案件背景
一个应用集群里,时不时会有几台机器出现cpu打满现象,开始没有引起重视,后来连续出现报警,开始着手对其中一台进行排查,现将破案记录如下。

cpu飙升这类案件,一般来说有几个对象嫌疑重大:
- 嫌犯A:内存泄漏,导致大量full GC
- 嫌犯B:宿主机cpu超卖
- 嫌犯C:代码存在死循环
锁定嫌犯
嫌犯A:内存泄漏?

从monitor上看到,这台机器cpu占用达到300%多,而GC一览并没有出现full GC,只是出现了一些常规的YGC。再观察堆内存使用情况,也属正常,先排出了oom的嫌疑。
ps:同样cpu问题,因为内存泄漏导致gc的一次案例:一次应用CPU飙高-GC频繁问题排查过程
嫌犯B:cpu超卖?
虚拟机和容器技术突飞猛进,一台宿主机上跑多个vm带来了很多便利,vm间大多时候都能和谐共处,但偶尔也会出现某个问题vm大量占用宿主机资源,导致其他vm受到影响,也是超卖问题
到底是不是超卖在搞鬼呢?登上机器top一把,一探究竟
top

这里看到Cpu(s)一栏,cpu占用主要来自us,而st(Steal Time)并不高,这说明cpu的消耗并非来自宿主机的超卖,而是应用自身的消耗。所以排出超卖的嫌疑。
锁定嫌犯C:死循环
排出了上面两位的嫌疑,看来只能继续深入应用内部,对犯案现场勘察,查明哪些线程在消耗cpu资源。
前面通过top命令拿到java应用的pid是2143,通过top -Hp pid 命令,查看进程内的线程情况:
top -Hp 2143

不看不知道,一看吓一跳,犯罪现场触目惊心!前几个线程都占用了大量cpu,并且占用cpu时间最长的一个线程(tid=32421),已经存活了5个多小时。
继续进行追查,这货到底在干啥?
printf "%x" 32421 -- 拿到十六进制

jstack pid | grep tid -- 查看线程情况

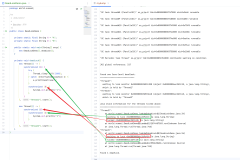
原来这个线程在HashMap.getEntry()这,线程状态显示是RUNNABLE,说明并没有出现死锁(Blocked),而是不停run了5个多小时,看来凶犯已经找到:死循环非他莫属了!
为了进一步确认,用类似方法一一盘查其他几个高cpu占用的线程,从招供来看都是类似的堆栈。同时,在psp上进行了一把dump,用Zprofiler分析了一把,除去一些正常的线程,还有不少共犯混迹其中。

作案手法
凶手已经找到,但它是如何作案的呢?也就是这个死循环是如何产生的?
HashMap的并发问题
上面的堆栈告诉我们,线程在HashMap.java:465行不停的run,从jdk7的源码(应用使用的版本)可以看到

原来问题出在e.next这个地方。
看过源码的同学都知道,jdk(6)7的HashMap是数组+链表的存储结构(jdk8优化加入了红黑树)。

为了在查询效率方面达到平衡,HashMap的size是动态变化的,size初始值是16(未指定情况下)。一般来说,Hash表这个容器当有数据要插入(put->addEntry)时,会检查容量有没有超过设定的thredhold,如果超过,需要增大Hash表的尺寸,这一过程称为resize。
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
// 动态扩容一倍
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
resize()源码如下:
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
可见,在多线程同时调用put方法时,多个线程也会同时进入transfer(),也就到了并发问题的核心地带
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
这段代码会重新构建数组和链表,这单线程下安全,但多个线程同时去操作链表,会出现意想不到的结果,比如A线程操作到一半被挂起,B线程对A正在操作的链表进行了挪动,然后A获得cpu资源继续操作,原先的链表元素可能已经被挪到其他位置。
这会造成部分数据丢失,有一定几率出现更糟的情况:环链表

那么回到之前的getEntry方法,出现环链表的情况下,e.next会出现无限循环,无法跳出的情况。
总结下,多线程同时put时,有一定几率导致环链表产生,导致get方法进入无限循环,进而导致了cpu飙高。
结案
到这里,真相已经浮出水面:二方包的一个工具类(静态类),使用了一个static的HashMap进行了并发操作,导致了并发问题。
多线程环境中,使用ConcurrentHashMap代替HashMap。
后续找提供二方包的同学确认,的确是使用了一个问题版本,此问题已经在新版本中已经修复,升级到新版即可。