欢迎关注大数据和人工智能技术文章发布的微信公众号:清研学堂,在这里你可以学到夜白(作者笔名)精心整理的笔记,让我们每天进步一点点,让优秀成为一种习惯!
一、HBase基本概念:列式数据库
在Hadoop生态体系结构中,HBase位于HDFS(Hadoop分布式文件系统)的上一层,不依赖于MapReduce,那么如果没有HBase这种Nosql数据库会有什么影响呢?传统的关系型数据库由于存储数据有限,且其分布式结构由于本身的特点导致节点数量最大不会超过一百个,例如分布式的oracle数据库只能部署一百个节点等等。那么在当下海量数据的背景下则诞生了列式数据库,而最常见的列式数据库有两种:1、HBase 2、Cassandra。列式数据库,顾名思义是按列来存储数据,意思是HBase表中的字段是可以动态增加的,因此HBase数据库是Nosql数据库。
二、HBase与HDFS、Hive/Pig之间的关系:
由于HDFS作为分布式文件系统,主要用于存储数据,因此它不支持实时访问/随机读写,而HBase数据库支持实施访问/随机读写,因此HBase主要应用于在线数据查询,HDFS主要应用于数据存储,而Hive/Pig作为数据分析引擎,由于底层依赖MapReduce,具有高延迟的特点,因此主要应用于离线数据查询。
三、HBase表的基础知识:
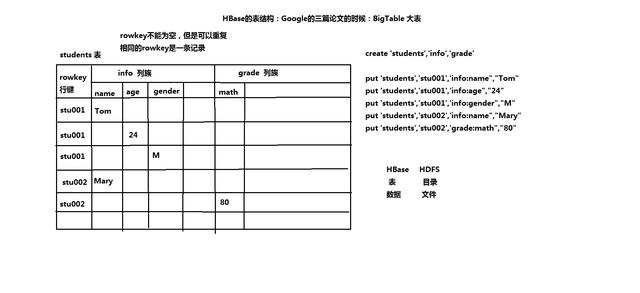
1、表:表是用来存储和管理数据的,表由行和列组成。
2、行键:英文rowkey,不唯一且不为空,作为HBase表的一级索引,特点:相同行键作为一条记录,行键按照字典顺序排序。
3、列族:列的集合,列族是在创建表时定义好的,例:create 'students','info','grade',其中info和grade就是两个列族,而students是这张表的名字,列是在添加记录时动态添加的。
4、时间戳:列的一个属性。
5、单元格:可以存储多个数据,每个数据具有时间戳属性和版本特性(通过时间戳区分数据),这是Hbase表结构独有的特点,而在关系型数据库中,单元格只能存储一个数据。
6、HBase表中的记录按行键拆分形成region,一个行键就是一个region,不同的region分布在不同的regionserver上,对表的查询转换为对多台regionserver的并行查询,通过牺牲存储空间来换取时间性能, 因此Hbase适合海量数据秒级简单查询。
7、region由多个store组成,每个store存储一个列族,store由一个memstore和零到多个storefile组成,memstore保存最近一批数据的更新操作,在HBase写数据的过程中,就是将数据写入memstore中。
(region是分布式存储和负载均衡的最小单元,Hfile是存储的最小单元)
四、Hbase表:
五、Hbase表的特点:
1、大:一张表可以由上亿行,上百万列组成。
2、面向列:HBase表按列保存数据。
3、稀疏:HBase表的空列不占用存储空间。
4、无模式:HBase表中不同行可以有截然不同的列,因为列是在添加记录时动态添加的。
5、数据类型单一:只有字符串这种数据类型。
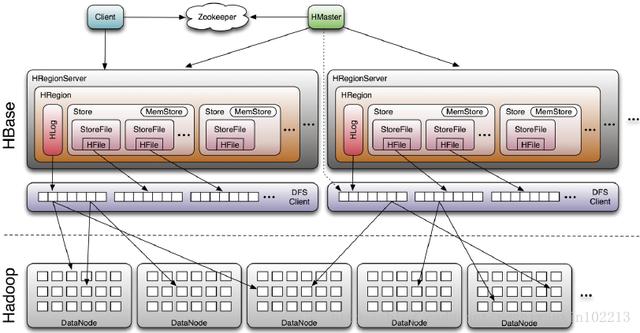
六、HBase的体系结构:
Hmaster:1、为Regionserver分配region。
2、负责Regionserver的负载均衡。
3、发现失效的Regionserver并重新分配其上的region。
4、接收客户端的请求:对HBase表进行增删改查操作。
Regionserver:1、维护region,处理客户端对region的IO请求。
2、负责切分过大的region。
3、定期向Zookeeper汇报心跳信息。
Zookeeper:1、保存HBase集群的结构信息、root表、meta表。
2、实时监控Regionserver并通知给Hmaster。
3、实现HBase的HA功能
(HBase自带一个Zookeeper)
七、安装和配置HBase:
1、安装:tar -zxvf hbase-1.3.1-bin.tar.gz -C ~/training
2、配置HBASE_HOME环境变量:export HBASE_HOME=/root/training/hbase-1.3.1
export PATH=$HBASE_HOME/bin:$PATH
八、HBase的安装模式:与Hadoop相似
1、本地模式:单机没有虚拟出任何节点,只有Hmaster,没有Regionserver,数据存放在本地,修改两个配置文件:hbase-env.sh和hbase-site.xml。
2、伪分布式模式:单机虚拟出多个节点,具备HBase的所有功能,修改两个配置文件:hbase-env.sh和hbase-site.xml。
3、全分布式模式:至少三台机器以上,修改三个配置文件:hbase-env.sh、hbase-site.xml和regionservers。
(比伪分布式模式多一个regionservers)
补充:HBase的http服务端口:16010
九、HBase的读写过程:
1、写过程:HBase表中的记录按行键拆分形成region,不同的region分布在不同的regionserver上,region由多个store组成,每个store保存一个列族,而store又由一个memstore和零到多个storefile组成,数据写入memstore中,memstore保存最近一批数据的更新操作,当memstore保存不下时(128M),会溢写到磁盘中形成storefile文件,当storefile文件数量达到一定阈值时会合并成一个storefile文件,当storefile文件大小大于256M时,region会自动分裂,由Hmaster分配到其他regionserver上,最终storefile文件生成128M的Hfile文件保存到datanode上。
2、读过程:客户端向Hmaster发送请求,从zookeeper中访问root表(-root-)获得表的元信息,访问meta表(.meta.)获得region的元信息,进入region从memstore中寻找数据,如果找不到,则从storefile中寻找数据。
(一句话总结HBase的读写过程:寻址访问zookeeper,数据读写范文Regionserver)
十、HBase上的过滤器:实现复杂查询
十一、HBase上的MapReduce:map的输入是HBase中的一条记录,reduce的输出是HBase中的一条记录。
十二、HBase的HA:单独启动一个Hmaster:hbase-daemon.sh start master。
作者:李金泽AllenLi,清华大学在读硕士,研究方向:大数据和人工智能。
