热门
Servlet 教程 之 网站点击计数器 1
Servlet 教程 之 Servlet 点击计数器 1
Servlet 教程 之 Servlet 网页重定向 1
深入分析自动化测试中AI驱动的测试用例生成
构筑未来:云原生技术在企业数字化转型中的关键作用
阿里云ECS使用体验
ECS使用有感
List
YOLO
DataV
探索移动应用开发的未来:跨平台框架与原生操作系统的融合
深度学习在图像识别中的应用与挑战
构建未来:云原生架构在企业数字化转型中的关键作用
网络防御前线:洞悉网络安全漏洞与加固信息防线
移动应用开发的未来趋势:跨平台与原生之争
构建高效微服务架构:后端开发者的终极指南
移动应用与系统:探索未来的可能性
构建高效Android应用:探究Kotlin与Java的性能对比
未来编程:量子计算与量子编程语言的兴起
电子好书发您分享《2023龙蜥操作系统大会浪潮信息分论坛:智算系统软件分论坛》
电子好书发您分享《云原生十大经典案例解读 2024 版》
电子好书发您分享《2023龙蜥操作系统大会统信软件分论坛》
网络防御的三重奏:漏洞管理、加密技术与安全意识提升
构建高效微服务架构的五大关键技术
sql数据库安装过程,SQL数据库的安装过
Python中的面向对象
Yarn介绍及快速安装Debian/Ubuntu Linux
解决http下navigator.clipboard为undefined问题
Ubuntu20.04安装SNMP服务
Nginx-URLRewrite伪静态
快速解决Spring Boot跨域困扰:使用CORS实现无缝跨域支持
SRv6 基本结构
【AI 场景】如何使用 AI 向客户推荐个性化产品?
【AI 场景】人工智能在自然语言理解方面的挑战和解决方案
透视Redis集群:心跳检测如何维护高可用性
【AI 场景】如何开发用于自动驾驶的人工智能系统?
阿里云服务器租用价格表,2024年5月最新报价整理
深度学习在图像识别中的应用及挑战
深入理解操作系统的内存管理
【AI 场景】设计一个 AI 系统来识别和分类图像中的对象
网络安全与信息安全:防御前线的技术与意识
【AI 场景】如何应用 AI 来优化供应链管理
【AI 场景】如何设计一个人工智能系统来预测电信公司的客户流失?
【AI 初识】讨论人工智能的未来趋势和进步
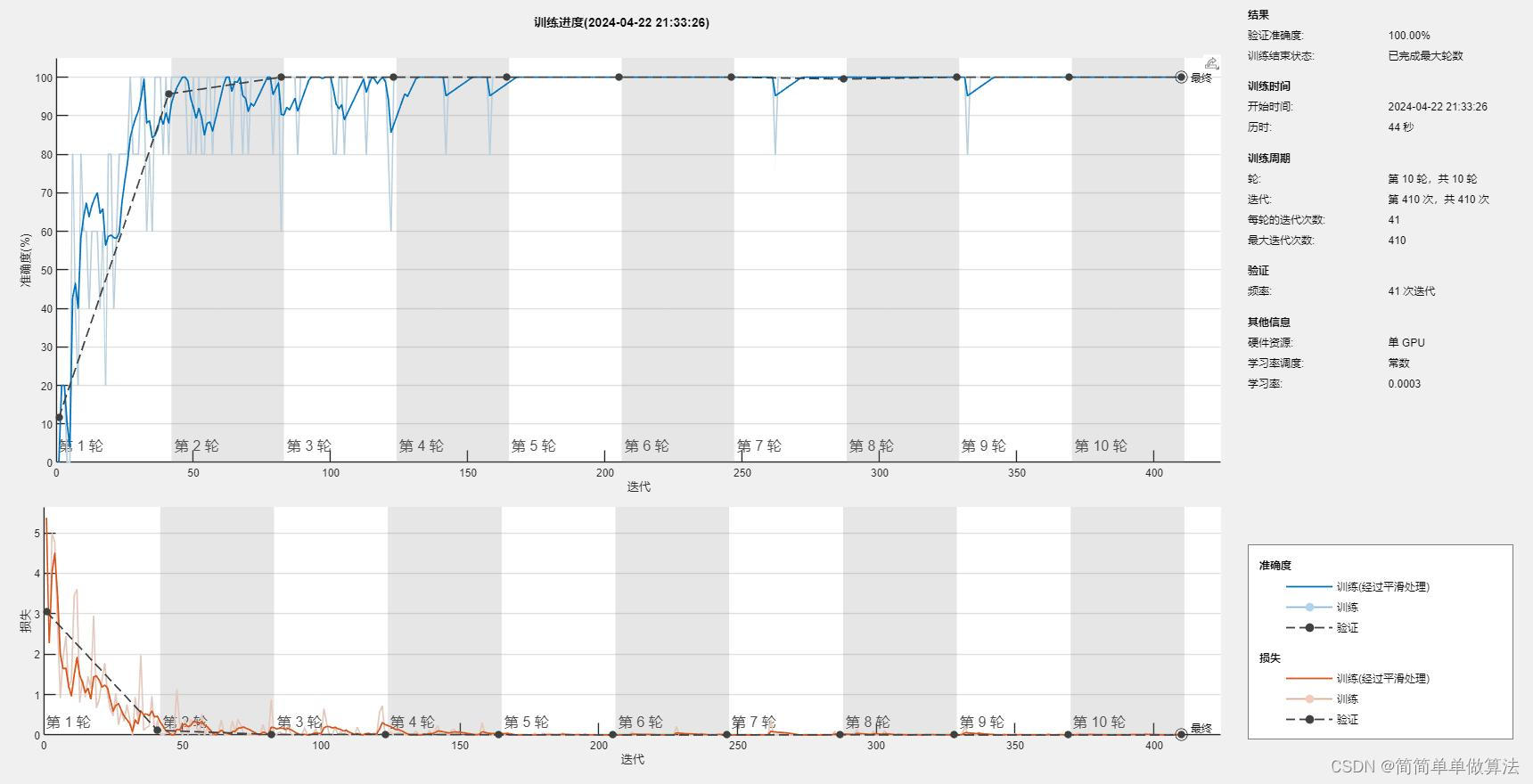
基于深度学习网络的十二生肖图像分类matlab仿真
【AI 初识】解释推荐系统的概念
【AI 初识】人工智能如何用于欺诈检测和网络安全?
【AI 初识】人工智能开发和部署的道德考虑是什么?
使用阿里云服务器ECS可以干嘛?
C#开源的两款功能强大的录屏神器