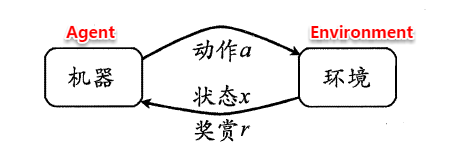
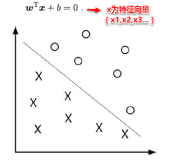
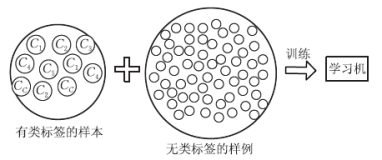
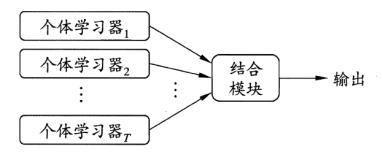
11.何时修改开发集、测试集和度量指标
开展一个新项目,尽快选好开发集和测试集;例子,根据度量指标A分类器排在B分类器前面,但是团队认为B分类器在实际产品上优于A分类器,这时就需要考虑修改开发集和测试集,或者评价指标了。
有三个主要原因可能导致A分类器的评分较低:
(1)你需要处理实际数据的分布和开发集、测试机数据的分布情况不同。
(2)你的开发集上过拟合。
(3)该指标所度量的不是项目应当优化的目标。
12小结:建立开发集和测试集
(1)选择作为开发集和测试集的数据,应当与你预期在将来获取并良好处理的数据有着同分布,但不需要和训练数据的分布一致。
(2)开发集和测试集的分布应当尽可能一致。
(3)选择单一评价指标进行优化,需要考虑多项目标时,不妨将他们整合到一个表达式里面(比如对多个误差指标取平均值),或者定义满意度指标和优化指标。
(4)机器学习是一个高速迭代的过程:在最终令人满意的方案出现前,你可能要尝试很多想法。
(5)拥有开发集、测试集和单值评价指标可以帮助你迅速评估一个算法,从而加速迭代过程。
(6)当你探索一个全新的应用时,尽可能在一周内建立你的开发集、测试集和指标,而在成熟的应用上则可以花费更长的时间。
(7)传统的70%/30%训练集、测试集划分对大规模数据并不适用,实际上开发集和测试集的比例会远低于30%.
(8)开发集的规模应当大到能够检测出算法精度的细微改变,但也不用太大;测试集的规模应当大到能够使你对系统的最终性能作出一个充分的估计。
(9)当开发集和评估指标不再能给团队一个正确的导向时,就尽快修改它们:(i)如果你的开发集上过拟合,则获取更多的开发集数据。(ii)如果开发集和测试集的数据分布和实际关注的数据分布不同,则获取新的开发集和测试集。(iii)如果评价指标不能够对最重要的任务目标进行度量,则需要修改评价指标。
13.快速构建并迭代你的第一个系统
案例:面对要构建一个新的垃圾邮件过滤系统时,可能会有很多不同的想法,这时候首要的不是全面考虑,而是尽快先构建一个最基础的系统。再从这个系统的结果中找出下一步该怎么走的线索(指导方针)。
14.误差分析:根据开发集样本评估想法
误差分析(Error Analysis)指的是检查算法误分类的开发集样本的过程,以便找到造成这些误差的原因。这将帮助你确定项目优先级,即找到什么原因造成误差占比最大,这时去优化它才最有意义,而不是盲目的去优化某一个原因。
15.在误差分析时并评估多个想法
利用电子表格来统计,误分类样本(如100张)分别因为什么而发生误分类,可能一张图有多个原因(如是狗而且很模糊),最终统计各原因占比,选择大的进行优化。
16.清洗误标注的开发集和测试集样本
还是根据以上原理,查看误标注样本对误分类造成的影响所占比例,然后判断是否要去修正,如果修正,务必将这种修正方法用到测试集上,这样才能保证一致性。
17.讲大型开发集拆分为两个子集,专注其一
比如有5000张大型开发集,有20%误差,即有1000张误分类,这是全部进行误差分析,非常耗时,故可以选取500张开发集(约有100张误分类)作为Eyeball开发集,其余4500张作为Blackbox开发集,前者因为已经观察过了,所以很容易过拟合,通过后者进行验证可以准确知道前者何时开始过拟合了,这时应该丢弃或者寻找新的Eyeball开发集或者将后者逐步移入到前者中去。
18.Eyeball和Blackbox开发集该设置多大
Eyeball开发集应该大到能够让你对算法主要的错误类别有所察觉,分类器的误差越小,所需要的EYeball开发集需要越大,才能满足前面第一句话的要求;如果面对的是人类也做不好的任务,那么检车Eyeball开发集将不会有打的版主,因为很难找出算法不能准确分类一个样本的原因。
Blackbox开发集的大小相对于Eyeball没那么重要,有时候可能甚至没有(此时因为Eyeball需要很大的开发集),这是只是造成过拟合分风险比较大。
19.小结:基础误差分析
(1)当你开始一个新项目,尤其是在一个不擅长领域是,很难正确猜测出最有前景的方向。
(2)所以,不要在一开始就师徒设计和构建一个完美的系统。相反,应尽可能(可能在短短几天内)的构建和训练一个基本系统,然后使用误差分析帮助你识别出最有前景的方向,并据此不断迭代改进你的算法。
(3)通过手动检查约100个算法错误分类的开发集样本来执行误差分析,并且计算主要的错误类别,用这些信息来确定优先修正哪种类型的错误。
(4)考虑讲开发集分为人为检查的Eyeball开发集和非人为检查的Blackbox开发集。如果在Eyeball开发集上的性能比在Blackbox开发集上好很多,那么你已经过拟合Eyeball开发集,并且应该考虑为其获得更多的数据。
(5)Eyeball数据即应该足够大,以便于算法有足够的错误分类样本供你分析。对很多应用来说,含有1000-10000个样本的Blackboxk开发集已足够。
(6)如果你的开发集不够大到可以按照这种方式进行拆分,那么就使用Eyeball开发集用于人工误差分析,模型选择和调参数。
20.偏差和方差:误差的两大来源
大前提:假设你的训练集、开发集和测试集都来自相同的分布。单纯去获取跟多训练数据是否可取?
以下初略的定义偏差和方差(总误差=偏差+方差):
偏差:训练集的误差;方差:测试集的误差减去训练集的误差(即测试集比训练集差了多少);例子:比如一个分类器,训练集的误差是15%,测试集的误差是16%,那么偏差为15%,方差为1%,此时属于高偏差,单纯增加数据量是无济于事的。