热门
让你的文档从静态展示到一键部署可操作验证
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
设置ip代理无法联网怎么办
如何选择合适的IP代理
CCProxy代理服务器地址的设置步骤
Python与MySQL数据库交互:面试实战
Nginx正向代理域名的配置
反向代理服务器如何提升信息安全
使用PHP实现动态代理IP的功能
如何解决无法联网的IP代理问题
动态代理IP的并发处理技巧
Java动态转发代理IP的实现方法
全局代理与自动代理主要差异与选择
详解正向代理和反向代理的不同用途
git怎么设置http代理服务器
群控代理IP搭建教程
如何将动态IP代理转换为静态IP代理的方法与步骤
详解配置代理和IP设置的含义
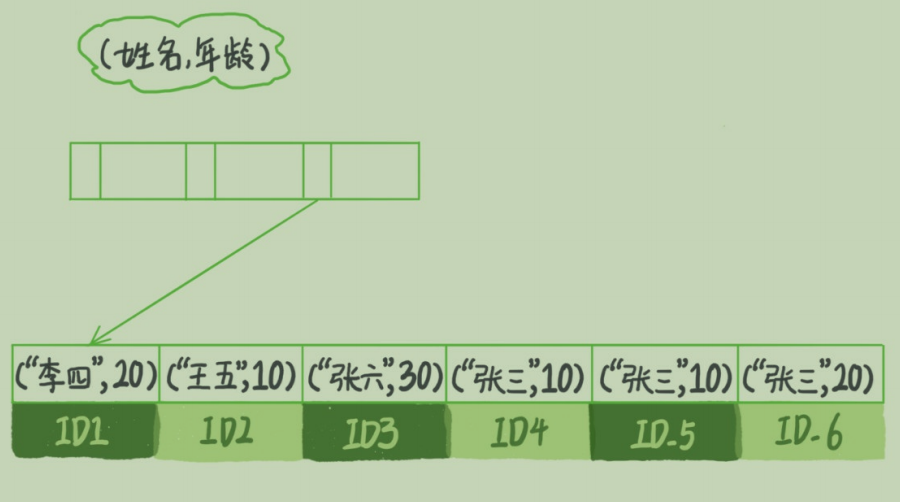
【MySQL实战笔记】 05 | 深入浅出索引(下)-02
代理IP安全问题:在国外使用代理IP是否安全
动态IP代理技术的实际使用
Squid中正向代理的配置与使用
探索机器学习中的支持向量机(SVM)算法
构筑安全之盾:云计算环境下的网络安全与信息保护策略
利用Python帮你抢秒杀
C# webbrowser控件设置代理IP访问网站
代理IP技术在云函数中的创新应用与拓展空间
深入解析PHP的命名空间和自动加载机制
如何快速搭建实用的管理平台
集合进阶Map集合
滚雪球学Java(16):玩转JavaSE-do-while循环语句:打破传统思维模式
商品比价系统实现
如何在事件处理方法中获取事件的来源对象?
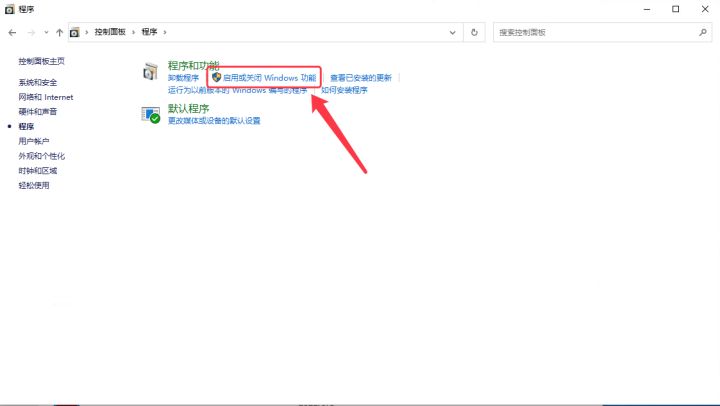
Windows如何使用IIS服务搭建本地WebDAV网站并实现远程管理储存文件
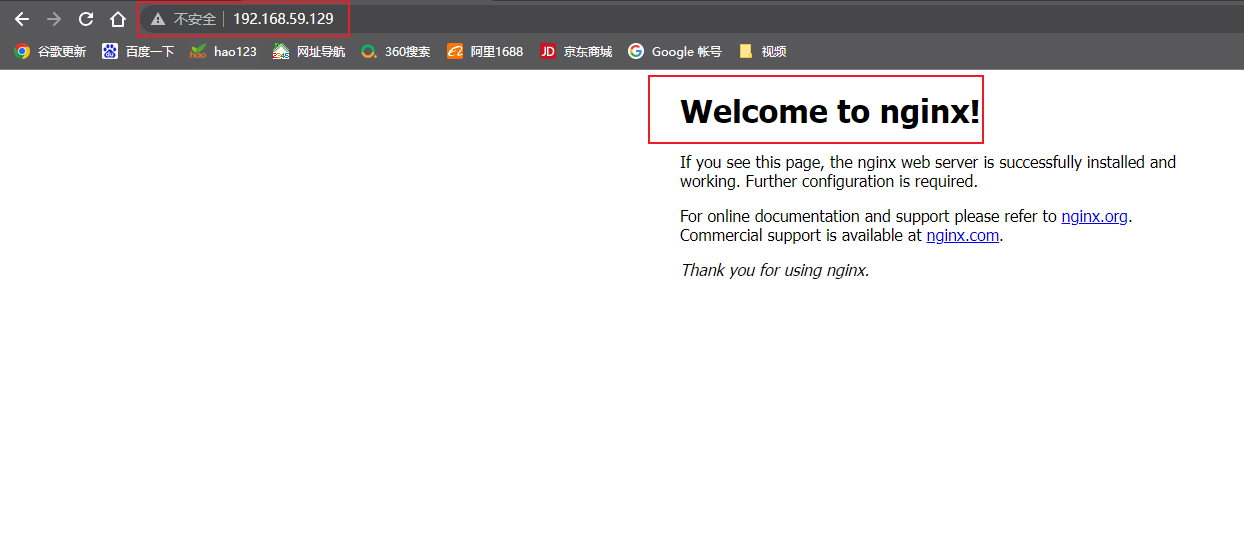
树莓派安装Nginx服务结合内网穿透实现无公网IP远程访问
Python框架选择与使用:推荐几个常用的高效框架
java的事件驱动如何实现
事件驱动架构的优势
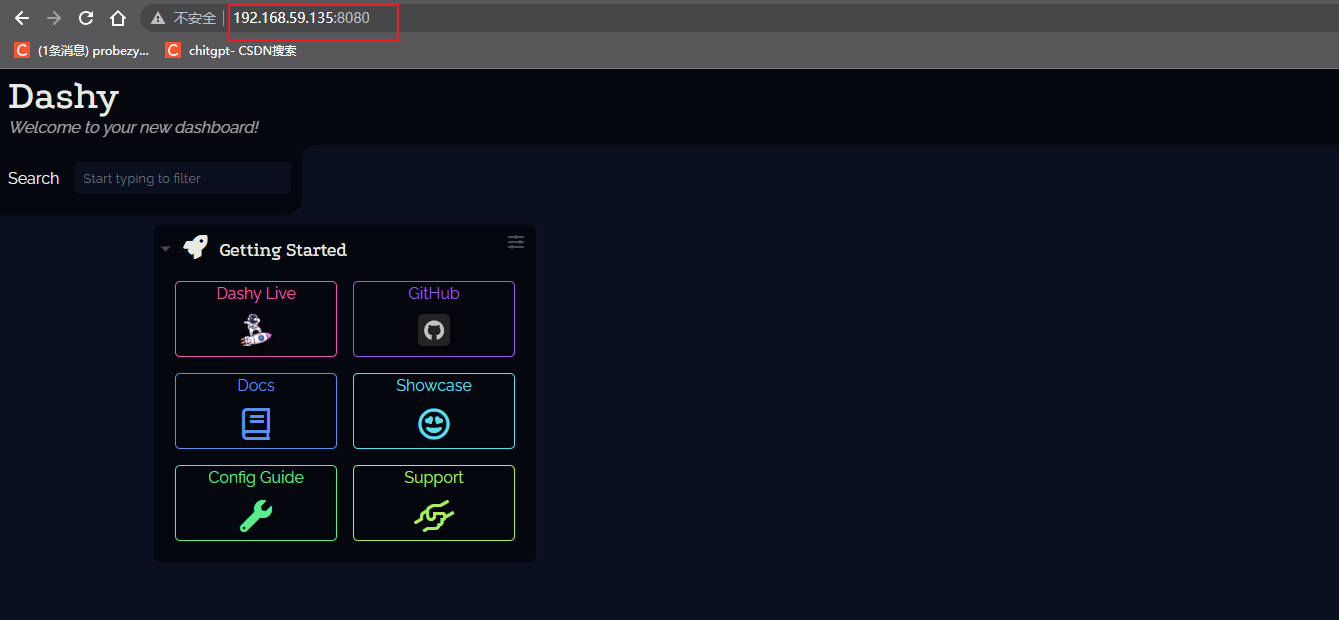
Linux系统使用Docker部署Dashy导航页服务并实现公网环境访问
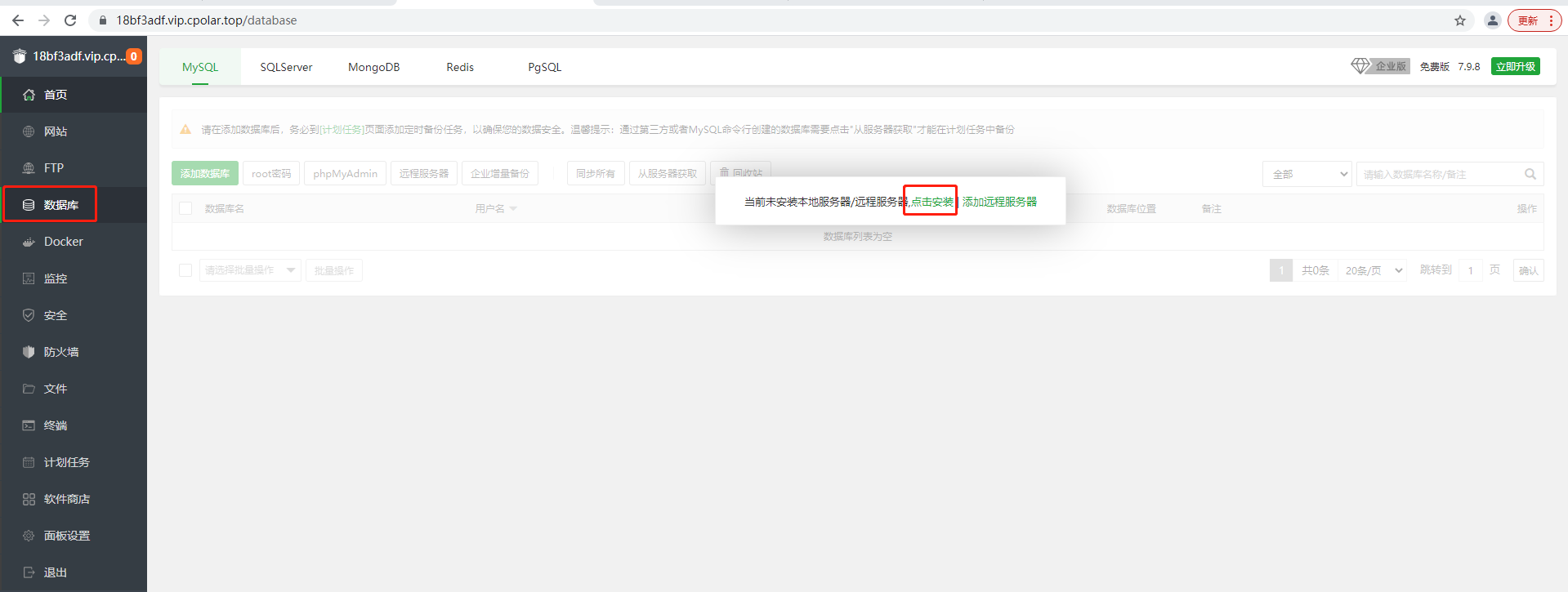
如何使用宝塔面板搭建MySQL数据库并实现无公网IP远程访问
基于SpringBoot+Vue+uniapp微信小程序的4S店客户管理系统的详细设计和实现
代理IP助力云函数实现更高效的网络通信
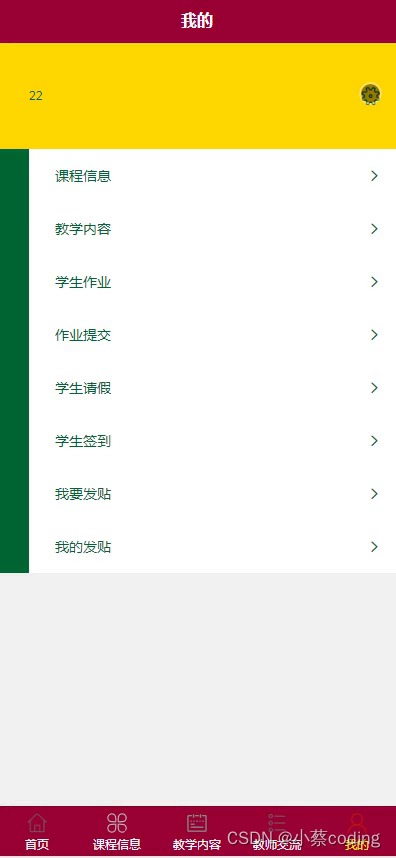
基于SpringBoot+Vue+uniapp微信小程序的在线课堂微信小程序的详细设计和实现
基于SpringBoot+Vue+uniapp微信小程序的微信课堂助手小程序的详细设计和实现
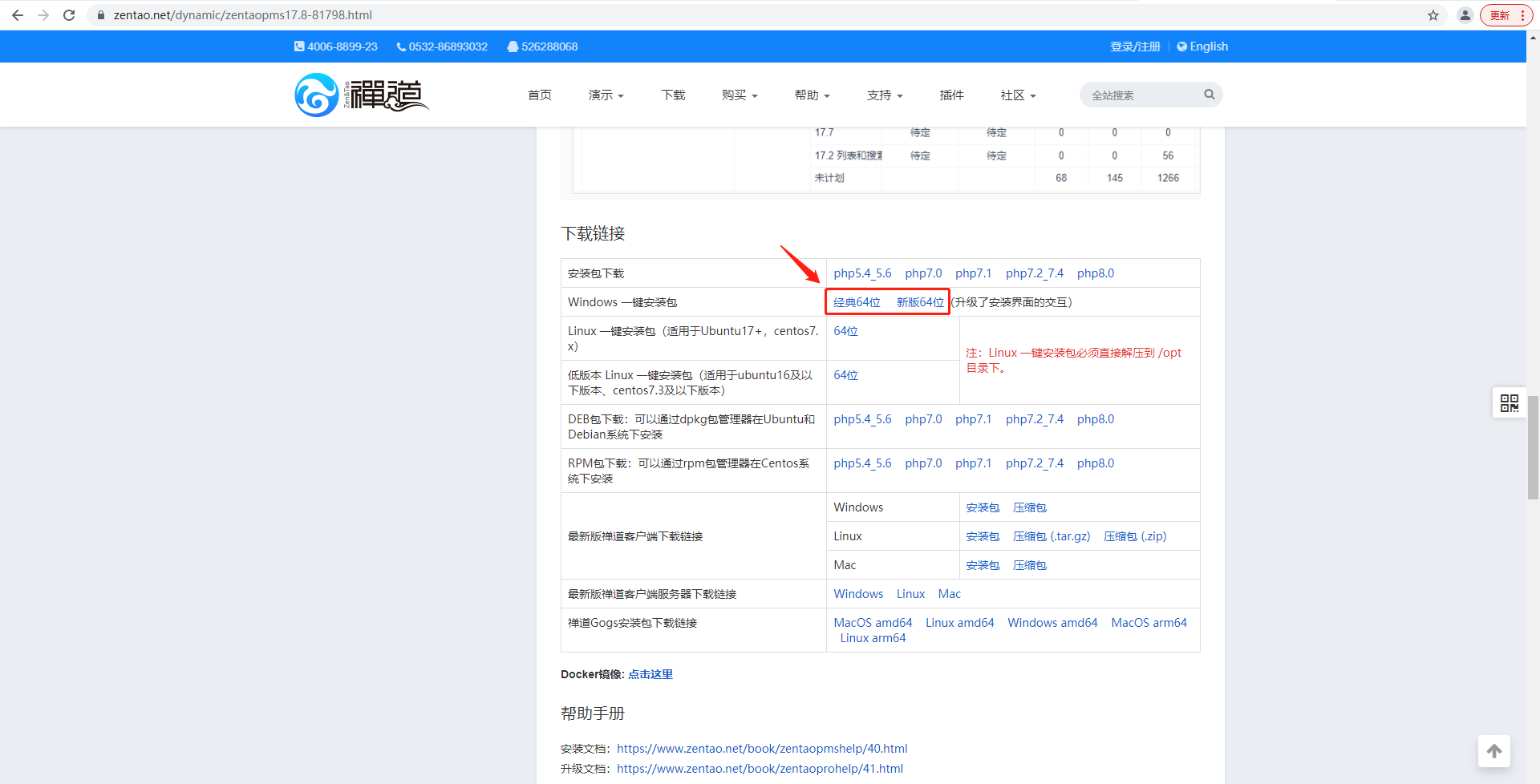
Windows安装禅道系统结合Cpolar实现公网访问内网BUG管理服务
IP代理池的搭建与使用指南
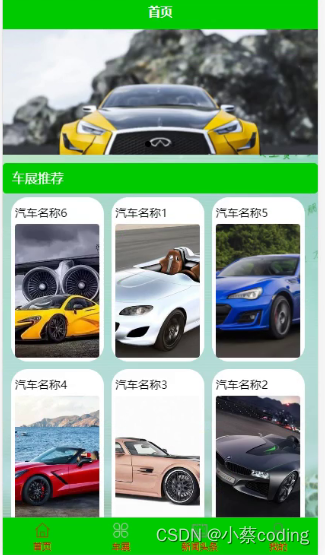
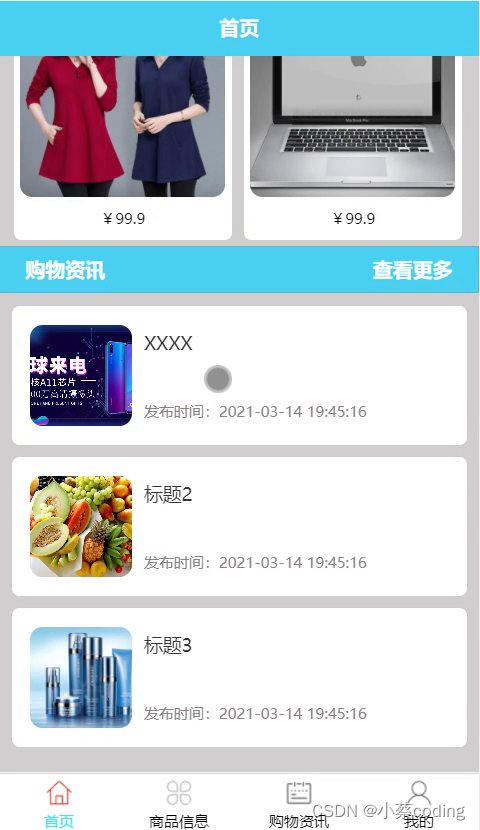
基于SpringBoot+Vue+uniapp微信小程序的商品展示的详细设计和实现
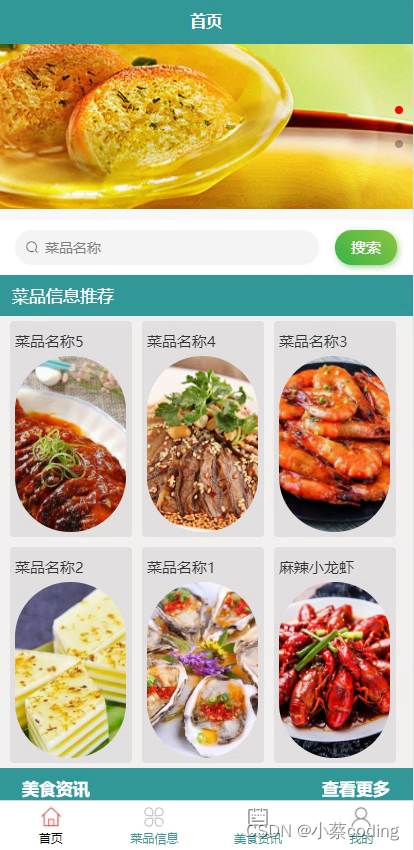
基于SpringBoot+Vue+uniapp微信小程序的微信点餐小程序的详细设计和实现
php遇到内存溢出
基于SpringBoot+Vue+uniapp微信小程序的电子商城购物平台的详细设计和实现