世界杯来了!央视名嘴白岩松调侃 “俄罗斯世界杯,中国除了足球队没去,其他的都去了”,这届世界杯,中国球迷购买球票的数量在所有国家中排名第 9,可见球迷对世界杯的热情。那么,除了准备好小龙虾在电视机前观看世界杯比赛,你有没有想过让 C罗、梅西或者内马尔在你家桌子上踢一场比赛会是什么样子?
华盛顿大学、Facebook 和 Google 的研究人员开发了第一个端到端的深度学习系统,该系统可以将足球比赛的 YouTube 视频转换为运动的 3D 全息图。
用CNN重建一场足球比赛
“对一场足球比赛进行单目重建有很多挑战。我们必须估计相对于场地的摄像机姿态,检测并跟踪每个球员,重新构建他们的身体形状和姿势,并对联合重建进行渲染,” 研究人员在他们的研究论文中写道。

图1:以足球比赛的 YouTube 视频为输入,系统输出比赛的动态 3D 重建,可以使用增强现实设备在桌面上以交互式的方式观看。
下面的视频演示了这个系统:
这种方法的关键是卷积神经网络(CNN),研究人员通过训练 CNN 来估计每个球员与拍摄比赛的摄像机之间的距离。该网络分析了从足球视频游戏《FIFA》中提取的12000 张 2D 球员图像,以及从游戏引擎提取的相应 3D 数据,以了解两者之间的相关性。
这样,网络就能从没见过的 2D 图像中预估球员的深度图( depth maps)。当被展示没见过的视频时,系统能准确地预测每个球员的深度图,并将其与颜色素材结合,以3D 的方式重建每个球员。

图 2:重建方法的概览
以 YouTube 视频的帧作为输入,我们使用 field lines 来恢复摄像机参数。然后,提取边界框、姿势和轨迹(跨多个帧)来分割球员。通过在视频游戏数据上训练好的深度网络,我们在游戏环境中重建了每个球员的深度图,这样就可以在 3D 查看器或 AR 设备上呈现出来。
然后,球员们被放在一个虚拟的足球场上。其结果令人惊叹,并且可以通过 3D 查看器或 AR 设备从任何角度观看比赛。

图3:训练数据:从《FIFA》游戏中提取图像和对应的深度,这里展示了几个可视化为深度图和网格的例子。
该团队使用 NVIDIA GeForce GTX 1080 GPU 和 NVIDIA TITAN Xp GPU,以及cuDNN 加速的 PyTorch 深度学习框架,在从世界杯比赛视频中提取的数小时的 3D 球员数据上对卷积神经网络进行训练。
基于这些比赛视频数据,神经网络能够重构球场上的每个球员的深度图,这些图可以在3D 查看器或 AR 设备上呈现。

“事实证明,在玩 EA 的《FIFA》游戏并截取游戏引擎和 GPU 间的调用时,可以从视频游戏中提取深度图。具体来说,我们使用 RenderDoc 来截取游戏引擎和 GPU 之间的调用。” 研究团队表示:“FIFA 与大多数游戏类似,在游戏过程中使用延迟渲染。通过访问 GPU 调用,可以捕获每帧的深度和颜色缓冲区。一旦特定的帧被捕获了深度和颜色,就可以提取出球员。”
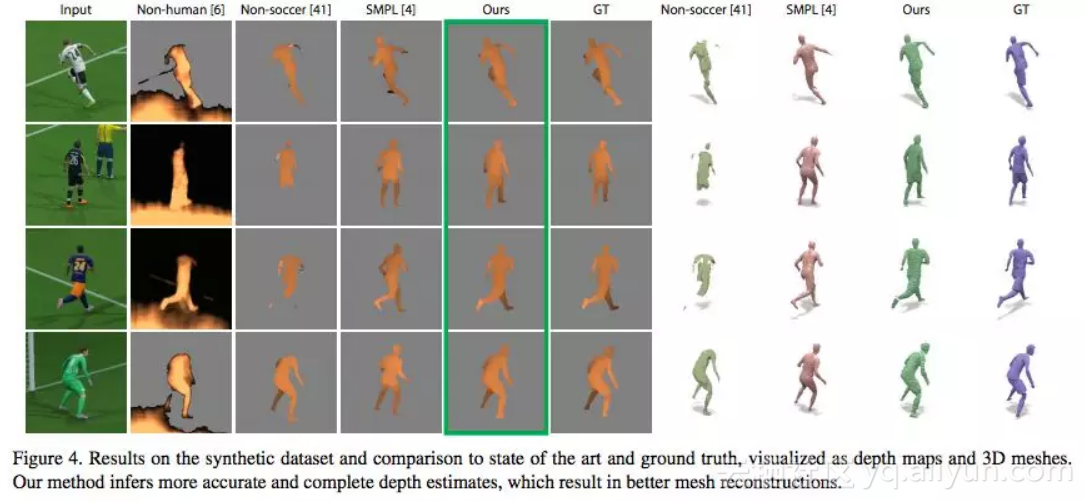
图4:合成数据集的结果以及与当前最优技术和 ground truth 的比较,可视化为depth maps 和 3D 网格。我们的方法更准确,实现了更好的网格重构。
为了验证这个系统,研究团队用 YouTube 上找到的 10 个高分辨率的职业足球比赛视频测试他们的方法。值得注意的是,该系统只在合成视频素材上进行训练。但是,在真实的场景中,系统也有非常好的结果。

研究人员用微软的 HoloLens AR 眼镜进行测试。HoloLens 可以将 3D 重建叠加到真实的桌面上。最终的产品虽然不完美,它无法重建球,不能实时地工作,并且只允许从视频录制的球场侧面观看。但是,这项技术可能比当前 3D 重建运动的最先进方法更具可扩展性,因为当前的方法需要在每一个角度布置相机。研究人员称,这种方法也适用于预定义的其他事件,例如音乐会或剧场。

研究人员承认他们的系统并不完美。他们的下一个项目将专注于训练系统以更好地检测球,并开发可从任何角度观察的系统。
这项研究将于 6 月 18 日至 22 日在犹他州盐湖城举行的年度计算机视觉和模式识别(CVPR)会议上首次亮相。
原文发布时间为:2018-06-26



