欢迎关注大数据和人工智能技术文章发布的微信公众号:清研学堂,在这里你可以学到夜白(作者笔名)精心整理的笔记,让我们每天进步一点点,让优秀成为一种习惯!

Pig
一、Pig的介绍:
Pig由Yahoo开发,主要应用于数据分析,Twitter公司大量使用Pig处理海量数据,Pig之所以是数据分析引擎,是因为Pig相当于一个翻译器,将PigLatin语句翻译成MapReduce程序(只有在执行dump和store命令时才会翻译成MapReduce程序),而PigLatin语句是一种用于处理大规模数据的脚本语言。
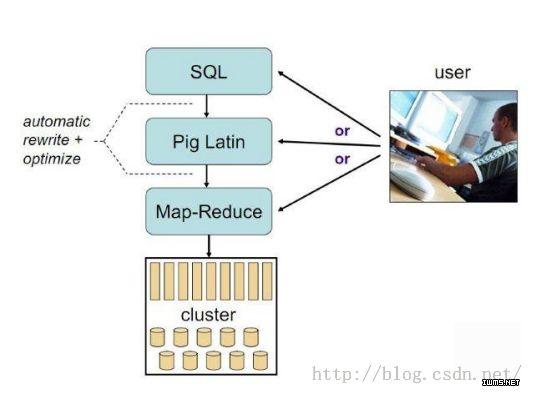
二、Pig与Hive的相同与区别:
相同:
1、Hive和Pig都是数据分析引擎,除此之外,还有Spark中的Spark SQL和Cloudera开发的Impala等。
2、Hive和Pig都简化了MapReduce程序的开发。
不同:
1、Hive作为数据分析引擎有一定限制,只能分析结构化数据,因为Hive的数据模型是表结构,虽然没有数据存储引擎,需要用户在创建表时指定分隔符(默认以Tab键作为分隔符):row format delimited field terminated by ‘,’,而Pig的数据模型是包结构,由tuple和field组成,因此可以分析任意类型的数据。
2、Hive使用的是sql语句分析数据,sql语句是一种声明式语言,Pig使用的是PigLatin语句分析数据,PigLatin语句是一种过程式语言/脚本语句。
3、Hive中的内置函数不用大写,Pig中的内置函数必须要大写。
举例:按照部门号对员工表分组并求每个部门中薪水的最大值:
sql语句:select deptno,max(sal) from emp group by deptno;
PigLatin语句:emp1 = group emp by deptno;
emp2 = foreach emp1 generate group,MAX(emp.sal)
dump emp2;
(PigLatin语句注意事项:等号前后要有空格)
4、Hive保存元信息,因此数据模型不用重建,而Pig不保存元信息,因此数据模型需要重建。
5、由于PigLatin语句是脚本语言,因此Hive执行速度比Pig更快。
6、 由于Hive的数据模型是表结构,因此Hive是先创建表,后加载数据,而Pig的数据模型是包结构,Pig在加载数据的同时创建包。
举例:创建一份员工表
sql语句:
1、创建表:
create table emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal int,
comm int,
deptno int
)row format delimited field terminated by ',';
2、加载HDFS中的数据:
load data inpath '/scott/emp.csv' into table emp;
PigLatin语句:
加载数据的同时创建包:load后加载数据,using后指定分隔符,as后指定包结构
emp=load'/scott/emp.csv'usingPigStorage(',')as(empno:int,ename:chararray,job:chararray,mgr:int,hiredate:chararray,sal:int,comm:int,deptno:int);
三、Hive数据模型和Pig数据模型的差别:
1、Hive的数据模型是表,表由行和列组成,表不可以嵌套,Pig的数据模型是包,包由tuple和field组成,包可以嵌套。
2、表中每一行的列完全相同,包中每一行的列可以不相同,可以动态增加。
四、Pig的安装和配置:
1、安装pig:tar -zxvf pig-0.17.0.tar.gz -C ~/traing
2、配置PIG_HOME环境变量:
export PIG_HOME=/root/training/pig-0.17.0
export PATH=$PIG_HOME/bin:$PATH
五、Pig的安装模式:
1、本地模式:访问本地主机,pig相当于本地的客户端。
2、集群模式:访问Hadoop集群,pig相当于Hadoop的客户端。
注:1、集群模式需要配置PIG_CLASSPATH环境变量,用于连接到Hadoop上:
export PIG_CLASSPATH=/root/training/hadoop-2.7.3/etc/hadoop
2、启动pig的集群模式前,需要先启动historyserver,因为pig在hadoop上执行任务后需要与historyserver通信,解析执行日志确定任务执行是否成功:
mr-jobhistory-daemon.sh start historyserver
六、Pig的常用命令:操作HDFS
ls、cd、cat、mkdir、pwd、copyFromLocal(上传)、copyToLocal(下载)、register、define等。
七、操作Pig:
1、命令行:pig提供了一个shell终端与用户进行交互,用户可以进行增删改查操作。
启动pig命令行模式,进入本地模式:pig -x local
启动pig命令行模式,进入集群模式:pig - x mapredcue/pig
(pig没有API可以操作)
八、常用的PigLatin语句:
load:加载数据
foreach:逐行扫描
generate:提取列
filter:过滤
distinct:去重
order by:排序
group by:分组
join:多表查询
union:联合查询
dump:把结果输出到屏幕上
store:把结果保存到HDFS上
九、使用PigLatin语句分析数据:
创建员工表:load后加载数据,using后指定分隔符,as后指定包结构
emp = load '/scott/emp.csv' using PigStorage(',') as(empno:int,ename:chararray,job:chararray,mgr:int,hiredate:chararray,sal:int,comm:int,deptno:int);
describe emp;
查看员工表:2
SQL:select * from emp;
PL:emp0 = foreach emp generate *;
dump emp0;
创建部门表:
dept = load '/scott/dept.csv' using PigStorage(',') as(deptno:int,dname:chararray,loc:chararray);
查看部门表:
SQL:select * from dept;
PL:dept0 = foreach dept generate *;
dump dept0;
查询员工号、员工名和薪水:
SQL:select empno,ename,sal from emp;
PL:emp1 = foreach emp generate empno,ename,sal;
dump emp1;
根据薪水对员工表排序:
SQL:select sal from emp order by sal;
PL:emp2 = order emp by sal;
dump emp2;
按照部门号对员工表分组并求每个部门中薪水的最大值:
SQL:select deptno,max(sal) from emp group by deptno;
PL:emp3 = group emp by deptno;
emp4 = foreach emp3 generate group,MAX(emp.sal);
dump emp4;
查看10、20、30号部门的员工
SQL:select * from emp where deptno=10;
select * from emp where deptno=20;
select * from emp where deptno=30;
PL:emp5 = filter emp by deptno==10;
dump emp5;
emp6 = filter emp by deptno==20;
dump emp6;
emp7 = filter emp by deptno==30;
dump emp7;
多表查询,查询员工名和部门名:
SQL:select emp.ename,dept.dname from emp,dept where emp.deptno=dept.deptno;
PL:emp8 = join emp by deptno,dept by deptno
emp9 = foreach emp8 generate emp::ename,dept::dname;
dump emp9;
内连接:
C = join A by id,B by id;
外连接:
左外连接:C = join A by id left outer,B by id; #以左侧数据为基准,只返回左侧有的数据
右外连接:C = join A by id right outer,B by id;#以右侧数据为基准,只返回右侧有的数据
全外连接:C = join A by id full outer, B by id;#两侧数据都返回
联合查询,查询10号部门和20号部门的员工:
SQL:select * from emp where deptno=10
union
select * from dept where deptno=20;
PL: emp10 = filter emp by deptno==10;
emp11 = filter emp by deptno==20;
emp12 = union emp10,emp11;
实现wordcount;
加载数据
mydata = load '/output/data2.txt' as (line:chararray);
将字符串分割成单词
words = foreach mydata generate flatten(TOKENIZE(line)) as word;
对单词分组
grpd = group words by word;
统计每组中单词数量
cntd = foreach grpd generate group,COUNT(words);
结果显示到屏幕上
dump cntd;
结果存储到HDFS上
store cntd into '/pig';
常用的大数据工具
作者:李金泽AlllenLI,清华大学在读硕士,研究方向:大数据和人工智能

