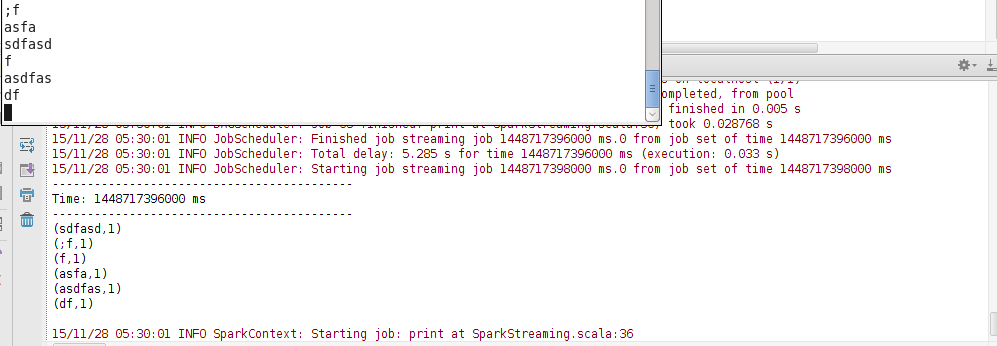
createStream那几个参数折腾了我好久。。网上都是一带而过,最终才搞懂..关于sparkStreaming的还是太少,最终尝试成功。。。
首先启动zookeeper
./bin/zookeeper-server-start.sh config/zookeeper.properties &
启动kafka
bin/kafka-server-start.sh config/server.properties &
创建一个topic
./kafka-topics.sh --create --zookeeper 192.168.77.133:2181 \ --replication-factor 1\ --partitions 1\ --topic yangsy
随后启动一个终端为9092的提供者
./kafka-console-producer.sh --broker-list 192.168.77.133:9092 --topic yangsy
代码如下:
import org.apache.spark.SparkConf import org.apache.spark.storage.StorageLevel import org.apache.spark.streaming.kafka.KafkaUtils import org.apache.spark.streaming.{Seconds, StreamingContext} /** * Created by root on 11/28/15. */ object SparkStreaming { def main(args: Array[String]) { /* val sparkConf = new SparkConf().setMaster("local").setAppName("cocapp") .set("spark.executor.memory", "1g") val sc = new StreamingContext(sparkConf, Seconds(20)) val lines = sc.textFileStream("/usr/local/spark-1.4.0-bin-2.5.0-cdh5.2.1/streaming") val words = lines.flatMap(_.split(" ")) val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _) wordCounts.print() sc.start() sc.awaitTermination()*/ //zookeeper的地址 val zkQuorum = "192.168.77.133:2181"
//group_id可以通过kafka的conf下的consumer.properties中查找 val group ="test-consumer-group"
//创建的topic 可以是一个或多个 val topics = "yangsy" val sparkConf = new SparkConf().setMaster("local").setAppName("cocapp").set("spark.executor.memory", "1g") val sc = new StreamingContext(sparkConf, Seconds(2)) val numThreads = 2 val topicpMap = topics.split(",").map((_, numThreads.toInt)).toMap
//StorageLevel.MEMORY_AND_DISK_SER为存储的级别 val lines = KafkaUtils.createStream(sc, zkQuorum, group, topicpMap, StorageLevel.MEMORY_AND_DISK_SER).map(_._2)
//对于收到的消息进行wordcount val words = lines.flatMap(_.split(" ")) val pairs = words.map(word => (word, 1)) val wordCounts = pairs.reduceByKey(_ + _) wordCounts.print() sc.start() sc.awaitTermination() } }
随后再你启动的kafka的生产者终端随便输入消息,我这里设置的参数是每2秒获取一次,统计一次单词个数~OK~