今天总结下,Hive metastore的结构设计。什么是metadata呢,对于它的描述,可以理解为数据的数据,主要是描述数据的属性的信息。它是用来支持如存储位置、历史数据、资源查找、文件记录等功能。元数据算是一种电子式目录。为了达到编制目录的目的,必须在描述并收藏数据的内容或特色,进而达成协助数据检索的目的。
那么我们从hive metastore的表结构设计开始:
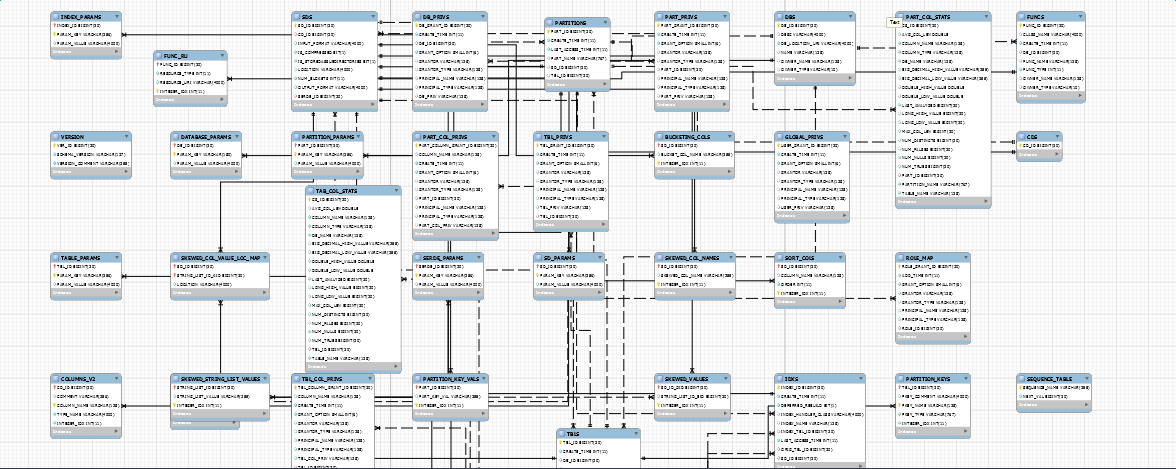
看到后,是不是有一种想死的冲动?没错,我也想死,但是我们可以一点一点的看,也会有理解错误,但这都是在我们通向精通的路途之上,不是么?那么我们围绕着几个核心主表进行分析。
1、DBS 表 Columns:DB_ID、DESC、DB_LOCATION_URI、NAME、OWNER_NAME、OWNER_TYPE
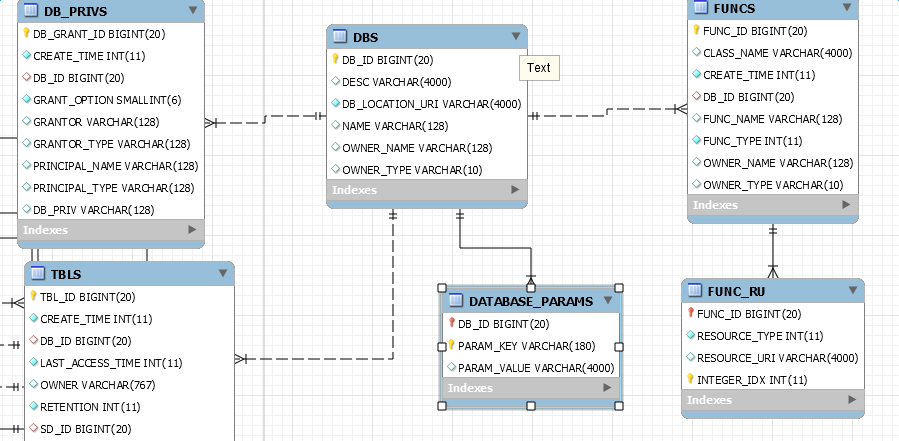
DBS 表记录基本的db信息,其中DB_ID为其主键,同时也是FUNC_RU、FUNCS、DB_PRIVS、DATABASE_PARAMS、以及TBLS的外键。
一般来说,在hive meta初始化时都会自动创建一个名叫default的库,随后通过业务发展以及数据治理等需求,可进行不同业务域库的划分。
FUNC 表是用来存储udf的基本信息,一个UDF只能对应一个库下的表。FUNC_RU表,用于存储该udf的类型及指向的路径。
DB_PRIVS 表记录该DB下的权限记录信息,具体没怎么研究,因为现在更多的集成开源的类似于sentry、range等成熟的权限框架。
DATABASE_PARAMS 表记录DB的一些扩展信息,便于进行特殊属性的扩展。
TBLS 表自然是记录该DB下的所有Table信息。对应唯一的DB_ID。
2、TBLS 表 Columns:TBL_ID、CREATE_TIME、DB_ID,LAST_ACCESS_TIME、OWNER、RETENTION、SD_ID、TBL_NAME、TBL_TYPE、VIEW_EXPANDED_TEXT、VIEW_ORIGNAL_TEXT
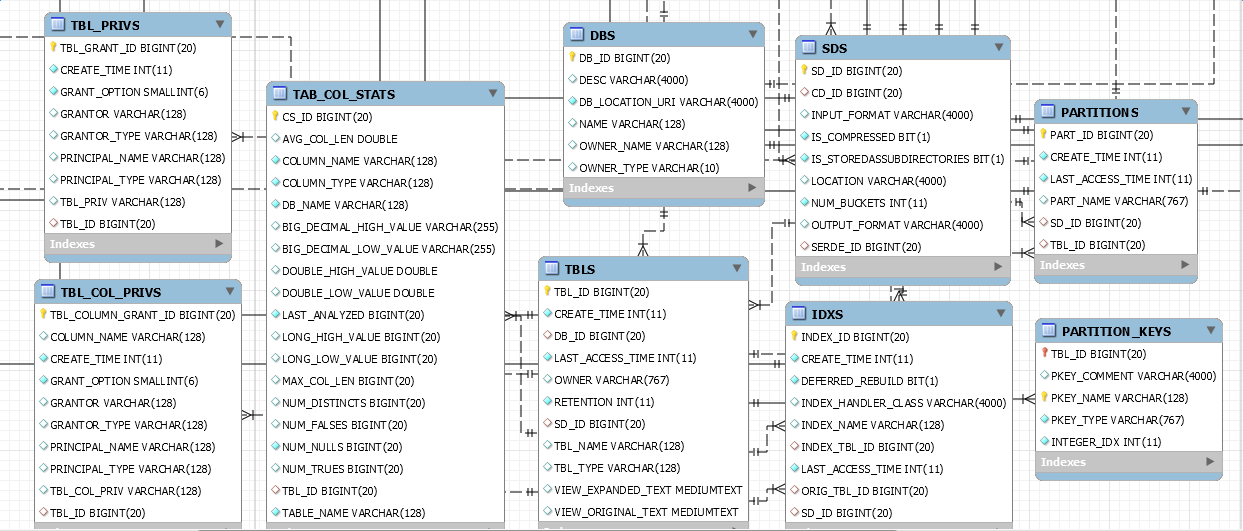
首先,TBLS表,这个表主要记录了table的一些基本信息,包括表名、创建时间、类型,以及SD_ID等信息。tbl_id为TBLS的主键,同时也是TABLE_PARAMS、TBL_COL_PRIVS、IDXS、TBL_PRIVS、SDS、PARTITIONS、PARTITION_KEYS、TAB_COL_STATS表的外键。
每个TBLS都对应唯一的DB_ID,取决于你在哪个db下创建的表。在创建表写入meta的同时,也会创建相应的物理路径。同时会在SDS表中加入DDL时设置的input output、表的location以及SERDE信息(具体下面再说)
TBL_PRIVS、TBL_COL_PRIVS表记录该hive表的表及列权限认证信息。PARTITIONS表记录该表的DDL分区的信息,对于PARTITION_KEYS以及PARTITION_VALUES都是用于PartName的拼接获取。(可查看本博客 hive metadata源码解析)
(IDXS 与 TAB_COL_STATS还没有深入研究,后续添加)
3、PARTITIONS 表 Columns:PART_ID、CREATE_TIME、LAST_ACCESS_TIME、PART_NAME、SD_ID、TBL_ID
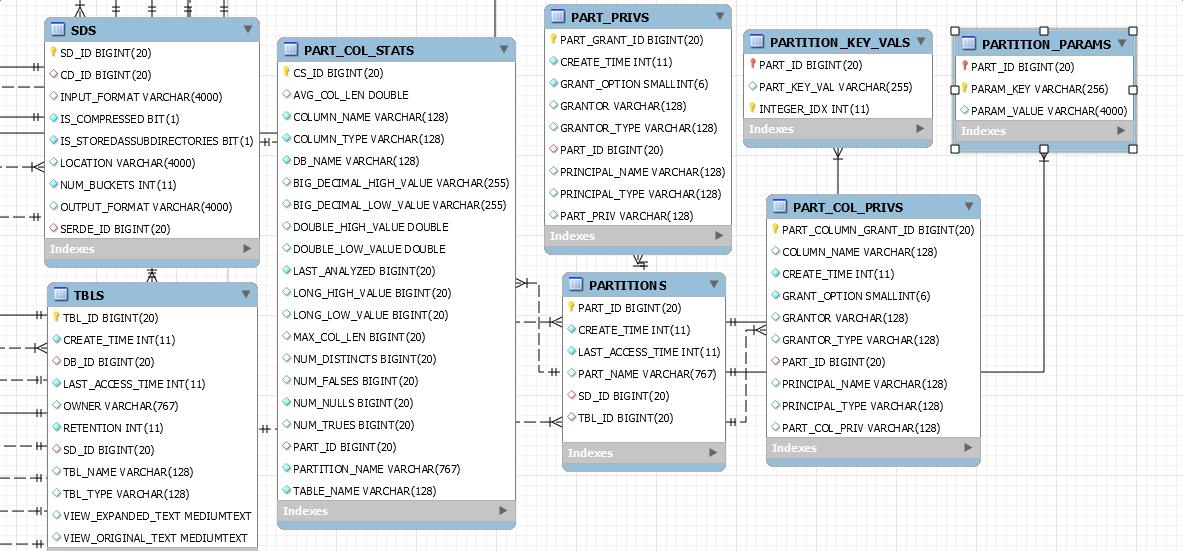
PARTITIONS表,通过表名也能才想到,它是partition分区存储的元数据信息。
PART_ID为PARTITIONS表的主键,同时也是PART_COL_STATS、PART_PRIVS、PARTITION_KEY_VALS、PARTITION_PARAMS、DATABASE_PARAMS表的外键。
Partition表在metastore中是相当重要的表,关系到partition的元数据存取(具体可参考本博客hive metastore partition篇)
4、SDS 表 Columns:SD_ID、CD_ID、INPUT_FORMAT、IS_COMPRESSED、IS_STOREDASSUBDIRECTORIES、LOCATION\NUM_BUCKETS、OUTPUT_FORMAT、SERDE_ID
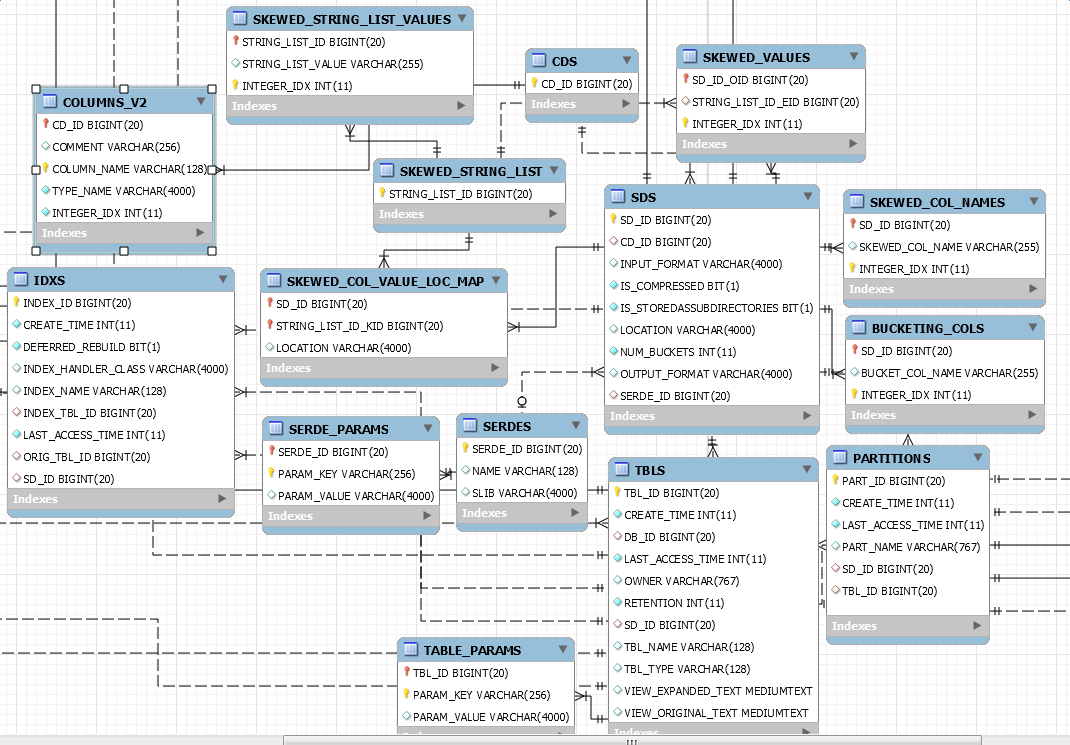
SDS表主要包含计算引擎运行时需要的input与output 、location路径以及序列化的class信息。SD_ID为该表的主键,同时也是PARTITIONS、BUCKETING_COLS、SKEWD_COL_NAMES、SD_PARAMS、SORT_COLS、SKEWED_VALUES、IDXS的外键。
今天大概先梳理到这里,后面我们从代码层面详细分析。新年快乐~o(* ̄︶ ̄*)o~


