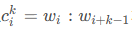PageRank
由于TextRank是由大名鼎鼎的Google的PageRank算法转化而来,所以这里先介绍一下PageRank算法。
PageRank最开始用来计算网页的重要性。在衡量一个网页的排名时,直觉告诉我们:
(1)一个网页被更多网页链接时,就应该越重要,其排名就应该越靠前。
(2)排名高的网页应具有更大的表决权,即当一个网页被排名高的网页所链接时,其重要性也应该提高。
所以基于以上两点,PageRank算法所建立的模型非常简单:一个网页的排名等于所有链接到该网页的网页的加权排名之和。

整个www可以看作一张有向图图,节点是网页。如果网页A存在到网页B的链接,那么有一条从网页A指向网页B的有向边。
S(Vi)是网页i的中重要性(PR值)。d是阻尼系数,一般设置为0.85。In(Vi)是存在指向网页i的链接的网页集合。Out(Vj)是网页j中的链接存在的链接指向的网页的集合,|Out(Vj)|是集合中元素的个数。
通俗来说也就是,对于网页i来说,它的重要性,取决于指向网页i的每个网页的重要性之和来决定的。每个指向到网页i的重要性S(Vj)还需要对所有它所指出去的页面平分,所以要除以|Out(Vj)。同时,该页面S(Vj)的重要性不能单单由其他的链接页面决定,还包含一定的概率来决定要不要接受由其他页面来决定,这也就是d的作用。
但是,为了获得某个网页的重要性,而需要知道其他网页的重要性,这不就等同于“是先有鸡还是先有蛋”的问题了么?幸运的是,PageRank采用power iteration方法破解了这个问题怪圈。先给定一个初始值,然后通过多轮迭代求解,迭代到最后就会收敛于一个结果。当差别小于某个阈值时,就可以结束迭代了。
TextRank
正规的TextRank公式在PageRank的公式的基础上,引入了边的权值的概念,代表两个句子的相似度。
TextRank 一般模型可以表示为一个有向有权图 G =(V, E), 由点集合 V和边集合 E 组成, E 是V ×V的子集。图中任两点 Vi , Vj 之间边的权重为 wji , 对于一个给定的点 Vi, In(Vi) 为 指 向 该 点 的 点 集 合 , Out(Vi) 为点 Vi 指向的点集合。点 Vi 的得分定义如下:

其中, d 为阻尼系数, 取值范围为 0 到 1, 代表从图中某一特定点指向其他任意点的概率, 一般取值为 0.85。
使用TextRank 算法计算图中各点的得分时, 需要给图中的点指定任意的初值, 并递归计算直到收敛, 即图中任意一点的误差率小于给定的极限值时就可以达到收敛, 一般该极限值取 0.0001。
由于引入了句子的相似度,所以正规的TextRank公式是用来从文章中自动抽取关键句,但是我们现在是想计算关键字,如果把一个单词视为一个句子的话,那么所有句子(单词)构成的边的权重都是0(没有交集,没有相似性),所以分子分母的权值w约掉了,算法退化为PageRank。所以说,关键字提取算法也就是PageRank。
对于提取关键词来说,假如设窗口大小为5,In(Vi)是与词i的距离不大于5的词的集合。Out(Vj)是与词j距离不大于5词的集合,|Out(Vj)|是集合中元素的个数。
示例
对于句子:
程序员(英文Programmer)是从事程序开发、维护的专业人员。一般将程序员分为程序设计人员和程序编码人员,但两者的界限并不非常清楚,特别是在中国。软件从业人员分为初级程序员、高级程序员、系统分析员和项目经理四大类。
首先对这句话分词,得出分词结果:
[程序员/n, (, 英文/nz, programmer/en, ), 是/v, 从事/v, 程序/n, 开发/v, 、/w, 维护/v, 的/uj, 专业/n, 人员/n, 。/w, 一般/a, 将/d, 程序员/n, 分为/v, 程序/n, 设计/vn, 人员/n, 和/c, 程序/n, 编码/n, 人员/n, ,/w, 但/c, 两者/r, 的/uj, 界限/n, 并/c, 不/d, 非常/d, 清楚/a, ,/w, 特别/d, 是/v, 在/p, 中国/ns, 。/w, 软件/n, 从业/b, 人员/n, 分为/v, 初级/b, 程序员/n, 、/w, 高级/a, 程序员/n, 、/w, 系统/n, 分析员/n, 和/c, 项目/n, 经理/n, 四/m, 大/a, 类/q, 。/w]
然后去掉里面的停用词,比如标点符号、常用词、以及“名词、动词、形容词、副词之外的词”。得出实际有用的词语:
[程序员, 英文, 程序, 开发, 维护, 专业, 人员, 程序员, 分为, 程序, 设计, 人员, 程序, 编码, 人员, 界限, 特别, 中国, 软件, 人员, 分为, 程序员, 高级, 程序员, 系统, 分析员, 项目, 经理]
然后我们首先计算距离每个词距离不大于窗口大小的词的集合,然后根据公式进行迭代,直到所有词的重要性收敛到某一个值的时候,就可以停止迭代并输出结果。
package Test;
import java.util.*;
import java.util.Map.Entry;
/**
* 基于TextRank算法的关键字提取,适用于单文档
*/
public class TextRankKeyword {
final static float d = 0.85f;//阻尼系数,一般取值为0.85
final static int max_iter = 200;//最大迭代次数
final static float min_diff = 0.001f;//最小区别值,当收敛程度小于这个值结束迭代
/**
* 使用已经分好的词来计算rank
*/
public static Map<String, Float> getRank(List<String> termList, int windowSize) {
List<String> wordList = new ArrayList<String>(termList.size());//去掉停用词后的词序列
for (String str : termList) {
wordList.add(str);
}
//System.out.println(wordList);
Map<String, Set<String>> words = new LinkedHashMap<String, Set<String>>();//词和它对应的邻居们
Queue<String> que = new LinkedList<String>();//用一个队列来表示窗口的移动
for (String w : wordList) {
if (!words.containsKey(w)) {
words.put(w, new TreeSet<String>());
}
if (que.size() >= windowSize) {//如果队列长度大于窗口大小了,则把队列头元素移除
que.poll();
}
for (String qWord : que) {
if (w.equals(qWord)) {
continue;
}
//既然是邻居,那么关系是相互的,遍历一遍即可
words.get(w).add(qWord);
words.get(qWord).add(w);
}
que.offer(w);//将w添加到队列尾部
}
//System.out.println(words);
Map<String, Float> score = new LinkedHashMap<String, Float>();//每一轮迭代后的词和对应的权值
for (int i = 0; i < max_iter; ++i) {
Map<String, Float> m = new LinkedHashMap<String, Float>();//此次迭代中的结果
float max_diff = 0;//此次迭代中变化最大的权值
for (Map.Entry<String, Set<String>> entry : words.entrySet()) {
String key = entry.getKey();
Set<String> value = entry.getValue();
m.put(key, 1 - d);
for (String element : value) {
int size = words.get(element).size();
if (key.equals(element) || size == 0) continue;
m.put(key, m.get(key) + d / size * (score.get(element) == null ? 0 : score.get(element)));
//按照公式计算新的权值
}
max_diff = Math.max(max_diff, Math.abs(m.get(key) - (score.get(key) == null ? 0 : score.get(key))));
}
score = m;//新一轮的迭代结果存进score中
if (max_diff <= min_diff) break;//变化最大的权值小于min_diff,结束迭代
}
return score;
}
public static void main(String[] args) {
String[] s={"程序员", "英文", "程序", "开发","维护", "专业",
"人员", "程序员", "分为", "程序", "设计", "人员",
"程序", "编码", "人员", "界限", "特别", "中国",
"软件", "人员", "分为", "程序员", "高级", "程序员",
"系统", "分析员", "项目", "经理"};
List<String> termList = Arrays.asList(s);
int windowSize=5;//窗口大小
Map<String, Float> map=getRank(termList,windowSize);
for (Entry<String, Float> entry : map.entrySet()) {
String key = entry.getKey();
float value = entry.getValue();
System.out.println(key+"="+value);
}
}
}
结果:
程序员=1.9249978
英文=0.7098714
程序=1.4025854
开发=0.82074183
维护=0.9321688
专业=0.9321688
人员=1.629035
分为=1.4027836
设计=0.6992446
编码=0.82671607
界限=0.8220693
特别=0.9335202
中国=0.9341458
软件=0.93525416
高级=0.97473735
系统=0.885048
分析员=0.7710108
项目=0.7710108
经理=0.64640945