
//spark-env.sh # Generic options for the daemons used in the standalone deploy mode # - SPARK_CONF_DIR Alternate conf dir. (Default: ${SPARK_HOME}/conf) # - SPARK_LOG_DIR Where log files are stored. (Default: ${SPARK_HOME}/logs) # - SPARK_PID_DIR Where the pid file is stored. (Default: /tmp) # - SPARK_IDENT_STRING A string representing this instance of spark. (Default: $USER) # - SPARK_NICENESS The scheduling priority for daemons. (Default: 0) MASTER=yarn-client SPARK_HOME=/home/xujingwen/ocdc/spark-1.4.1-bin-2.6.0-cdh5.4.4 SCALA_HOME=/home/xujingwen/ocdc/scala JAVA_HOME=/home/xujingwen/ocdc/jdk1.7.0_21 HADOOP_HOME=/home/xujingwen/ocdc/hadoop-2.6.0-cdh5.4.4 export SPARK_MASTER_IP=192.168.0.4 HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop SPARK_EXECUTOR_INSTANCES=50 SPARK_EXECUTOR_CORES=2 SPARK_EXECUTOR_MEMORY=4G SPARK_DRIVER_MEMORY=3G SPARK_YARN_APP_NAME="Spark-1.1.0" #export SPARK_YARN_QUEUE="default" SPARK_SUBMIT_LIBRARY_PATH=$SPARK_LIBRARY_PATH:$HADOOP_HOME/lib/native SPARK_JAVA_OPTS="-verbose:gc -XX:-UseGCOverheadLimit -XX:+UseCompressedOops -XX:-PrintGCDetails -XX:+PrintGCTimeStamps $SPARK_JAVA_OPTS -XX:+HeapDumpOnOutOfMemoryEr ror -XX:HeapDumpPath=/home/xujingwen/ocdc/spark-1.4.1-bin-hadoop2.6/`date +%m%d%H%M%S`.hprof" export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=1000 -Dspark.history.retainedApplications=1000 -Dspark.history.fs.logD irectory=hdfs://cdh5cluster/eventLog" #export SPARK_CLASSPATH=$SPARK_CLASSPATH:/home/xujingwen/ocdc/apache-hive-1.2.1-bin/lib/mysql-connector-java-5.1.30-bin.jar for libjar in 'ls $SPARK_HOME/lib/*.jar' do SPARK_CLASSPATH=$SPARK_CLASSPATH:$libjar done
spark1.4版本以后 应统一将classpath配置到spark-default.conf文件中 如下: