MySQL分区表-电商数据库设计及优化学习笔记
一、背景
这里是我的电商数据库设计及优化学习笔记中关于MySQL分区表部分的内容。
二、MySQL分区表
1、使用分区表需要注意的:
*确认MySQL服务器是否支持分区表
使用mysql>show plugins来查看
分区表的特点:
*在逻辑上为一个表,在物理上存储在多个文件中
2、常用的分区表的类型:
2.1 哈希类型的分区:
主要特点:
根据MOD(分区键,分区数)的值把数据行存储到表的不同分区中,这样的分区称为哈希分区。
hash分区的键值必须是一个INT类型的数据,或者通过函数可以转为INT类型
如何建立哈希分区:
在建表语句最末尾加上 PARTITION BY HASH(分区键) PARITION 分区数
如
PARTITION BY HASH(customer_id) PARITION 4;
分区表和非分区表的差异主要还是在物理文件上:
分区表会包含一个以frm结尾的源数据文件,还有按照分区的id建立的数据文件
分区表的使用跟普通表是一样的
2.2按范围分区
特点:
根据分区键值的范围把数据行存储到表的不同分区中
多个分区的范围要连续,但是不能重叠
默认情况下使用VALUES LESS THAN属性,即每个分区不包括指定的那个值。
建立RANGE分区:
在建表语句最末尾加上 PARTITION BY RANGE(customer_id) (
PARTITION p0 VALUES LESS THAN(10000),
PARTITION p1 VALUES LESS THAN(20000),
…
PARTITION pn VALUES LESS THAN MAXVALUES,
);
这里表示,分区键,也就是customer_id范围在0-9999的用户存储在p0分区,10000-19999的用户在p1分区,在范围分区中最好包括一个VALUES LESS THAN MAXVALUES的分区。
范围分区适用场景:
分区键为日期或是时间类型
所有查询中都包括分区键
定期按照范围清理历史数据
2.3 LIST分区
特点:
按分区键取值的列表进行分区
同范围分区一样,个分区列表不能重复
每一行数据必须能找到对应的分区列表,否则数据插入会失败
建立LIST分区
在语法上和哈希、范围分区的区别:
PARTITION BY LIST(login_type)(
PARTITION p0 VALUES IN(1,3,5,7,9),
PARTITION p0 VALUES IN(2,4,6,8)
);
3.为登录日志表分区
3.1业务场景分析:
记录用户每次登录的日志,用户每次登录都会记录customer_login_log日志
用户登录日志保存一年,一年后可以删除
3.2表的分区类型及分区键
根据业务场景分析,这里适合使用范围分区,选择分区键要尽量避免产生跨分区查询,在登录日志表中,只有login_time是日期类型的,而且之后需要根据日期删除,所以选择login_time作为分区键
3.3分区用户登录日志表
CREATE TABLE customer_login_log(
customer_id INT UNSIGNED NOT NULL,
login_time DATETIME NOT NULL,
login_ip INT UNSIGNED NOT NULL,
login_type TINYINT NOT NULL
)ENGINE =INNODB
PARTITION BY RANGE(YEAR(login_time))(
PARTITION p0 VALUES LESS THAN(2017),
PARTITION p1 VALUES LESS THAN(2018),
PARTITION p2 VALUES LESS THAN(2019)
);
往表中添加几条数据
INSERT INTO customer_login_log(customer_id,login_time,login_ip,login_type)VALUES(1001,’2017-01-25’,0,1),(1001,’2017-07-25’,0,1),(1001,’2018-01-25’,0,1),(1001,’2018-03-25’,0,1),(1001,’2016-01-25’,0,1);
通过MYSQL系统日志查询查看分区情况,语句如下:
SELECT table_name,partition_name,partition_description,table_rows
FROM information_schema.PARTITIONS
WHERE table_name=’customer_login_log’
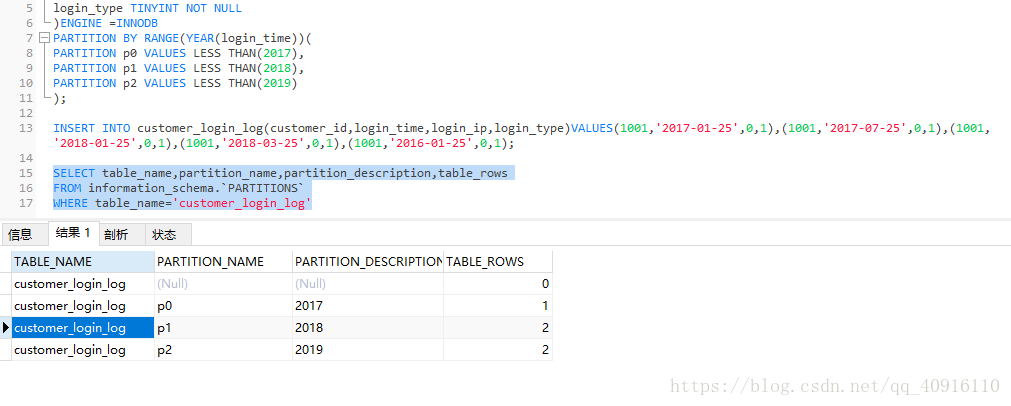
在这个表中没有建立MAXVIEW分区是为了维护方便,为了避免插入数据到RANGE分区失败,要做修改并添加分区的计划任务。
增加分区的语句
ALTER TABLE customer_login_log ADD PARTITION (PARTITION p4 VALUES LESS THAN(2020));
删除分区
ALTER TABLE customer_login_log DROP PARTITION P0;
归档过期数据
除了删除数据,还有可能需要对过期数据进行归档
分区数据归档迁移条件:
1、MYSQL>=5.7
2、结构相同
3、归档到的数据表一定要是非分区表
4、非临时表,不能有外键约束
5、归档引擎要是:archive
步骤1、先建立一个非分区表
CREATE TABLE customer_login_log(
customer_id INT UNSIGNED NOT NULL,
login_time DATETIME NOT NULL,
login_ip INT UNSIGNED NOT NULL,
login_type TINYINT NOT NULL
)ENGINE =INNODB
步骤2、数据交换
ALTER TABLE customer_login_log exchange PARTITION P1 WITH TABLE arch_customer_login_log;
将分区p1,也就是2017年以前的数据交换到归档表中,
此时日志表中p1分区中已经没有数据,但是分区还存在,p1分区中的数据已经存在刚刚建的归档表中,但是之后再往日志表中插入2017年以前的数据还是会存到p1分区表中,所以此时要对p1分区进行删除。
语句: ALTER TABLE customer_login_log DROP PARTITION P1;
步骤3、如果有需要,可以把日志表存储引擎改为归档引擎:
ALTER TABLE arch_customer_login_log ENGINE=archive
归档引擎比innodb占用的内存更小,但是归档引擎的表只能进行查询操作,而不能进行写操作。
使用分区表的注意事项
结合业务场景选择分区键,避免跨分区查询
对分区表进行查询最好在where从句中包含分区键
具有主键或者唯一索引的表,主键或唯一索引必须是分区键的一部分
(所以在用户登录表中把自增id主键去掉了,不然会影响分区)
三、小结
学习了常用的分区类型:哈希分区,范围分区,LIST分区。还有增加分区、删除分区的方法。
表分区的优点:
1、改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。
2、增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用;
3、维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可;
4、均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能。
但是也有缺点:
分区表相关:已经存在的表没有方法可以直接转化为分区表。不过 Oracle 提供了在线重定义表的功能。
使用分区要注意
结合业务场景选择分区键,避免跨分区查询
对分区表进行查询最好在where从句中包含分区键
具有主键或者唯一索引的表,主键或唯一索引必须是分区键的一部分
(所以在用户登录表中把自增id主键去掉了,不然会影响分区)
原文地址https://blog.csdn.net/qq_40916110/article/details/80782191