eiπ + 1 = 0 ,这是数学史上最美妙的公式之一 —— 欧拉公式。
它揭示了表面看似无关的数学领域之间的深层联系,是数学界的伟大奇观之一。而这也指出了数学之美的另一个组成部分:数学模式必须在某种角度上是有趣的。
自古以来,发现这些有趣的模式一直是人类独有的能力。而现在,机器也具备了这样的能力!
近几年来,机器已经成为强有力的模式识别工具。人脸识别、目标检测、甚至水军评论过滤,不一而足。
这不由引发了我们的思考:机器学习算法是否也可以识别出有趣优雅的数学模式呢?
来自IBM研究中心的 Chai Wah Wu 的最新研究结果告诉我们:这完全是可能的!
Wu实现了一种机器学习算法,该算法已经能够学习并识别出数学结构中的某些优美之处,并被用于从完全随机的序列中,过滤出那些有趣的数列。

该研究的主要目的在于探究机器学习是否可以用于定义科学知识的本质属性,即是否能够辨别其是否具有优雅,简洁或有趣性质。并通过对数列进行研究来探索这个问题。
之所以采用数列进行研究,一方面是因为数列结构本身包含了很多基本的数学思维,另一方面是因为现有已被编辑和整理超过50年的庞大数列数据库可用于分析。
该算法使用了一种名为整数序列在线大全的特殊数据库,这个数据库最初由数学家尼尔斯隆(Neil Sloane)于20世纪60年代创建,并于1996年挂到网上。
整数序列在线大全数据库
http://oeis.org/
The Online Encyclopedia of Integer Sequences (OEIS) 整数序列在线大全由尼尔斯隆(Neil Sloane)于1964年创建,目前已经包含超过300,000个数列,并由数千名OEIS社区的志愿者不断地编辑和添加这些序列的元数据和引用信息。数据库中每个数列都被社区成员指定了关联的关键字。例如‘nice’,‘core’,‘base’,‘hard’等关键字。
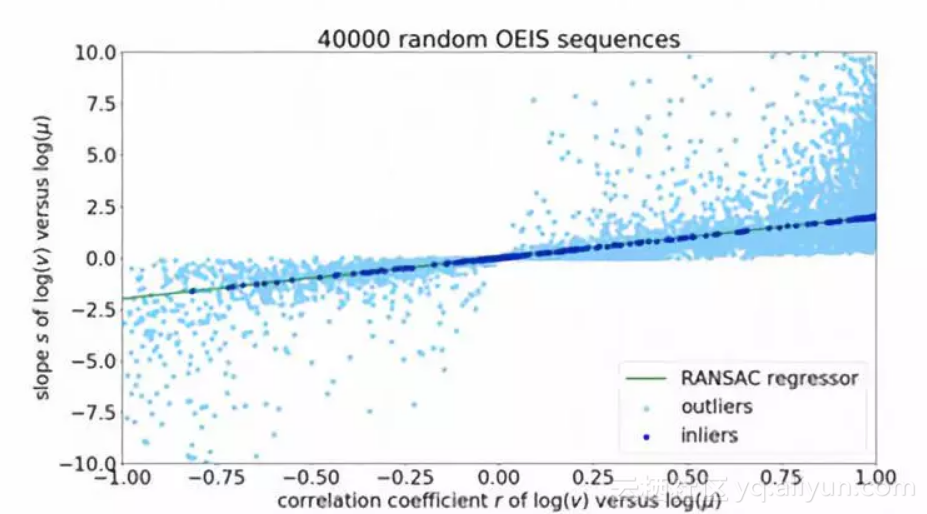
40000个OEIS中的随机序列
图示为斜率 s与相关系数r的关系,采用RANSAC随机抽样一致算法作为回归求导函数,并且其slope值约为2。样本中的正常数据(大约占序列集的一半)符合Slope=2.001, intercept=0.003 ,相关系数r=0.999的回归曲线.
整数数列是指由根据某一规则排序后的一列数字。其中比较著名的数列包括素数——只能被自身和1整除的数;斐波那契数列,数列中的每项是前两项的和;甚至还包括一些较为普通的数列,例如奇数序列或者以7开头的素数序列。
实际上OEIS网站背后的数学家们撒开大网来寻找“有趣的”数列,由此网站中也收录了很多具有纯粹文化意义的数列。例如包含666序列的素数,其中666被称之为恶魔数字。
这个数据库甚至还录入了包含数字667的素数序列。667这个数字被认为很重要,因为在传真机普遍的时代,传真机号码通常就是人们的电话号码加1。也就是说,如果他们的电话号码是 123-4567,那他们的传真号码就是123-4568。按这种方式计算,667就是恶魔数字(666)的传真号码,因此这个数字具有一定的文化意义。
包含数字667的素数序列
http://oeis.org/A138563
如今,这个整数序列数据库包含约30万个序列,并且每天都有业余爱好者和专业人士提交新的序列,其中很多序列暗含着新的有趣的数学问题。
Wu的任务就是找到一种方式来从随机生成的序列中区分出这些“有趣的”序列。他的想法是通过找到作用于定义“有趣”序列的经验规则,来将其从其他序列中区分开来。

为了实现对这些数列分类计算,我们希望能够找出一些固定的数列特征,并将这些特征应用到有限个数序列上进行分类计算。本文研究中采用了两个经验规则来进行计算。
Wu说:“经验规则本身并不是数学定理,而是经由经验观察结果得出的规律。这些规律可能可以应用于很多自然或人造数据集”。例如电气工程的摩尔定律和经济学中的80/20帕累托原则。尽管这些“定律”的原因不得而知,他们却真实存在。
本福德定律(Benford’s Law)也是一个广泛适用很多数据集的经验规则。本福德定律是1881年由加拿大数学家和天文学家西蒙·纽康伯(Simon Newcomb)发现的。纽康伯注意到对数表书籍中的前几页较后面的页翻阅破损更严重,这表明以数字1开头的对数更加常见。
这使他得出一个原理,即在任意一组数字中,更多的情况是以数字1为首出现,而不是以其他数字为首。20世纪30年代,富兰克本福德(Frank Benford)也发现这一现象并推广了这个原理。
本福德定律(Benford’s Law)指出:在一组数字中,较小数字排在首位的概率更高。更准确的定义是,以b为底,数字d出现在首位的概率为logb( (d+1)/ d )。在本文研究中采用以10为底的公式版本。
本福德定律适用性广泛,例如电费数字,街道地址,股票价格数字等。这个定律的预测力很强,以至于它被用于识别财务账户中的欺诈行为。但它不适用于随机序列,这点究竟为什么至今还没有弄清。
的确,本福德定律支配一些整数序列这一现象是十分神奇的。那么它能多广泛地应用于这些OEIS数据库中的数列中呢?
为了弄清这一点,Wu计算了利用本福德定律预测从OEIS数据库中随机选择的40,000个序列的首位数字分布的结果。
事实证明本福德定律比预期的适用性更广。Wu说:“结果表明,大部分但不是全部的序列,从某种程度上满足本福德定律。”
他还发现,另一个经验规则泰勒定理(Taylor’s Law)也普遍存在。
泰勒定理(Taylor’s Law)由莱昂纳尔·泰勒(Lionel Taylor ) 于1961年提出。他指出在社会生态学中,均值µ和方差v似乎满足幂律公式:v = TaµTb,其中Ta和Tb为正常数。泰勒定理被观察出现在很多自然观察的数据集和数列中,如素数序列,和二项式系数序列。
接下来就是更进一步的问题了:本福德定律和泰勒定理能否将随机序列从OEIS的序列中区分出来?
为了弄清楚这个问题,Wu生成了40,000个随机整数序列,并将这些随机整数序列添加到从OEIS中选出的40,000个序列中去。然后他训练机器学习算法,利用本福德定律和泰勒定理来识别OEIS序列,并将OEIS序列从随机序列中区分出来。
在Wu从OEIS中随机选择的40,000条数列集中,每一个序列中至少包含990个数字。之所以采用990这个数字是因为,OEIS数据库对大部分数列的个数限制为1000个,有些数列中的数字个数稍少于1000个,如“包含至少n个连续相同数字的最小序列”。
为了验证上述问题,Wu从2000个随机整数中生成了大约40,000个序列,并计算得到这些随机序列的14个特征。然后将这些随机序列添加到上述OEIS序列中,组成80,000个随机序列,并随机抽取其中的70,000个作为训练集,10,000个作为测试集。他采用随机森林分类器,使用665作为树的个数,以及其他通过超参优化得到的参数。
通过主成分分析处理后,得到从随机序列中区分OEIS序列计算模型的性能指标如下:准确度(accuracy):0.999,精确度(precision):0.9984,召回率(recall):0.9996,F1值:0.9990。
这样的结果令人非常欣喜。这表明了,通过自动化程序识别“有趣”数列是完全可行的。
通过机器学习来识别序列有一个显而易见用途。OEIS背后运营的数学家们目前每年都需要处理大约10,000份序列的提交。所以这种自动化识别有趣序列的方法可能会很有帮助。
但是,这种方法有一些很明显的局限性。数学家们已经定义了很多有趣且重要的无穷大序列,并且这些序列难以计算。因此,OEIS数据库中只涵盖了数列中的一小部分数字。这些只有小部分的序列显然不适合这种基于机器的分析。

更普遍的一个问题是,是否通过这种方式能够定义数学之美?正如Wu所问的:“机器学习能否识别科学知识的定性属性;换句话说,机器是否能够辨别出一项科学结果是否是优雅的,简洁的,或是有趣的?”
这一愿景可能并不完全是没有希望。如果像上问题到的类似福德定律和泰勒定理这样的经验规则可以作为“有趣性”的指标,那么或许这种算法至少在某种程度上,可以被认为是数学之美的仲裁者。
倘若机器学习真能到达这一境界,想必欧拉公式的命名者、也是历史上最伟大的数学家之一——欧拉也会在棺材板里惊讶地坐起来吧~
原文发布时间为:2018-06-25
本文作者:文摘菌
