Storm系统的数据处理应用单元,是被打包的被称为Topology的作业。 它是由多个数据处理阶段组合而成的,而每个处理阶段在构造时被称为组件(Component),在运行时被称为任务。
那么,组件根据作用的不同,在Storm中分为两类:Spout组件和Bolt组件。而Topology就是这两类组件通过数据流连接的一种计算逻辑结构。(也就是说,上一个组建处理的输出结果,作为下游组件的输入数据流继续处理。如下图所示:
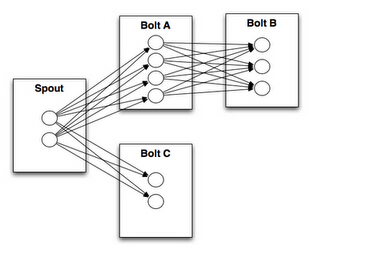
下来说明下一个Topology包含的这两种组件(Spout和Bolt):
Spout:Storm中的数据源编程单元,用于为Topology生产消息(数据).一般会从外部数据源不间断地读取数据,并作为一定结构的数据项(Tuple元祖)传递给Topology处理。
Bolt:Storm中的数据处理编程单元,实现Topology中的相关数据处理逻辑。在Bolt中,编程人员可以实现数据过滤、聚合、查询数据库等操作,处理的结果以一定结构的数据项,以流式处理的方式向下游组件传递和处理。
stream:组件间的数据传递分为三种形式,Stream grouping、All Grouping 、Drect Grouping等,具体等学习后再记录咯~