1、TensorBoard简介
Tensorboard
是Tensorflow官方推出了
可视化工具
,它可以通过TensorFlow程序运行过程中输出的
日志文件
可视化TensorFlow程序的运行状态。
TensorBoard 和 TensorFLow 程序跑在不同的进程中,TensorBoard 会自动读取最新的TensorFlow日志文件,并呈现当前 TensorFLow 程序运行的最新状态。
TensorBoard可视化神经网络模型训练过程中各种指标的变化趋势,直观的了解神经网络的训练情况。
TensorBoard的使用对于程序的理解、分析和优化都很有帮助。
2、TensorBoard数据形式
Tensorboard可以记录与展示以下数据形式:
(1)标量Scalars
(2)图片Images
(3)音频Audio
(4)计算图Graph
(5)数据分布Distribution
(6)直方图Histograms
(7)嵌入向量Embeddings
3、TensorBoard启动(Windows下cmd启动)并展示日志图表
确保计算图写入日志
writer=tf.summary.
FileWriter
(
'logs/'
,sess.graph)
(1)运行程序,在指定目录下(logs)生成 event 文件
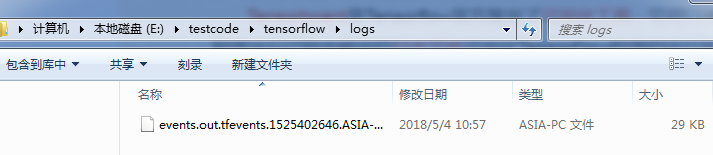
(2)在 logs 所在目录,按住
shift
键,点击右键选择
在此处打开 cmd
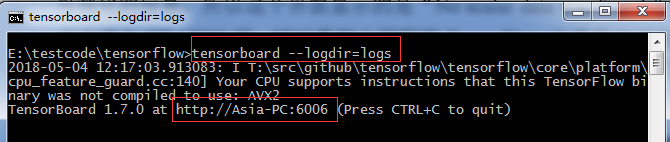
(3)在 cmd 中,输入以下命令启动
tensorboard --logdir=logs
(
注意:logs的目录并不需要加引号, logs 中有多个event 时,会生成scalar 的对比图,但 graph 只会展示最新的结果)
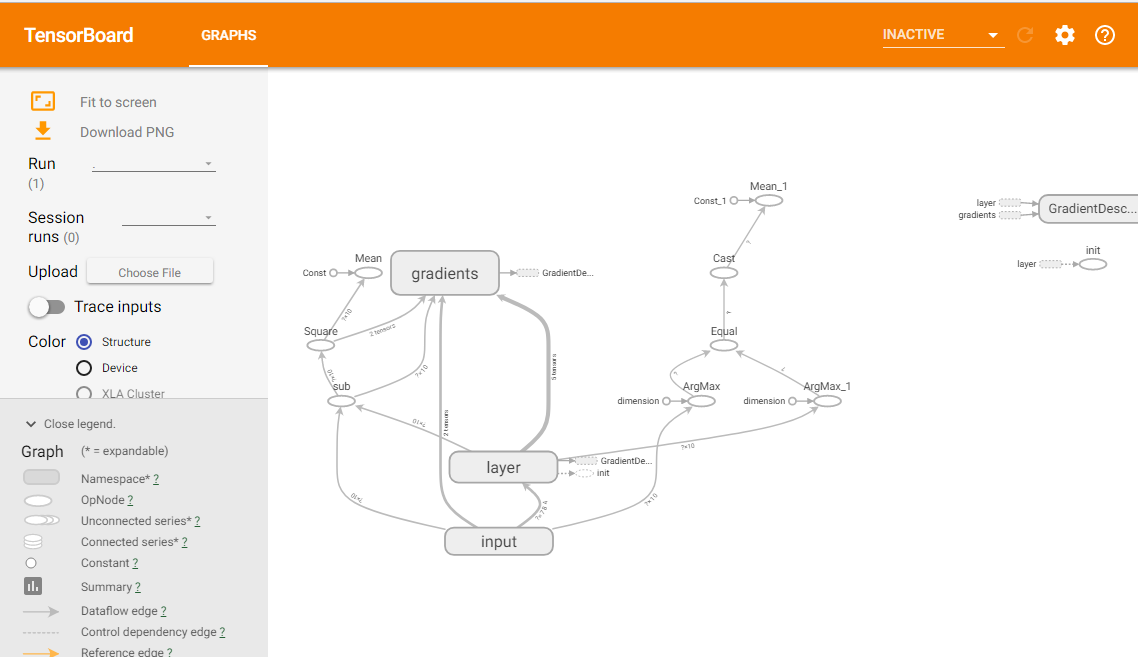
(4)把生成的
网址
复制到Google浏览器或火狐浏览器中打开即可
4、使用命名空间整理计算图
- 使用命名空间使可视化效果图更有层次性,使得神经网络的整体结构不会被过多的细节所淹没
- 同一个命名空间下的所有节点会被缩略成一个节点,只有顶层命名空间中的节点才会被显示在 TensorBoard 可视化效果图上
- 可通过tf.name_scope()或者tf.variable_scope()来实现,具体见最后的程序
例
:
with
tf.
name_scope
(
'input'
)
5、TensorBoard使用流程
(1)添加记录节点
:
tf.summary.scalar/image/histogram()
等。
使用tf.summary.scalar记录标量
使用tf.summary.histogram记录数据的直方图
使用tf.summary.distribution记录数据的分布图
使用tf.summary.image记录图像数据
(2)汇总记录节点
:
merged = tf.summary.merge_all()
(3)运行汇总节点
:
summary = sess.run(merged)
,得到汇总结果
(4)日志书写器实例化
:
summary_writer = tf.summary.FileWriter(logdir, graph=sess.graph)
,实例化的同时传入 graph 将当前计算图写入日志
(5)调用日志书写器实例对象summary_writer的
add_summary(summary, global_step=i)
方法将所有汇总日志写入文件
(6)调用日志书写器实例对象summary_writer的
close()
方法写入内存,否则它每隔120s写入一次
6、TensorFlow可视化分类
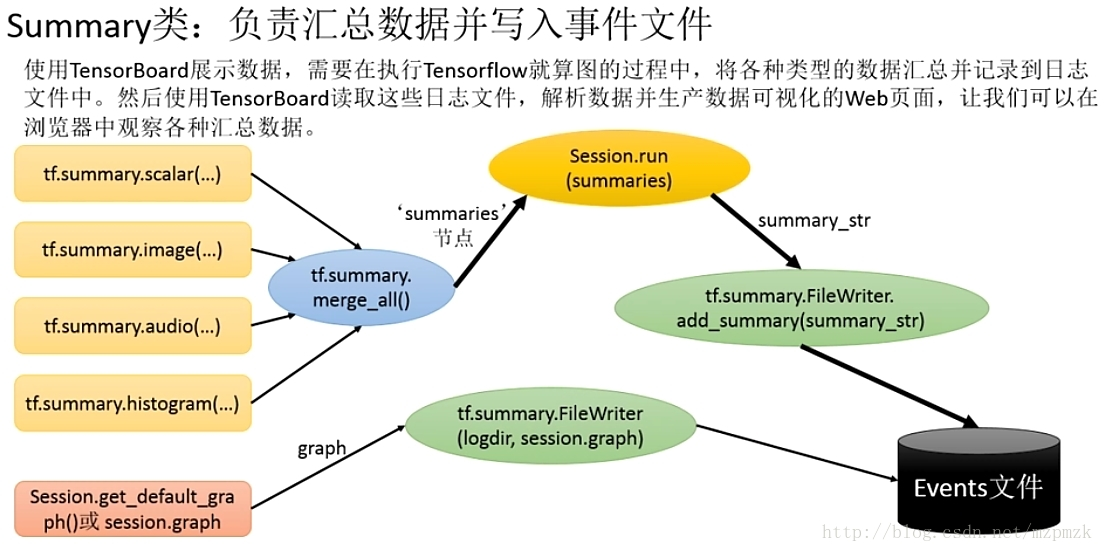
(1)计算图的可视化
# Create a summary writer, add the 'graph' to the event file.
writer = tf.summary.FileWriter(logdir, sess.graph)
writer.close()
# 关闭写入内存,否则它每隔120s写入一次
(2)监控指标的可视化
I、SCALAR
tf.summary.scalar(name, tensor, collections=None, family=None)
可视化训练过程中随着迭代次数
准确率
(val acc)、
损失值
(train/test loss)、
学习率
(learning rate)、每一层的
权重
和
偏置
的统计量(mean、std、max/min)等的变化曲线。
- 输入参数:
name
:此操作节点的名字,TensorBoard 中绘制的图形的纵轴也将使用此名字
tensor
: 需要监控的变量.
II、IMAGE
tf.summary.image(name, tensor, max_outputs=3, collections=None, family=None)
可视化当前使用的训练/测试图片
III、HISTOGRAM
tf.summary.histogram(name, values, collections=None, family=None)
可视化张量的取值分布
IV、MERGE_ALL
tf.summary.merge_all(key=tf.GraphKeys.SUMMARIES)
- Merges all summaries collected in the default graph
- 因为程序中定义的写日志操作比较多,一一调用非常麻烦,所以TensoorFlow 提供了此函数来整理所有的日志生成操作:merged = tf.summary.merge_all ()
- 此操作不会立即执行,所以,需要明确的运行这个操作(summary = sess.run(merged))来得到汇总结果
- 最后调用日志书写器实例对象的add_summary(summary, global_step=i)方法将所有汇总日志写入文件
7、TensorFlow实现MNIST手写数字识别,并可视化
模型
:
构建一个只有
输入层
和
输出层
的简单神经网络模型,使用
交叉熵
和
梯度下降算法
进行优化,并用
TensorBoard
可视化
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# 载入数据集
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
# 每个批次的大小
batch_size=100
#计算一共有多少个批次
n_batch=mnist.train.num_examples//batch_size
#参数概要(添加记录节点函数)
def variable_summaries(var):
with tf.name_scope('summaries'): #定义summary类的命名空间
mean=tf.reduce_mean(var) #计算参数的平均值
tf.summary.scalar('mean',mean) #记录数据的平均值
with tf.name_scope('stddev'): #定义命名空间
stddev=tf.sqrt(tf.reduce_mean(tf.square(var-mean))) #计算参数的标准差
tf.summary.scalar('stddev',stddev) #记录参数的标准差
tf.summary.scalar('max',tf.reduce_max(var)) #记录参数的最大值
tf.summary.scalar('min',tf.reduce_min(var)) #记录参数的最小值
tf.summary.histogram('histogram',var) #用直方图记录参数的分布
#定义命名空间
with tf.name_scope('input'):
# 定义两个placeholder(这里的None表示第一个维度可以是任意的长度)
x = tf.placeholder(tf.float32, [None, 784],name='x-input')
y = tf.placeholder(tf.float32, [None, 10],name='y-input')
#保存图像信息
with tf.name_scope('input_reshape'):
image_shaped_input=tf.reshape(x,[-1,28,28,1])
tf.summary.image('input',image_shaped_input,10)#记录10张图片数据
#定义命名空间(命名空间中仍可定义命名空间)
with tf.name_scope('layer'):
# 创建一个简单的神经网络(只有输入层和输出层)
with tf.name_scope('weights'):
Weights = tf.Variable(tf.zeros([784, 10]))
variable_summaries(Weights) #调用参数信息记录权重的信息
with tf.name_scope('biases'):
biases = tf.Variable(tf.zeros([10]))
variable_summaries(biases) #调用参数信息记录偏置的信息
with tf.name_scope('wx_plus_b'):
wx_plus_b = tf.matmul(x, Weights) + biases #执行wx+b的线性计算
with tf.name_scope('softmax'):
prediction = tf.nn.softmax(wx_plus_b)
with tf.name_scope('loss'):
# 交叉熵
loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=prediction))
tf.summary.scalar('loss',loss) #添加记录损失函数的标量
with tf.name_scope('train_step'):
# 使用梯度下降算法
train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss)
with tf.name_scope('accuracy'):
with tf.name_scope('correct_prediction'):
# 结果存放在一个布尔型列表中(argmax函数返回一维张量中最大的值所在的位置)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(prediction, 1))
with tf.name_scope('accuracy'):
# 求准确率(tf.cast将布尔值转换为float型)
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy',accuracy) #添加记录准确率的标量
#合并所有的summary(汇总记录节点)
merged=tf.summary.merge_all()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer()) #初始化变量
# 负责将事件日志(graph、scalar/image/histogram、event)写入到指定的磁盘文件中
writer=tf.summary.FileWriter('logs/',sess.graph)
for i in range(51):
for batch in range(n_batch):
batch_xs,batch_ys=mnist.train.next_batch(batch_size)
summary,_=sess.run([merged,train_step],feed_dict={x:batch_xs,y:batch_ys})
#将所有汇总日志写入文件
writer.add_summary(summary,i)
acc = sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels})
print("Iter" + str(i) + ",Testing Accuracy" + str(acc))
(1)SCALARS
展示的是
标量
的信息,我程序中用
tf.summary.scalars()
定义的信息都会在这个窗口
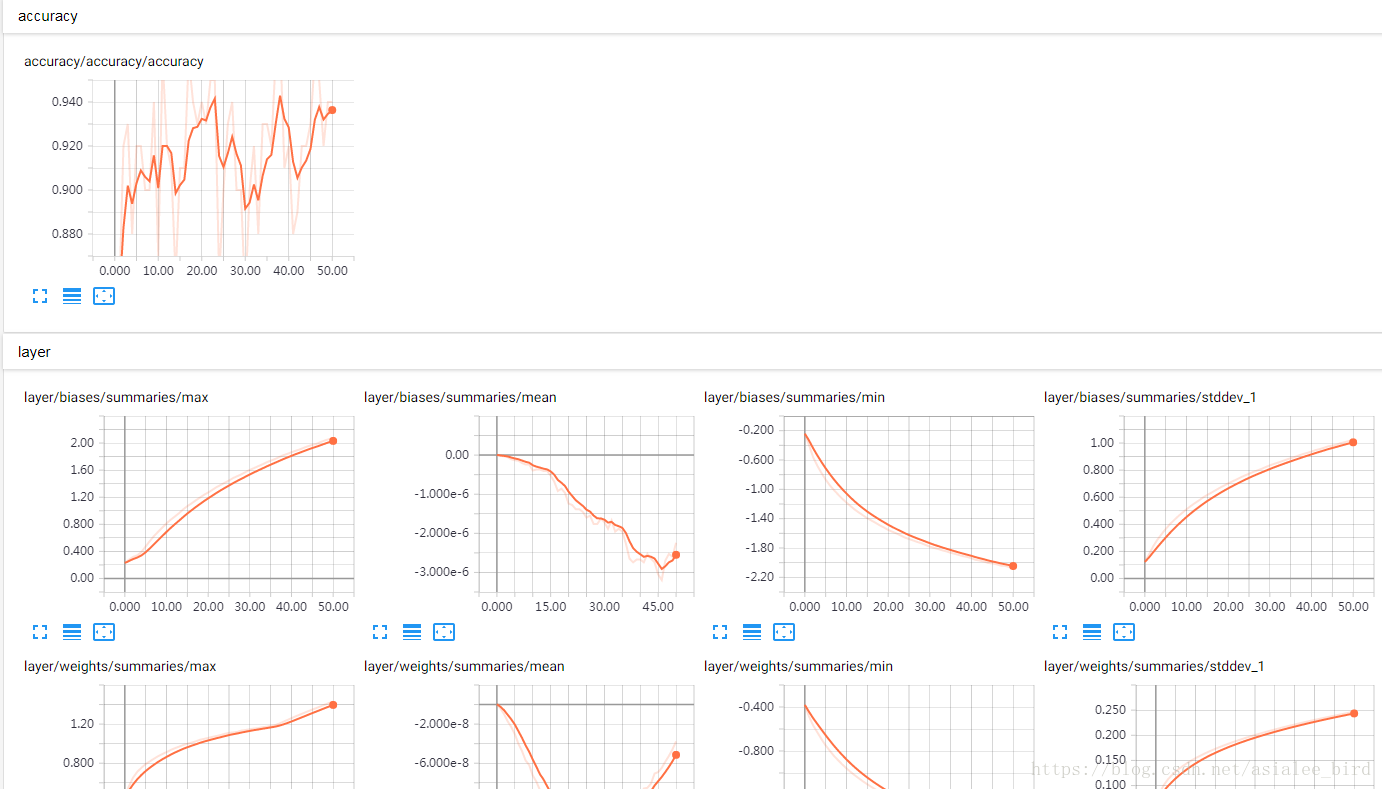
(2)IMAGES
展示的是
图片
的信息,我程序中用
tf.summary.image()
定义的信息都会在这个窗口

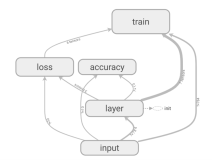
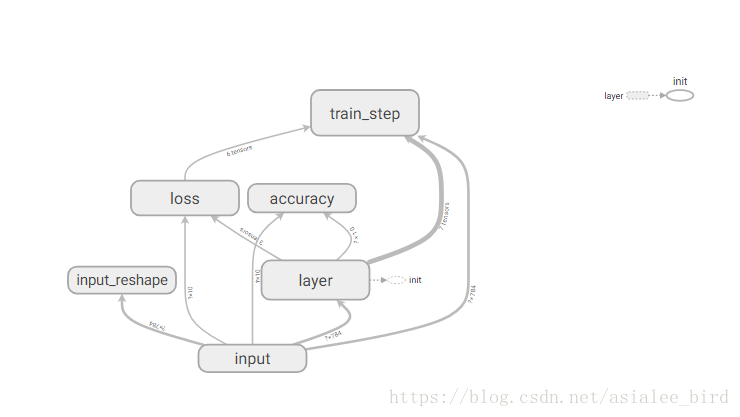
(3)GRAPHS
展示的是整个训练过程的计算图
graph
,从中我们可以清晰地看到整个程序的
逻辑与过程
。
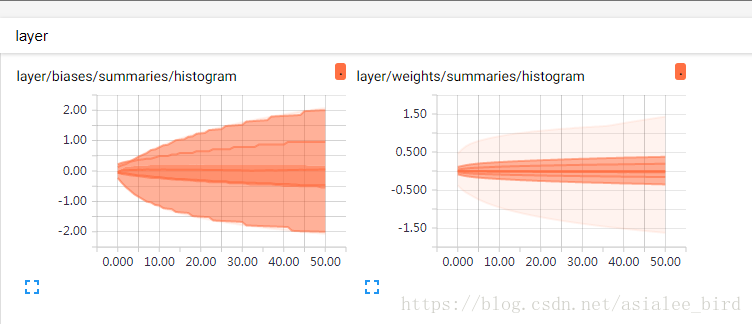
(4)DISTRIBUTIONS
展示的是整个训练过程中
权重和偏置的分布
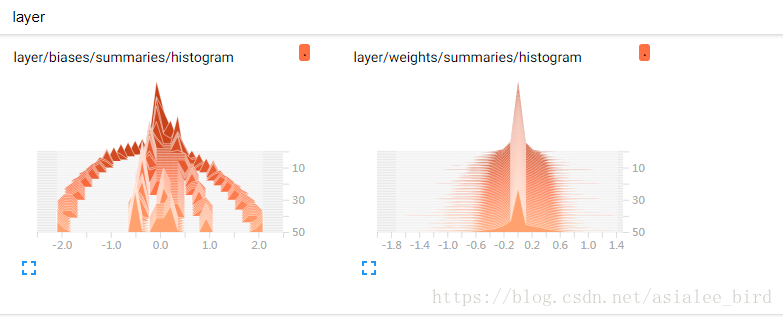
(5)HISTOGRAMS
展示的是整个训练过程中
权重和偏置的直方图
其它参看博客:https://blog.csdn.net/sinat_33761963/article/details/62433234