热门
编译第三方前端项目时候出现Syntax Error: TypeError: Cannot set properties of undefined (setting ‘parent‘)
基于jeecg-boot的flowable流程收回功能实现(全网首创功能)
java mysql druid mybatis-plus里使用多表删除出错的一种处理方式
基于阿里云向量检索 Milvus 版和 LangChain 快速构建 LLM 问答系统
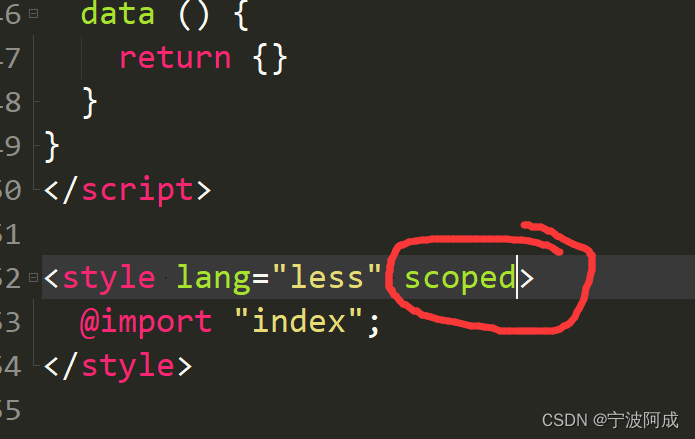
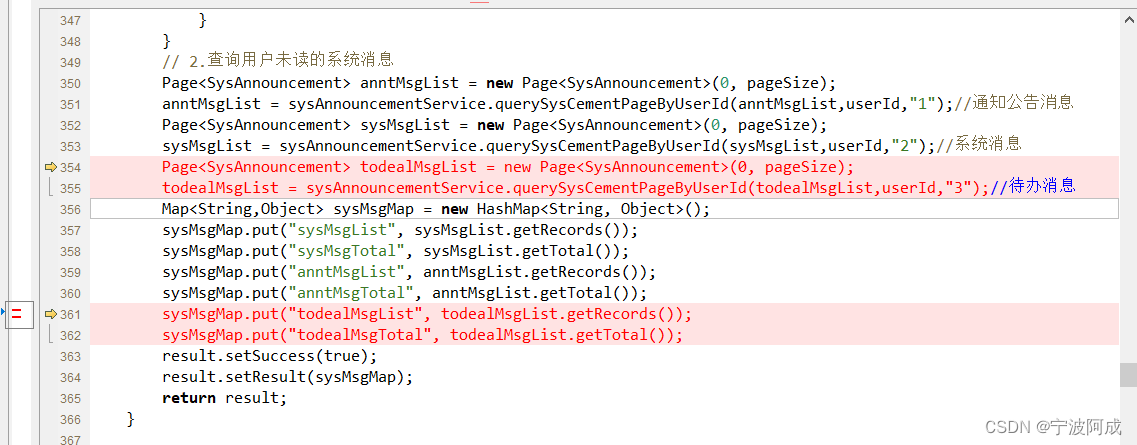
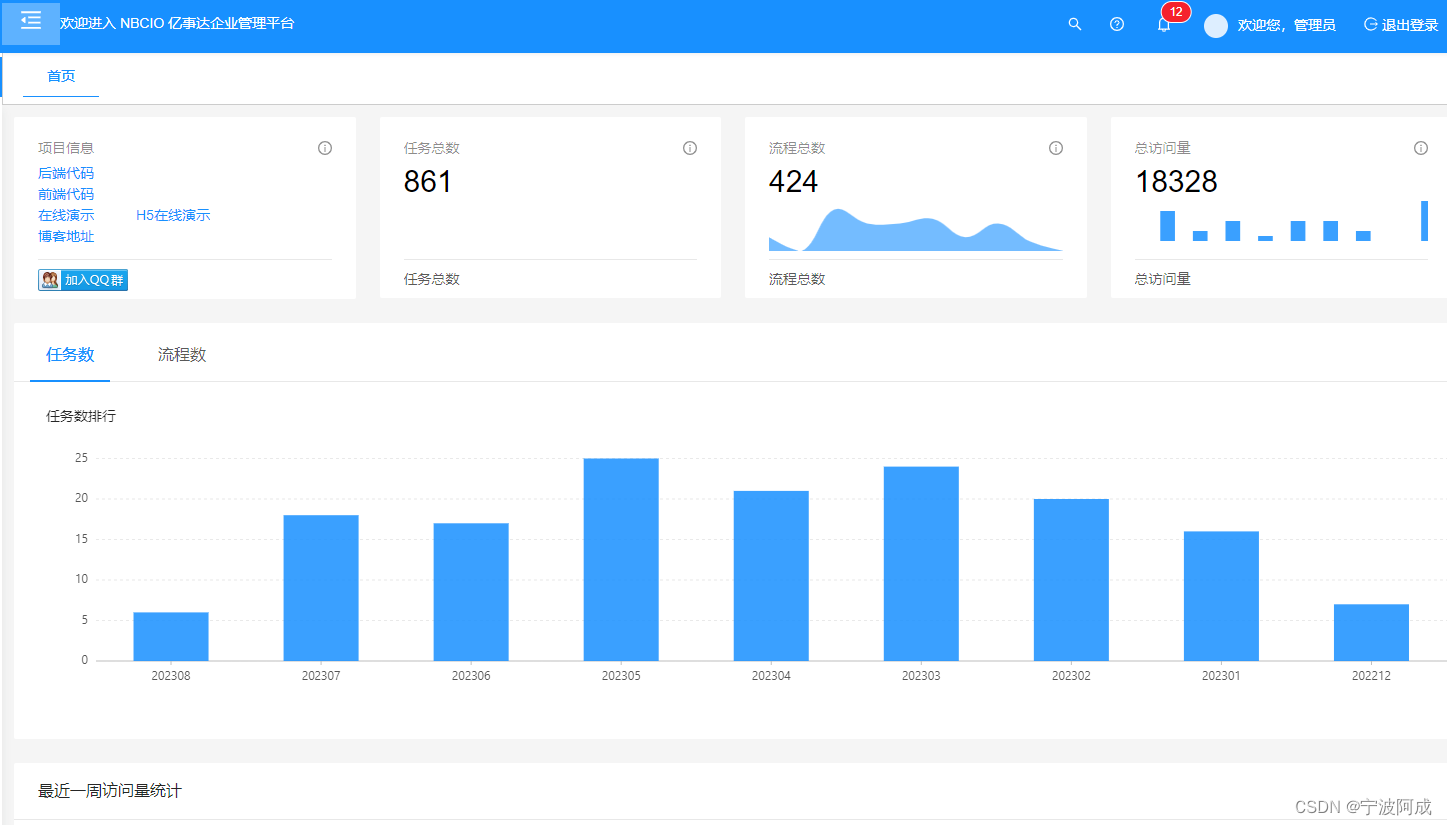
记录一下基于jeecg-boot3.0的待办消息移植记录
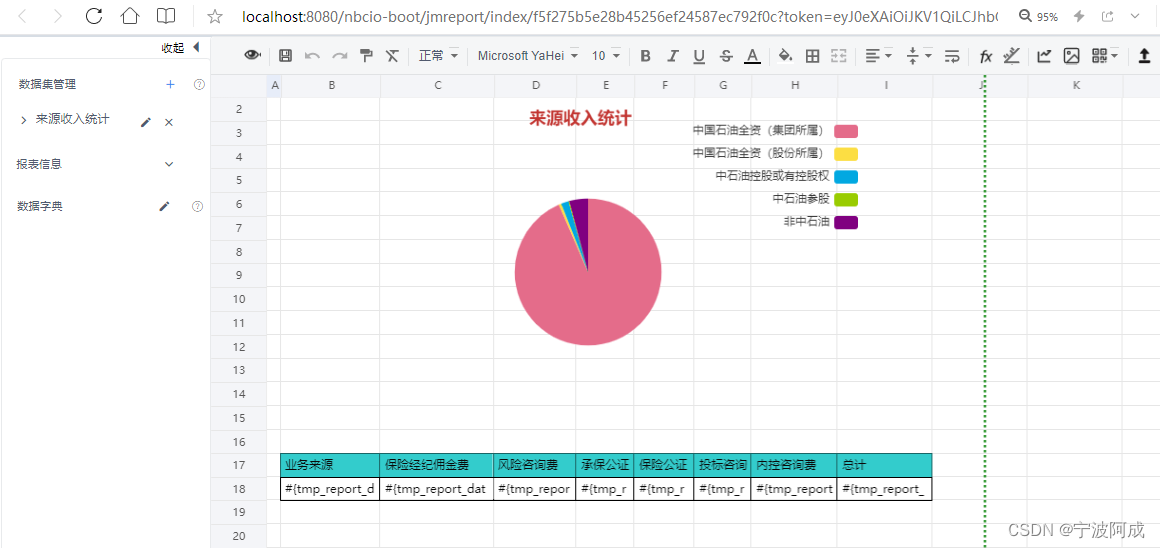
nbcio-boot3.1 解决积木报表基于SSTI的任意代码执行漏洞,积木报表版本从1.4.0升级到最新的1.6.1
nbcio-boot从3.0升级到3.1的出现用户管理与数据字典bug
用墨菲安全来检测我的nbcio-boot项目代码的漏洞
STS(eclipse)批量修改文件里的某个内容
flowable流程移植新项目前端问题汇总
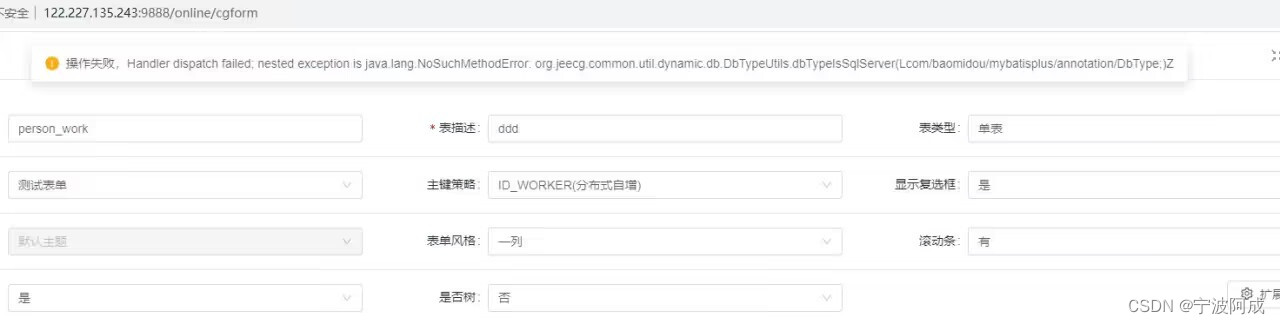
nbcio-boot升级到3.1后出现online表单新增报错
nbcio-boot升级springboot、mybatis-plus和JSQLParser后的LocalDateTime日期json问题
基于jeecg-boot的flowable流程增加部门经理审批功能
基于jeecg-boot的nbcio-boot因升级mybatis-plus到3.5.3.1和JSQLParser 到4.6而引起的在线报表配置报错处理
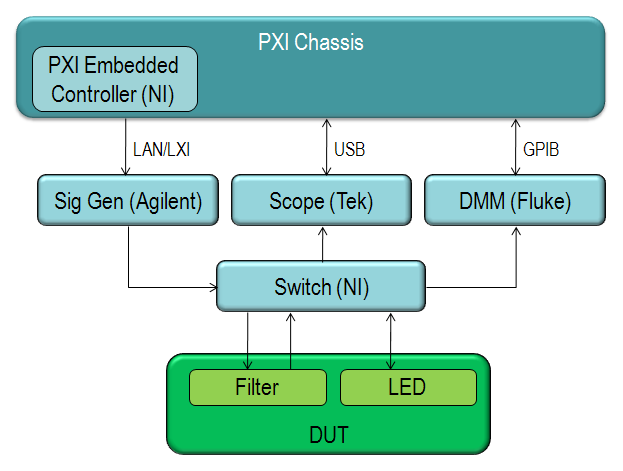
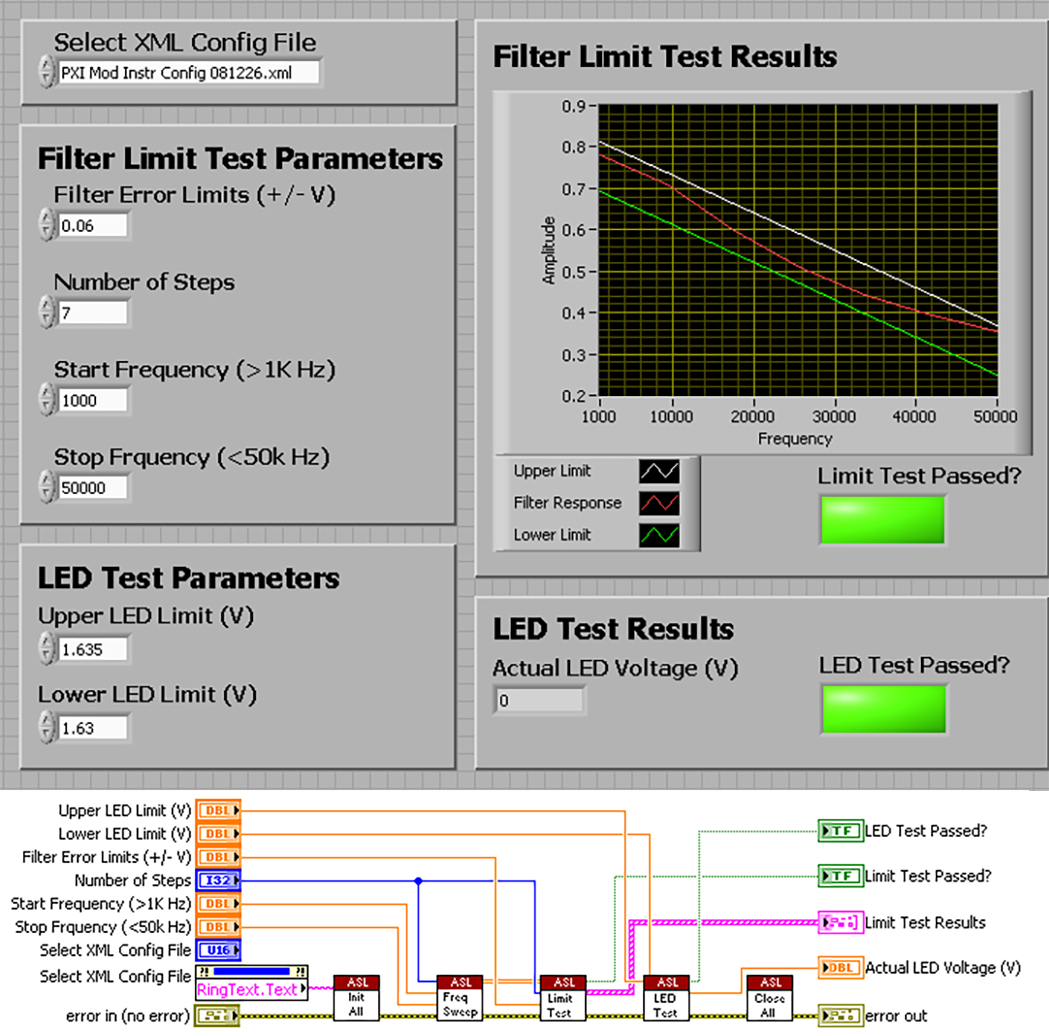
LabVIEW如何减少下一代测试系统中的硬件过时3
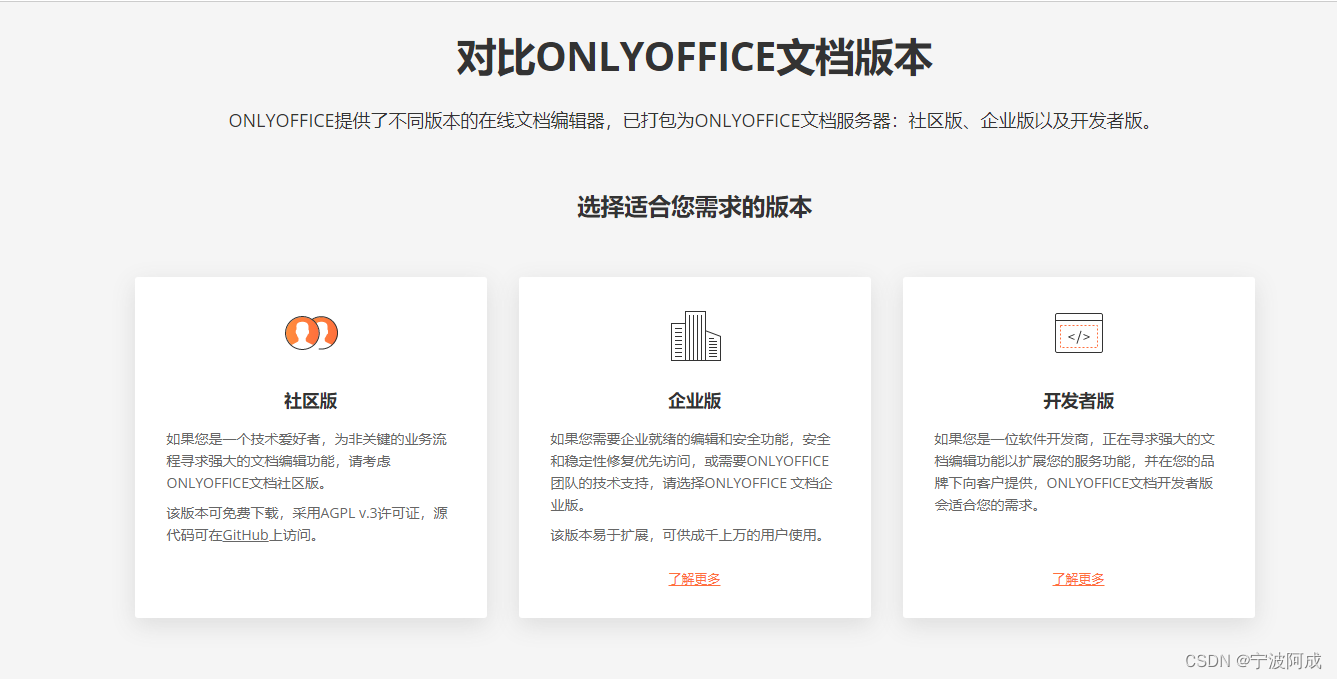
在centos7下通过docker 安装onlyoffice
LabVIEW如何减少下一代测试系统中的硬件过时2
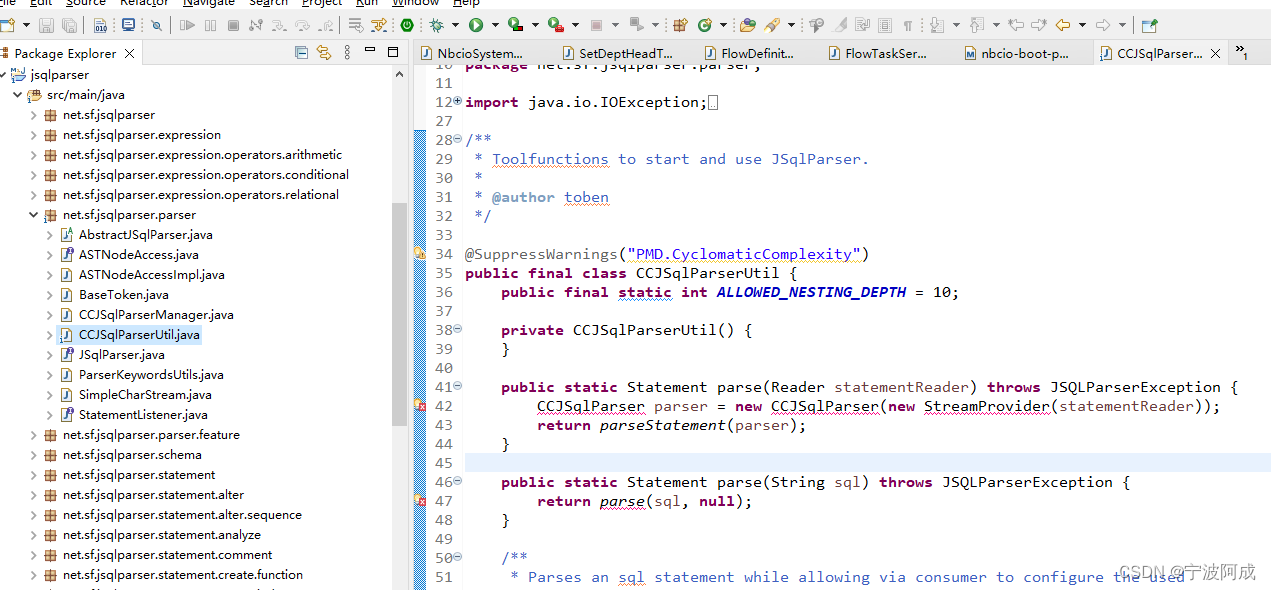
编译JSqlParser4.6-4.7最新源代码
LabVIEW如何减少下一代测试系统中的硬件过时 1
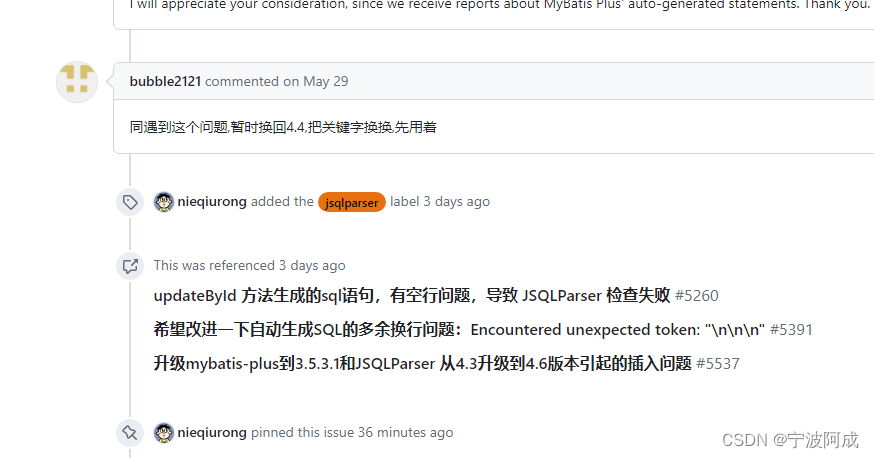
升级mybatis-plus到3.5.3.1和JSQLParser 从4.3升级到4.6版本引起的插入问题解决
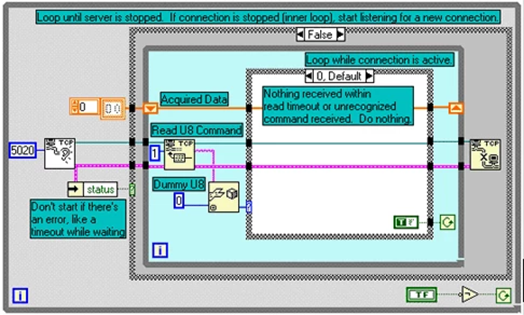
LabVIEW在两台计算机之间传输数据
LabVIEW使用硬件抽象层适应不同的接口
基于jeecg-boot的flowable流程提供一种动态设置发起人部门负责人的方式
LabVIEW中忽略特定错误
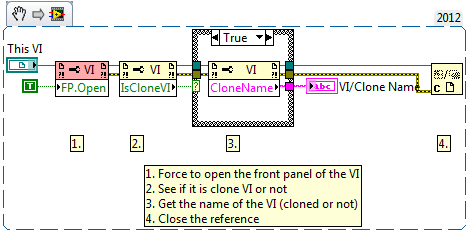
LabVIEW如何以编程方式获取克隆VI名称?
LabVIEW FPGA中可重入和非可重入子VI的区别
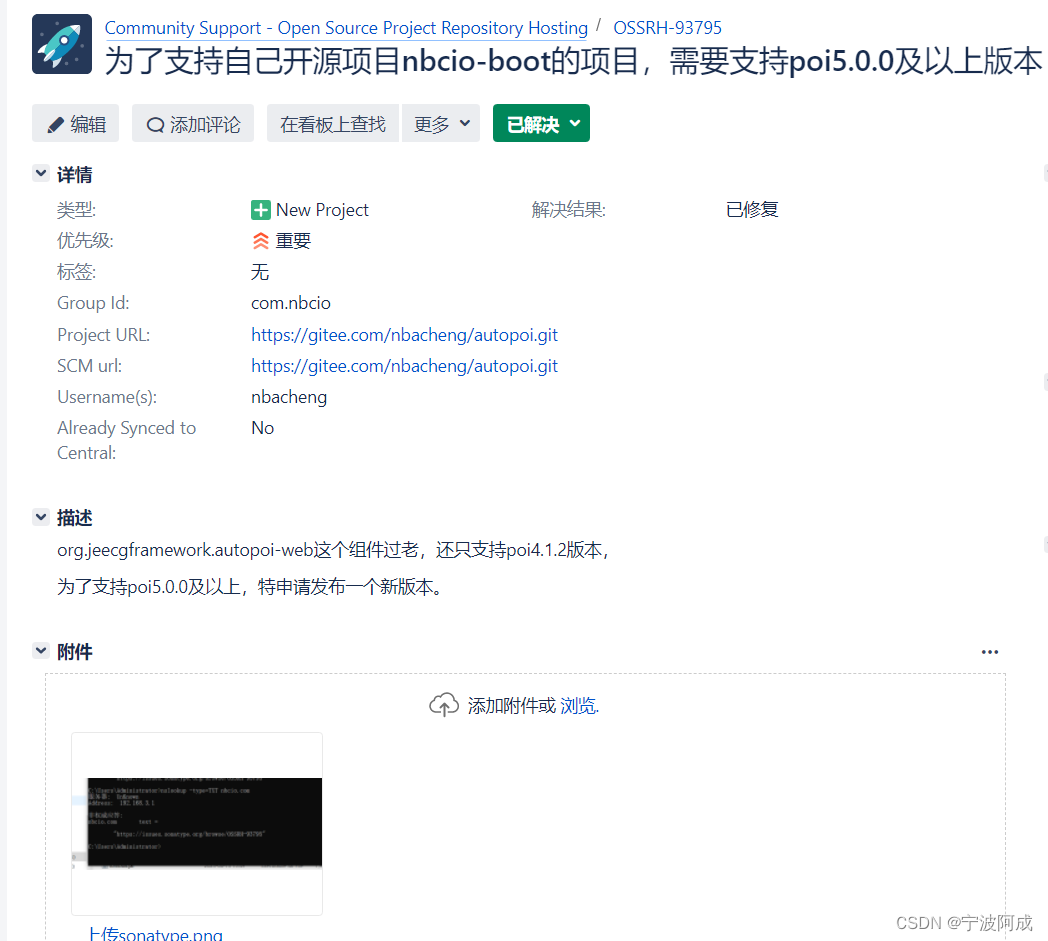
改造升级autoPOI以满足poi5.0.0及以上版本
LabVIEW创建自定义书签管理器
向 Maven 中央仓库上传一个修改过的基于jeecg的autoPOI的 jar包记录(二)
向 Maven 中央仓库上传一个修改过的基于jeecg的autoPOI的 jar包记录(一)
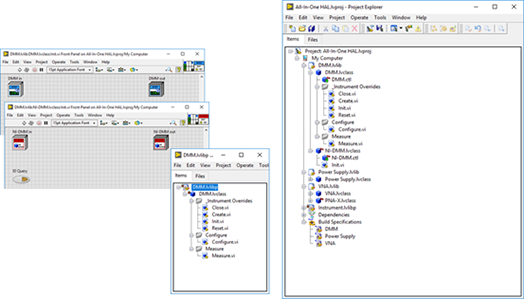
LabVIEW在面向对象编程中利用硬件抽象层(HAL)设计2
LabVIEW在面向对象编程中利用硬件抽象层(HAL)设计1
基于jeecg-boot的任务甘特图显示
jeecg-boot sql注入漏洞解决
LabVIEW编程LabVIEW开发 ADAM-4056 DO模块例程与相关资料
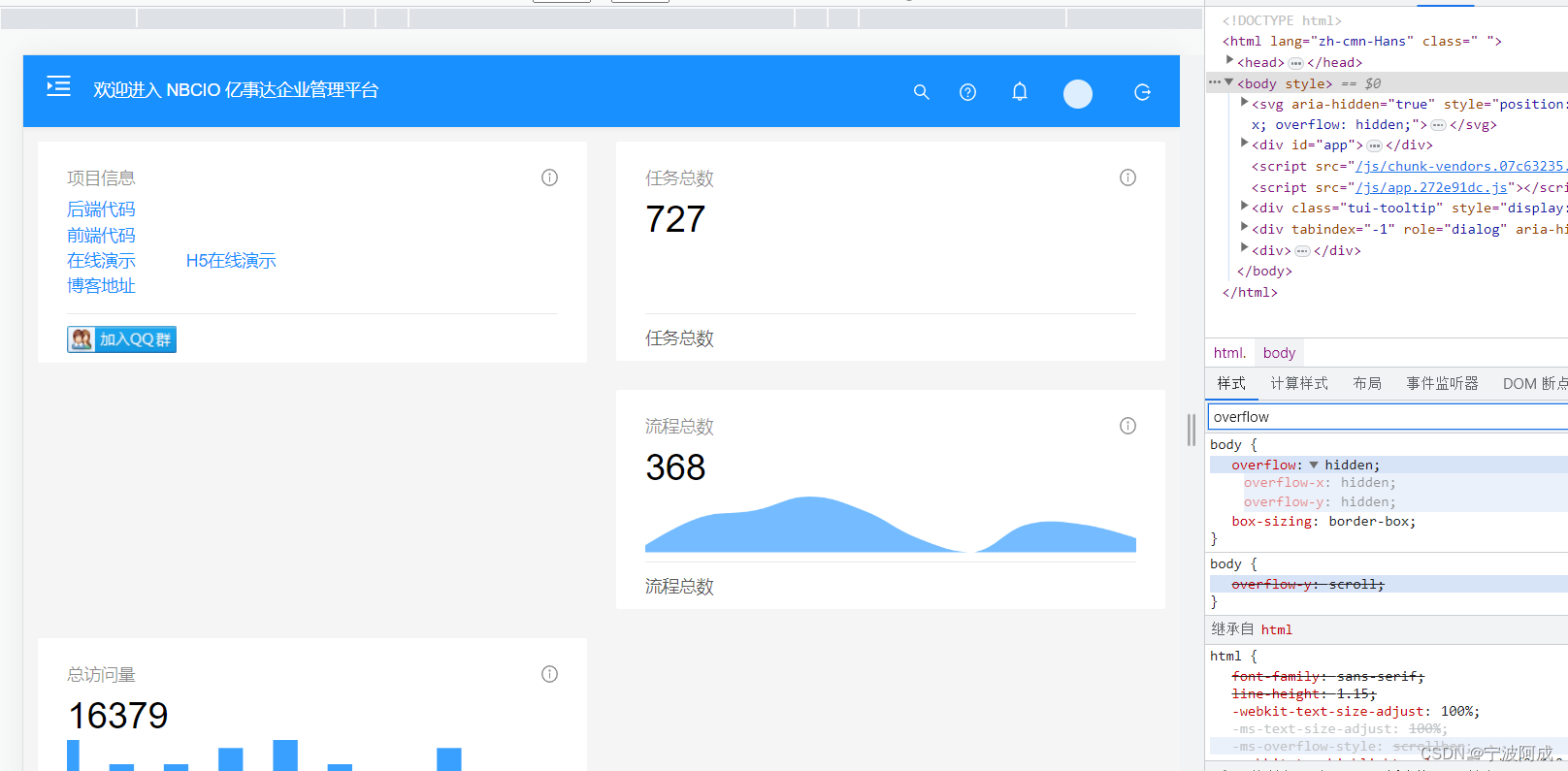
发布项目管理生产的时候出现界面滚动不了
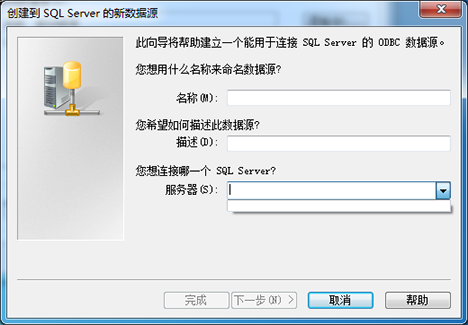
LabVIEW与SQL Server 2919 Express通讯
nbcio-vue中formdesigner的组件显示不正常的处理
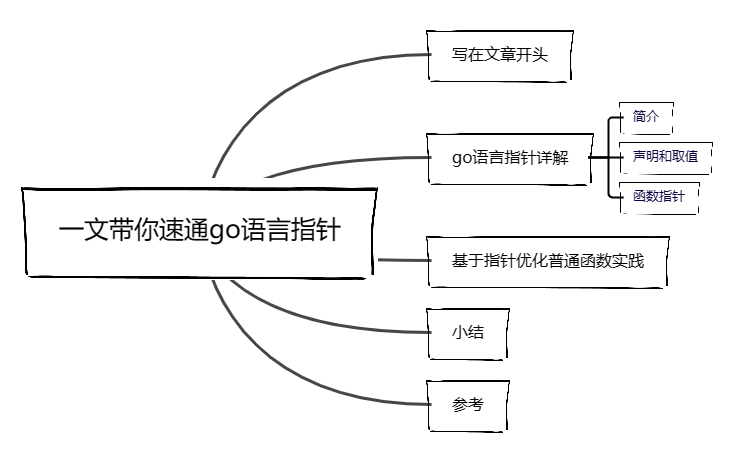
一文带你速通go语言指针
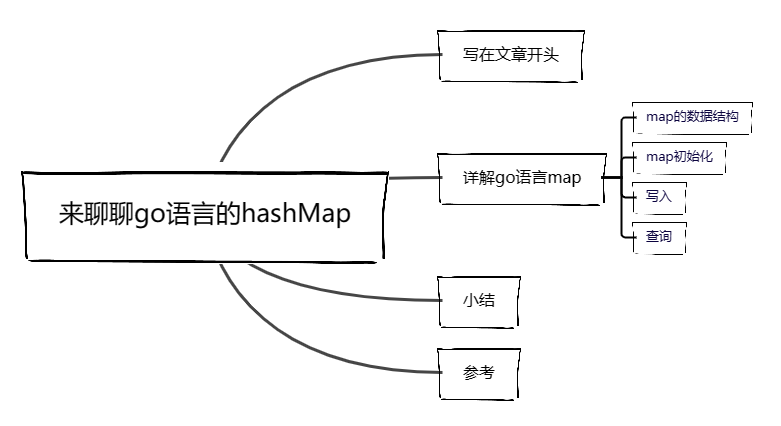
来聊聊go语言的hashMap
LabVIEW编程LabVIEW开发ITECH IT6000D系列电源例程与相关资料
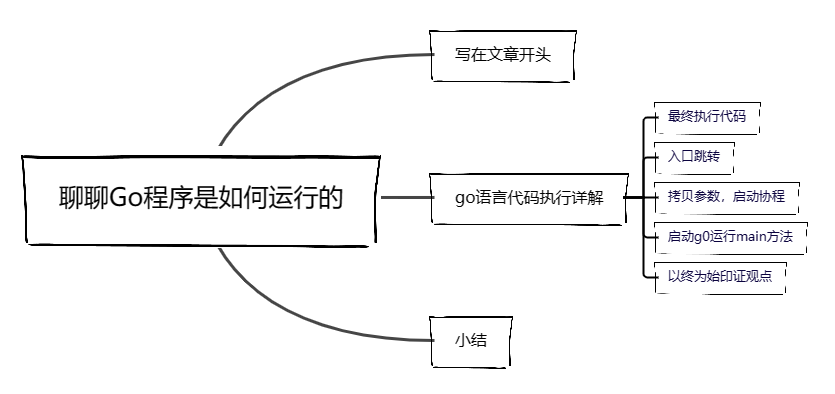
聊聊Go程序是如何运行的
Gitlab回退到指定版本的方法与步骤
LabVIEW在应用程序和接口中使用LabVIEW类和接口
jenkins 自动安装nodejs16.16.0版本报错处理
LabVIEW比较LabVIEW类对象 LabVIEW接口
几个基于springboot在线服务过段时间突然停掉的原因
LabVIEW开发LabVIEW类
基于jeecg-boot的项目管理系统(一、部分数据库)
基于Jeecg-boot的flowable流程支持拒绝同意流程操作(二)