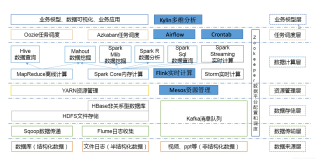
Hadoop体系里面,有个非常让其拥趸津津乐道的概念,混合部署。其基本含义就是将多个应用和组件部署在一个集群,共享一套资源,以获取资源的高效利用。物理机环境没有弹性的能力,这个混合部署概念弥补了部分弹性的需求。
先来看下产生的历史,Hadoop 1.0时代只有MapReduce/hdfs/zookeeper三大件,1.0时代只有MapReduce一种服务,没有共享的必要。Hadoop 2.0 YARN横空出世,主要概念来源于伯克利的mesos的思路,期望用同一个资源管理器管理所有资源共享给所有服务。YARN最主要作用就是将物理机环境的所有资源全部管理起来;各种该服务的资源由YARN统一分配和管理。随着资源管理器的发展的同时,2.0时代应用繁荣起来MapReduce/Hive/Spark/Hue/HBase,中间为了解决长期运行资源服务管理问题,还有一个专门的slider组件。Mesos出来也更早,相当长一段时间mesos和yarn还竞争了一把;最后mesos拗不过社区的力量改道搞应用部署,又去和K8S PK上了。
总的来说,在物理机环境中,这个思路还是非常先进的,但是今天演进到云环境是否还适用值得商榷一下,为什么这么说:
- 云时代,资源都是云平台统一管理。首先分配的粒度本身就很细,可以支持到0.5个cpu。需要多少,向云平台申请,用多少付费多少,非常弹性;可以如果还是老思路,提前固定申请一批,再分配给各个应用。完全没有享受云弹性的能力。
- 其次可以根据不同的应用需求,还可以灵活申请不同的规格,更好的匹配应用特点和充分利用资源。比如有些应用需要cpu多,有些应用需要IO强;YARN只能统一管理同规格服务器,很难照顾到每个应用的不同需求,非常容易申请过多,造成资源浪费。
- YARN概念非常先进,但是实际上管的好还是MapReduce,YARN一直没有很好的解决应用之间的资源争抢问题,尤其是不同特点的应用。例如HBase这种常驻型服务,机制上为了保证实时性,会尽量去占用所有的内存,HBase跑的好,其他服务就跑不好;其他服务跑好了,HBase基本也跑不好。类似问题spark,storm等都有。
所以云上最合理的是每个服务跟进自己的特点和需求,单独申请资源,自行管理。是时候丢掉在物理机时髦的混合部署的概念了。要充分去利用云平台本身的弹性能力。当能大部分公司,最简单的方法就是直接申请对应的云服务,将这些复杂的资源管理和运维的工作让云服务厂商负责,从而专注自己的业务。