解决 flume KafkaSink 启动后cpu占用100%的问题
Flume 版本 :1.6.0-cdh5.5.0
问题描述:
配置kafkasink,将实时数据发送到kafka。
Flume启动完成后,没有日志处理时,cpu使用率飙升到100%
当有日志数据处理时,并发稳定时,cpu不定时会有一瞬间飙升。
当日志数据量比较大时,cpu不会飙升。
发现:
使用 jstack -F <pid> > /home/name/flume-dump.log命令,查看flume的堆栈信息
发现很多BLOCKED信息如下:
Thread 16599: (state = BLOCKED)
- java.util.concurrent.locks.ReentrantReadWriteLock$FairSync.readerShouldBlock() @bci=1, line=695 (Compiled frame; information may be imprecise)
- java.util.concurrent.locks.ReentrantReadWriteLock$Sync.tryAcquireShared(int) @bci=33, line=470 (Compiled frame)
- java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireShared(int) @bci=2, line=1282 (Compiled frame)
- java.util.concurrent.locks.ReentrantReadWriteLock$ReadLock.lock() @bci=5, line=727 (Compiled frame)
- org.apache.flume.channel.file.Log.lockShared() @bci=4, line=785 (Compiled frame)
- org.apache.flume.channel.file.FileChannel$FileBackedTransaction.doTake() @bci=72, line=501 (Compiled frame)
- org.apache.flume.channel.BasicTransactionSemantics.take() @bci=51, line=113 (Compiled frame)
- org.apache.flume.channel.BasicChannelSemantics.take() @bci=26, line=95 (Compiled frame)
- org.apache.flume.sink.kafka.KafkaSink.process() @bci=57, line=97 (Compiled frame)
- org.apache.flume.sink.DefaultSinkProcessor.process() @bci=4, line=68 (Compiled frame)
- org.apache.flume.SinkRunner$PollingRunner.run() @bci=24, line=147 (Compiled frame)
- java.lang.Thread.run() @bci=11, line=745 (Interpreted frame)
分析:
颜色选中部分可以看到线程的执行过程,走了哪些类,哪些方法。
那就去看一下源码吧。
下载flume-ng-1.6.0-cdh5.5.0-src.tar.gz flume的源码包
使用intellj idea打开。
Ctrl+n 搜索第一个类org.apache.flume.SinkRunner
点击 scroll from source

定位到这个类,发现是在flume-ng-core包中
接着看这个类中的内部类PollingRunner的run方法

这个类执行policy.process,policy的类型时SinkProcessor
,是所有sink的顶层接口,用来执行所有sink的process方法。
While循环中根据process方法返回的sink Status,判断当前channel中的event是否处理完毕。
如果处理完了,当前sink sleep。
如果这个sink没有返回BACKOFF,会一直while死循环的执行policy.process()方法。并判断其返回的状态。
Cpu占用率100%极有可能时死循环造成的,带着这个猜想,我看了一下process的实现类。
DefaultSinkProcessor类的process方法如下

那sink时哪个呢?上面的栈信息提示是KafkaSink。来看这个sink的process方法:
@Override
public Status process() throws EventDeliveryException {
// 一开始设置了status为ready
Status result = Status.READY;
Channel channel = getChannel();
Transaction transaction = null;
Event event = null;
String eventTopic = null;
String eventKey = null;
try {
long processedEvents = 0;
transaction = channel.getTransaction();
transaction.begin();
messageList.clear();
for (; processedEvents < batchSize; processedEvents += 1) {
// 从channel获取event
event = channel.take();
if (event == null) {
// no events available in channel
// 我们flume一启动直接飙升,当前肯定是没有日志的。所以执行到这里 // for退出
break;
}
byte[] eventBody = event.getBody();
Map<String, String> headers = event.getHeaders();
if ((eventTopic = headers.get(TOPIC_HDR)) == null) {
eventTopic = topic;
}
eventKey = headers.get(KEY_HDR);
if (logger.isDebugEnabled()) {
logger.debug("{Event} " + eventTopic + " : " + eventKey + " : "
+ new String(eventBody, "UTF-8"));
logger.debug("event #{}", processedEvents);
}
// create a message and add to buffer
KeyedMessage<String, byte[]> data = new KeyedMessage<String, byte[]>
(eventTopic, eventKey, eventBody);
messageList.add(data);
}
// break后到这里。Event是null,而且我们并没有日志写进来,处理的event
// 数一定是0,下面的if也不会进
// publish batch and commit.
if (processedEvents > 0) {
long startTime = System.nanoTime();
producer.send(messageList);
long endTime = System.nanoTime();
counter.addToKafkaEventSendTimer((endTime-startTime)/(1000*1000));
counter.addToEventDrainSuccessCount(Long.valueOf(messageList.size()));
}
// 出来if直接事务提交了。肯定也是null,到目前位置没有看到status的改变
transaction.commit();
} catch (Exception ex) {
String errorMsg = "Failed to publish events";
logger.error("Failed to publish events", ex);
result = Status.BACKOFF;
if (transaction != null) {
try {
transaction.rollback();
counter.incrementRollbackCount();
} catch (Exception e) {
logger.error("Transaction rollback failed", e);
throw Throwables.propagate(e);
}
}
throw new EventDeliveryException(errorMsg, ex);
} finally {
if (transaction != null) {
transaction.close();
}
}
// 这里竟然直接返回了。。Channel是空的时候返回了。除了判断什么都没做!!!
return result;
}
可以看到,KafkaSink的process的实现,除了第一行代码设置了status为reday。之后就没有对状态进行改变,而PollingRunner的run方法是根据这个status判断当前sink是否需要sleep。Channel中没有event需要处理,当然要sleep啊,不然就是死循环了。只有在有数据的时候,处理数据才不会对cpu造成太大的压力。
这就解释了开头说的数据量打的时候cpu占用并不会太高的原因。
为了再确认一下,这个思路是不是正确的,再看一下flume实现的其他sink。再event为null的时候是怎么处理的。
HDFSEventSink的process方法如下
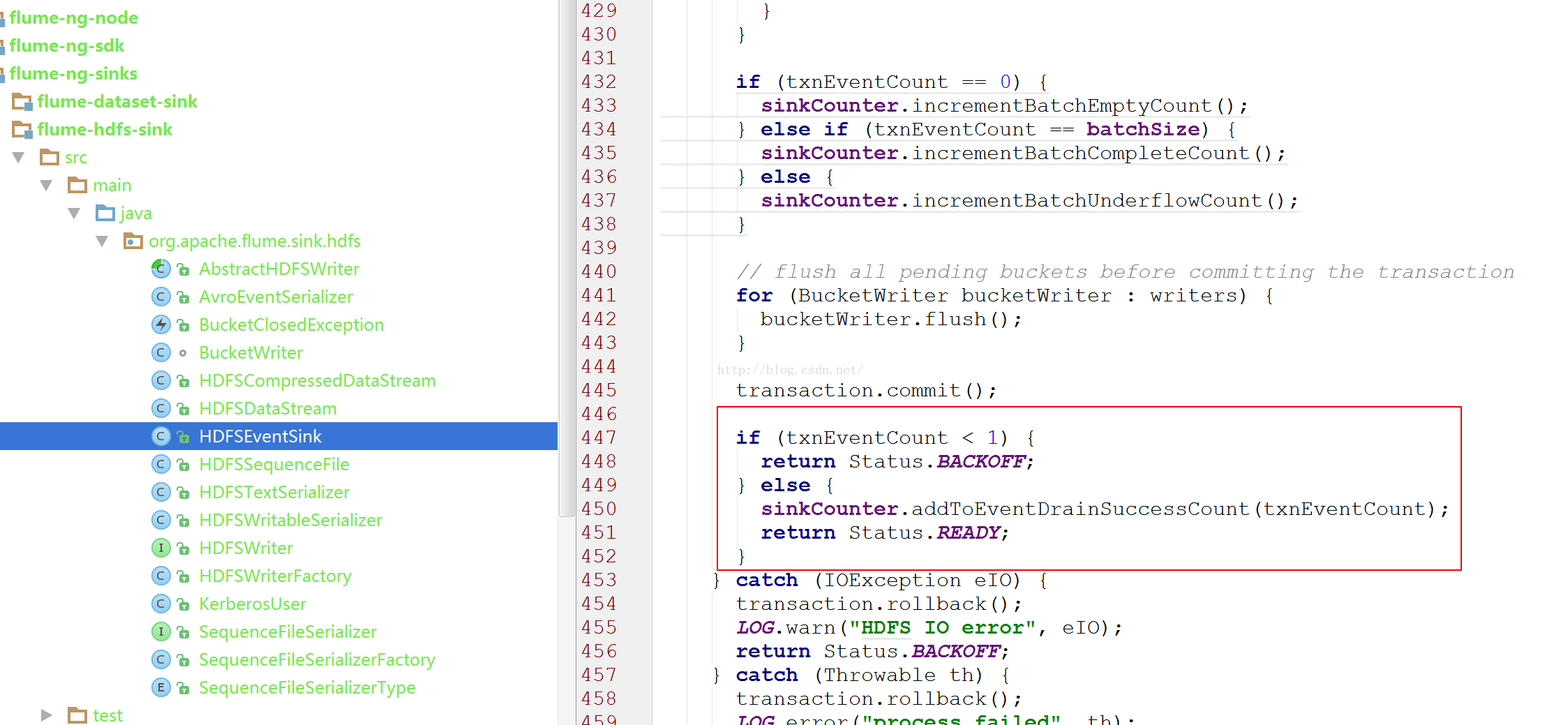
在commit后,判断了txnEventCount(for循环的计数器,循环一次说明处理了一个event)数。如果小于1(表示没有event),返回了BACKOFF。
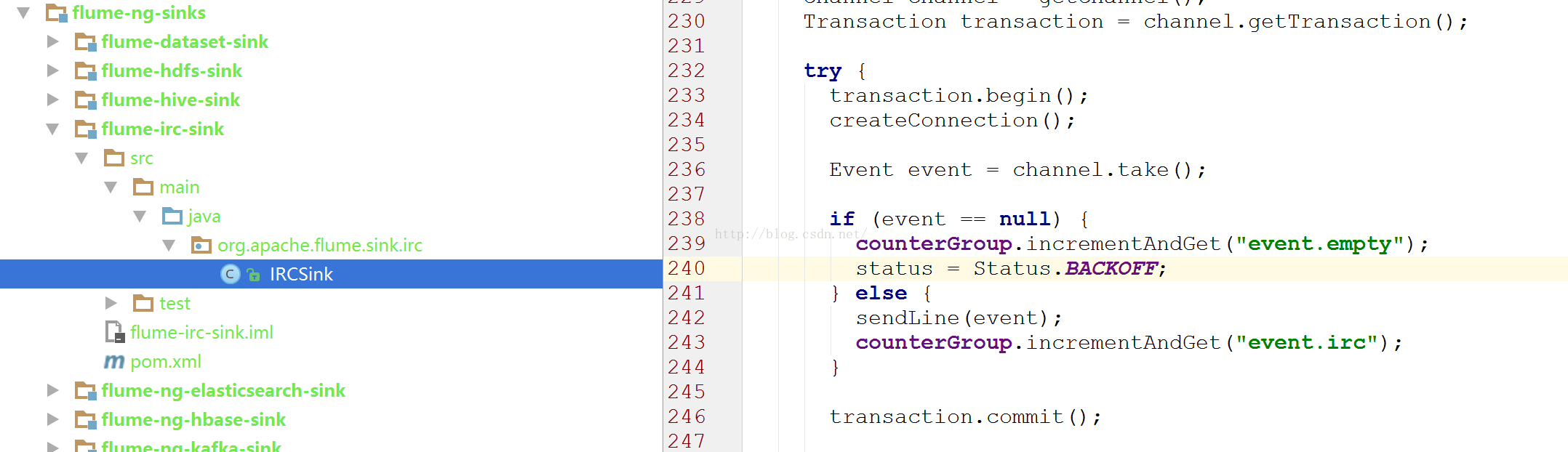
IrcSink的处理方式:
可以看到这几个sink再event为null的时候,都将status设置为了BACKOFF
解决方法:
这个问题再flume的1.7版本中已经解决了。
1.7中的KafkaSink是这样做:
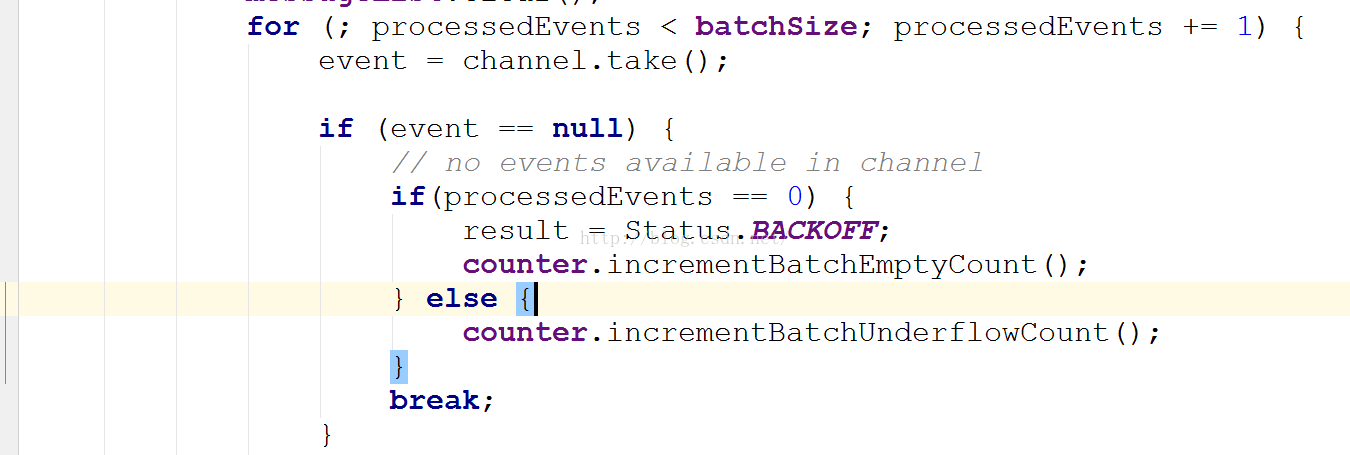
if (event == null) {
// no events available in channel
if(processedEvents == 0) {
result = Status.BACKOFF;
counter.incrementBatchEmptyCount();
} else {
counter.incrementBatchUnderflowCount();
}
break;
}