欢迎关注大数据和人工智能技术文章发布的微信公众号:清研学堂,在这里你可以学到夜白(作者笔名)精心整理的笔记,让我们每天进步一点点,让优秀成为一种习惯!

一、Sqoop的简介:
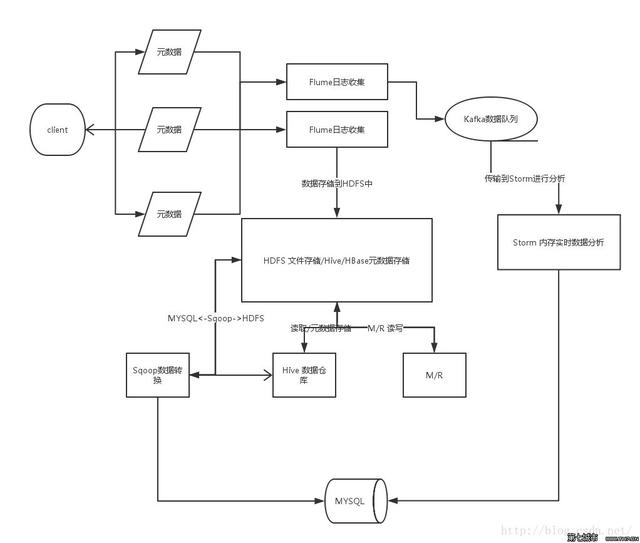
Sqoop是一个数据采集引擎/数据交换引擎,采集关系型数据库(RDBMS)中的数据,主要用于在RDBMS与HDFS/Hive/HBase之间进行数据传递,可以通过sqoop import命令将RDBMS中的数据导入到HDFS/Hive/HBase中,也可以通过sqoop export命令将HDFS/Hive/HBase中的数据导入到RDBMS中,特点:批量采集数据,底层依赖于MapReduce程序,工作原理:通过JDBC连接到关系型数据库(RDBMS)。
二、Sqoop的实验条件:
实验条件:安装Windows XP操作系统和oracle数据库。
为什么要选择关系型数据库中的oracle数据库呢?
原因:1、在windows系统上安装oracle数据库比在linux系统上更简单。2、oracle数据库中的SH用户含有sales订单表,表中包含92万条记录,SCOTT用户含有现成的员工表emp.csv和部门表dept.csv。
三、各种数据库对应的驱动类名和URL格式:
数据库 驱动类名 URL格式 端口号
oracle oracle.jdbc.OracleDriver jdbc:oracle:thin:@IP:1521:orcl 1521
mysql com.mysql.jdbc.Driver jdbc:mysql://IP:3306/dbname?name=value 3306
hive org.apache.hive.jdbc.HiveDriver jdbc:hive2://IP:10000/dbname 10000
四、安装和配置Sqoop:
注:不需要修改配置文件
1、安装sqoop:tar -zxvf sqoop-1.4.5bin_hadoop-0.23.tar.gz -C ~/training
2、配置SQOOP_HOME环境变量:
export SQOOP_HOME=/root/training/sqoop-1.4.5bin_hadoop-0.23
export PATH=$SQOOP_HOME/bin:$PATH
五、使用sqoop语句采集RDBMS中的数据:
1、导入员工表EMP中的所有数据:
sqoop import --connect jdbc:oracle:thin:@192.168.182.157:1521:orcl --username SCOTT --password tiger --table EMP --target-dir /sqoop/import/emp1
2、导入员工表EMP中的指定列:
sqoop import --connect jdbc:oracle:thin:@192.168.182.157:1521:orcl --usrname SCOTT --password tiger --table EMP -column ENAME,SAL --target-dir /sqoop/import/emp2
3、导入SALES表中的所有数据:
sqoop import --connect jdbc:oracle:thin:@192.168.182.157:1521:orcl --username SH --password sh --table SALES --target-dir /sqoop/import/sales -m 1
4、导入SCOTT用户下的所有表到HDFS中:
sqoop import-all-tables --connect jdbc:oracle:thin:@192.168.182.157:1521:orcl --usernmae SCOTT --password tiger
5、导出HDFS中的数据到RDBMS中:
sqoop export --connect jdbc:oracle:thin:@192.168.182.157:1521:orcl --username SCOTT --password tiger --table STUDENTS --export-dir /students
六、oracle数据库与mysql数据库的区别:
1、oracle数据库区分大小写,需要大写的有:用户名、表名、列名,mysql数据库不区分大小写。
2、oracle数据库只有一个数据库:orcl,在安装oracle数据库时自动创建,mysql数据库有很多数据库。
3、oracle数据库有很多用户,表属于用户,mysql数据库有很多数据库,表属于数据库,数据库对不同用户设置了不同的访问权限。
七、Sqoop与Flume的相同与不同:
相同:sqoop和flume都是数据采集引擎。
不同:sqoop的特点:批量采集数据,flume的特点:实时采集数据,主要用于实时采集系统中。
作者:李金泽AllenLi,清华大学在读硕士,研究方向:大数据和人工智能。




