
本文根据阿里云大数据计算平台资深架构师林伟在大流量高并发互联网应用实践在线峰会上题为《MaxCompute大数据运算挑战与实践》的分享整理而成。分享中,他主要介绍了在大数据、大流量、高并发情况下MaxCompute所面临的挑战,以及应对这些挑战的实践经验。
直播视频:点击此处观看
幻灯片地址:点击此处下载
以下为在线分享观点整理。
什么是MaxCompute?
大数据计算服务(MaxCompute,原名ODPS)是一种快速、完全托管的PB/EB级数据仓库解决方案,具备万台服务器扩展能力和跨地域容灾能力,是阿里巴巴内部核心大数据平台,支撑每日百万级作业规模。MaxCompute向用户提供了完善的数据导入方案以及多种经典的分布式计算模型,能够更快速的解决用户海量数据计算问题,有效降低企业成本,并保障数据安全。
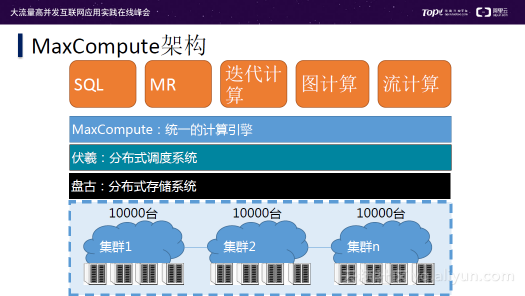
上图是MaxCompute的架构图,该架构中包含多个万台级别的集群,以满足运算的需求;在集群上面部署了盘古分布式存储系统,用于存储海量数据,达到PE级别以上;在分布式存储系统之上又搭建了伏羲分布式调度系统,用于管理硬件资源和存储资源,为上层的运算平台提供共享的资源管理系统;为了充分发挥该架构的计算和存储资源,在分布式调度系统上搭建了MaxCompute统一计算引擎,同时为开发者提供统一的开发框架;在运算引擎上搭建了SQL、MR、迭代计算、图计算、流计算。
MaxCompute面临的挑战
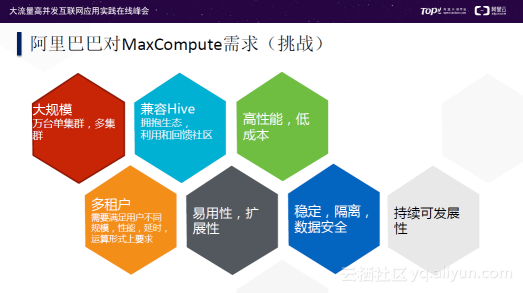
阿里巴巴对MaxCompute的挑战有以下几点:
- 大规模,首先单个集群规模要大,达到万台级别;其次多集群共同运行。
- 兼容Hive,拥抱生态,利用和回馈社区,拥抱开源。
- 高性能,低成本。
- 多租户,需要满足用户不同规模、性能、延时、运算形式上要求。
- 易用性,扩展性,目标是降低开发门槛,开发人员无需过多理解平台即可写出高效的算法。
- 稳定和隔离,确保数据安全。
- 持续可发展性,平台需要根据硬件和业务的变化持续不断地发展。
MaxCompute应对挑战的具体实践
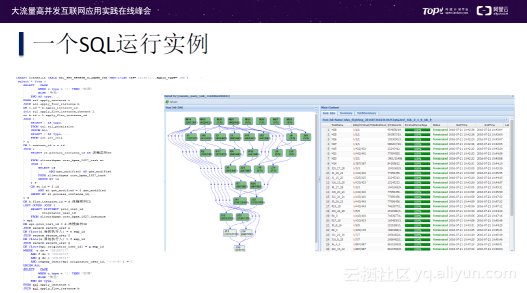
首先来看一个SQL运行实例,从上图左侧可以看到该SQL有着复杂的运行逻辑,该任务经过优化器和编译器后编译成可执行的plan,如上图中间的戴尔图所示,包含上万个WorkTask;图中最右侧显示了Stage中每个WorkTask运行状况。
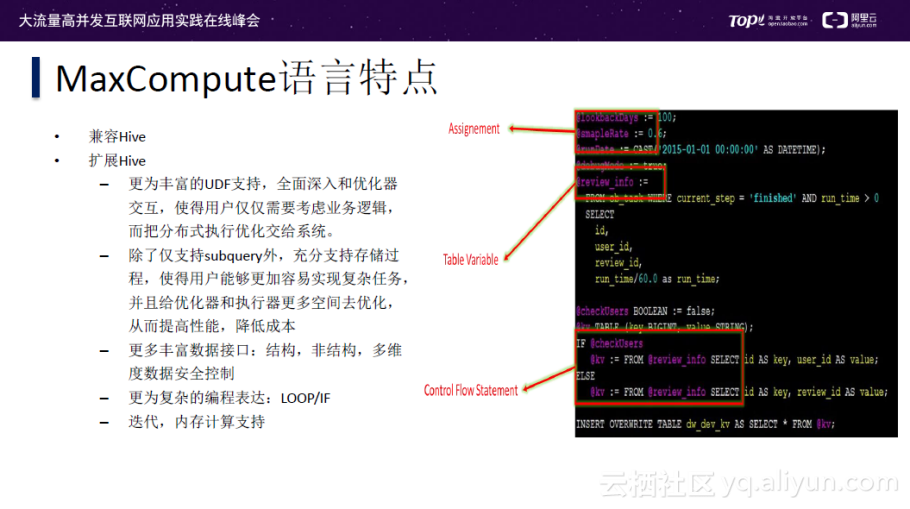
MaxCompute的语言特点包括下面几点:
- 兼容Hive
- 扩展Hive
- 更为丰富的UDF支持,全面深入和优化器交互,使得用户仅仅需要考虑业务逻辑,而把分布式执行优化交给系统。
- 除了仅支持subquery外,充分支持存储过程,使得用户能够更加容易实现复杂任务,并且给优化器和执行器更多空间去优化,从而提高性能,降低成本
- 更多丰富数据接口:结构,非结构,多维度数据安全控制
- 更为复杂的编程表达:LOOP/IF
- 迭代,支持内存计算
MaxCompute查询优化器

下面来看一下MaxCompute查询优化器,主要包括两种类型:RBO和CBO。
RBO是基于规则的优化器,在早期的MaxCompute中使用,是一种过时的优化器框架,它只认规则,对数据不敏感。优化是局部贪婪,容易陷入局部优化但全局差的场景,容易受应用规则的顺序而生产迥异的执行计划,往往结果不是最优的。
CBO是基于代价的优化器,它实际上是Volcano模型,可以展开各种可能等价的执行计划,然后依赖数据的统计信息,计算这些等价执行计划的代价,最后从中选用Cost最低的执行计划。
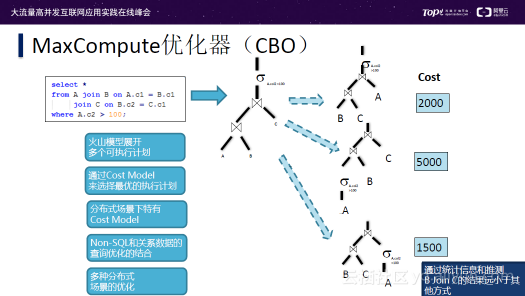
MaxCompute最新优化器是CBO优化器,上图是CBO优化器工作的过程。在优化过程中,CBO优化器会展开多个等价树,所有的等价树都是可执行计划;之后通过Cost Model来选择最优的执行计划。
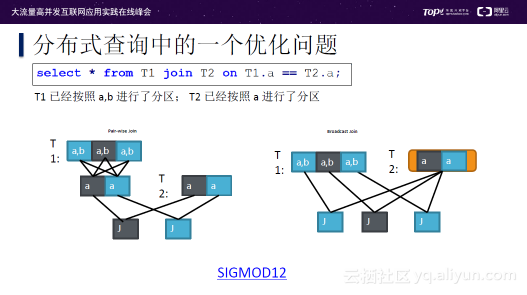
分布式场景的优化有别于单机优化。上图是在两张表上进行Join操作的简单案例,假设表T1已经按照a,b进行了分区;表T2按照a进行了分区。如果在单机系统中,分区问题不会出现;在分布式系统中,因为分区的出现可能会产生两个不同的执行计划:第一个执行计划是将T1按照a进行重新分区,之后再和T2进行Join;另一种执行计划是假设T1很大,而T2相对没那么大,此时不对T1重新进行分区,而是将T2数据广播给T1的每个分区。两种执行计划在不同的环境各具优势。
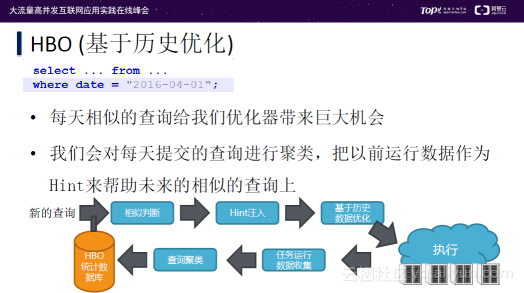
在大流量、高并发场景中,每天都需要处理大量相似的查询,这就给优化器带来了巨大机会。HBO优化器是基于历史优化的优化器,对每天提交的查询进行聚类,把以前运行数据作为Hint来帮助未来的相似的查询上。
全局调度
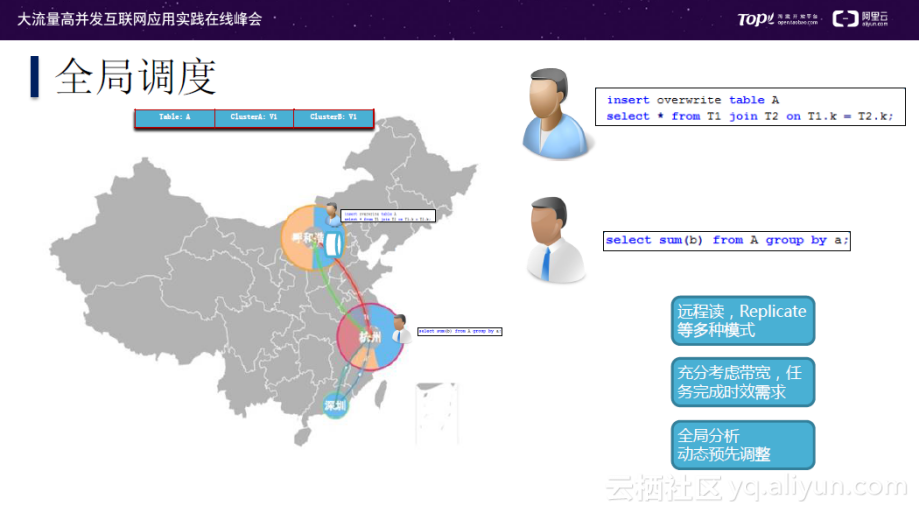
MaxCompute在多集群上进行了全局调度的优化。当两个数据中心的集群内都存有用户所需要操作的表,并且版本一致时:当用户1的更新请求提交到离其最近的数据中心A时,数据中心A集群的表版本会升级,进而导致两个集群的版本不一致;当用户2需要读取该表时,由于位置距离另一个数据中心B较近,请求会提交到数据中心B,但数据中心B集群内表版本已过期。此时,系统会被触发,发现两者的不同,进而将表数据从数据中心A调度到数据中心B内。
在大数据操作上有很多其他操作方式,如远程读、Replicate等模式,但这些方式需要充分考虑带宽、任务完成时效需求等。
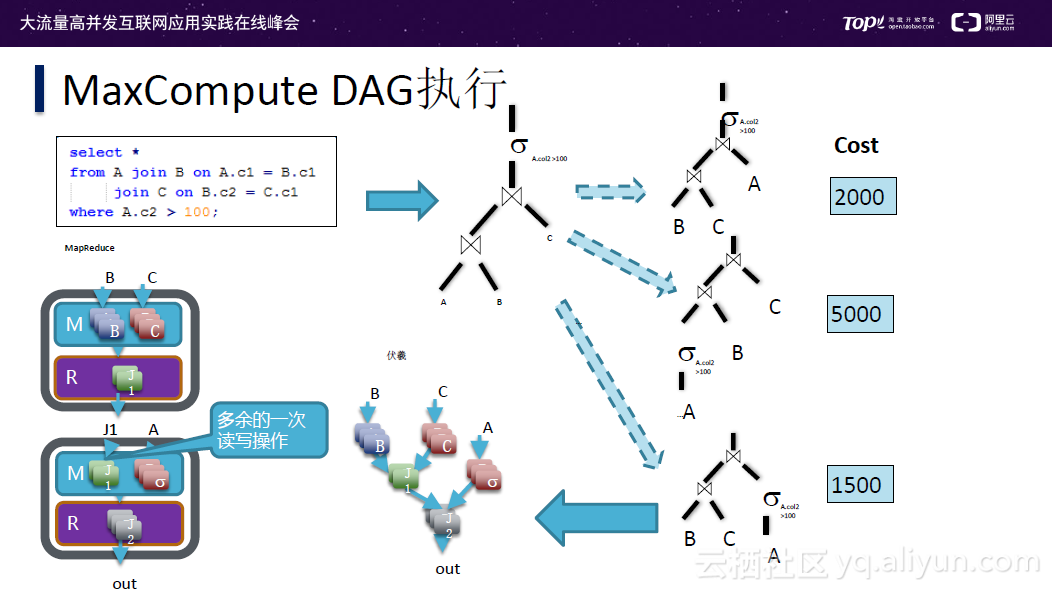
执行计划最后变成一个DAG,上图示例中DAG与MapReduce的区别在于:DAG少了一次多余的读写操作。
资源调度的挑战
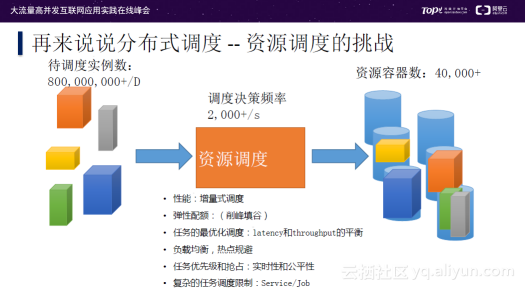
下面来看看分布式调度的资源调度挑战。每天需要调度的实例非常多,达到百亿级别,同时又有多达万台单集群的资源容器,如何快速有效地将实例调度到容器中是我们亟需解决的一个问题。因为,这其中调度决策频率是非常高的,达到2000+/秒,并且还需要考虑调度的机器是否最适合目标实例。
调度器一般采用增量式调度,当调度实例不是最优时,需要考虑Latency和Throughput的平衡;还需要考虑负载均衡,热点规避;同时还需要注意任务优先级的实时性和公平性。
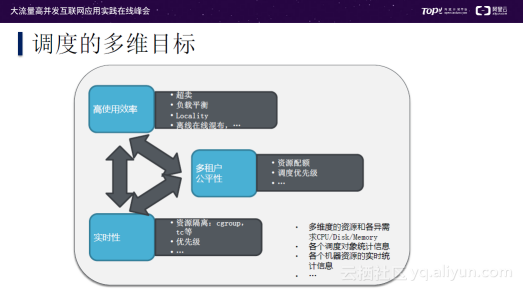
调度是一个非常难的问题,在分布式计算平台上调度的目标分为多个维度:第一个维度是高使用效率;第二个维度是多租户公平性;第三个维度是实时性。各维度要求之前有时是相互矛盾的,例如提升使用效率时会牺牲公平性和实时性。为了达到最好的调度效果,需要对多维度的资源和各异需求CPU、Disk、Memory进行分析;并对各调度对象统计信息,各机器资源实时统计信息。

大规模下任务调度也面临着很多挑战,第一点数据交换,当上万个Partitioner和上万个aggregator,但连接边就可能达到百万级别;第二点是长尾的检测以及Duplicate Execution触发;第三点是调度,数万台机器以及每天数百万级别的Job,数百亿级别的Task,高效调度也是一个难题。
运行时优化
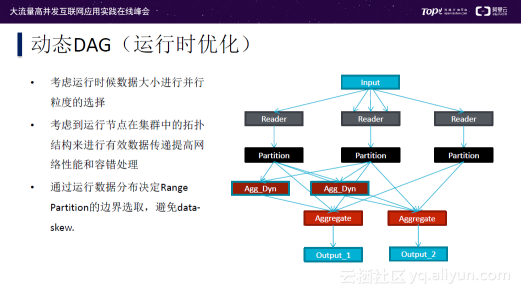
除了调度优化之外,很多情况下需要动态DAG(运行时优化):
- 考虑运行时候数据大小进行并行粒度的选择;
- 考虑到运行节点在集群中的拓扑结构来进行有效数据传递提高网络性能和容错处理;
- 通过运行数据分布决定Range Partition的边界选取,避免data-skew。
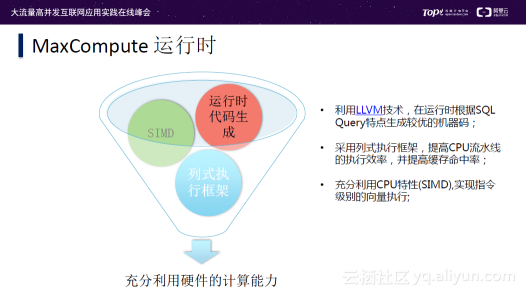
除了单个Job调度上的优化,同时还有MaxCompute运行时的优化,通常利用LVM技术,在运行时根据SQL Query特点生成较优的机器码;采用列式执行框架,提高CPU流水线的执行效率,并提高缓存命中率;充分利用CPU特性(SIMD),实现指令级别的向量执行。充分利用硬件的计算能力,提高单点的运算效率。
持续改进和发布中的挑战

MaxCompute每天都有百万级别的作业,在新的功能不会造成线上故障前提下,持续不断地改进和发布系统是一个很高要求的挑战。同时,由于计算集群十分庞大,重新搭建一个规模相当的测试集群是不可取的方式。
安全性方面,MaxCompute从第一天就强调安全性,在测试模拟用户的场景时需要将用户的数据迁移到测试环境中,这其中就涉及到数据脱敏的过程,进而引发一系列的问题。因此,处理可测性和安全性之间的矛盾也是一个难点。
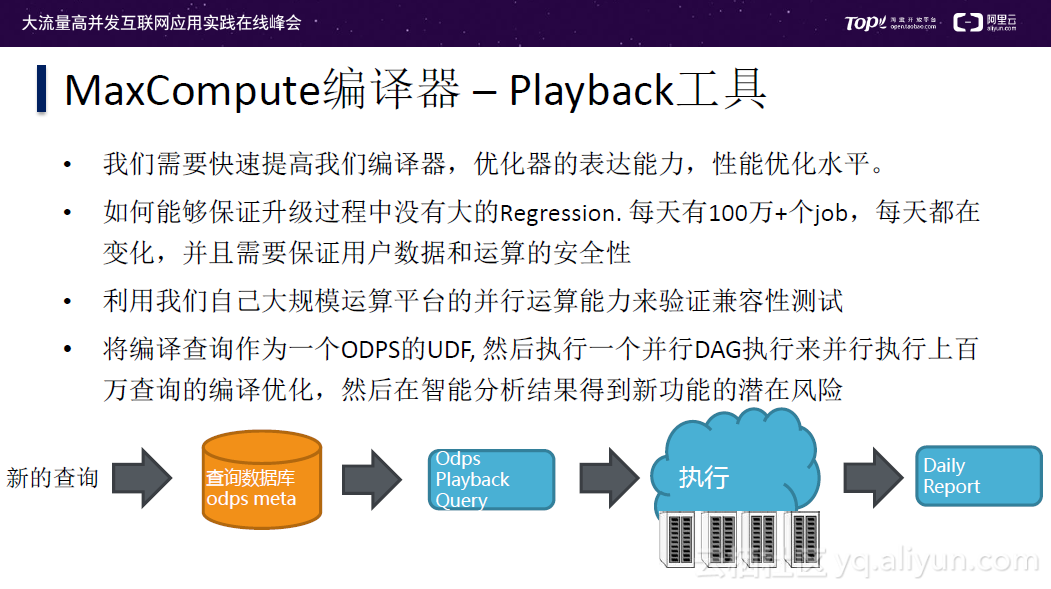
目前的解决方案有两种:第一种是通过Playback编译器,利用大规模运算平台的并行运算能力来验证兼容性测试,具体做法是将编译查询作为一个ODPS的UDF,然后执行一个并行DAG来执行上百万查询的编译优化,然后在智能分析结果得到新功能的潜在风险。
如上流程图所示,一个新的查询发送至查询数据库中;当有新版本发布时,执行ODPS的Playback Query,然后执行之前所有任务的查询,并查看查询计划是否符合预期。

第二种是MaxCompute Flighting工具,用于保证MaxCompute优化器和运行器正确执行,避免快速迭代中的正确性问题,从而避免重大的事故,同时还能保证数据安全性。由于企业不可能构建一个离线的规模相当的测试集群,并且利用测试集群进行相应的测试会导致资源的大量浪费,在数据安全的上,需要脱敏来拖数据、改变查询行为、触及用户数据,并且不能做对等测试,过程复杂冗长,不能达到测试目的。
因此我们给出的方法是线上测试,通过伏羲的资源控制和好的隔离、优先级管理,在线上利用1%的资源分配给测试用户组,对用户而言是非常透明的,并且不需要脱敏数据来进行测试数据的准备,安全性也随之提升。此外,由于动态调度,当无需测试时,1%的资源可以被分配真正的生产用户加以利用,充分发挥系统的资源利用率。
关于分享嘉宾:
林伟:阿里云大数据计算平台资深架构师,阿里云大数据计算平台MaxCompute首席架构师。具有大规模并发系统有10年以上的系统架构设计及研发经验,并在国际一流ODSI、NSDI、SIGMOD会议上多次发表论文。
欢迎加入“数加·MaxCompute购买咨询”钉钉群(群号: 11782920)进行咨询,群二维码如下:


阿里巴巴大数据-玩家社区 https://yq.aliyun.com/teams/6/
---阿里大数据博文,问答,社群,实践,有朋自远方来,不亦说乎……

