摘要:万事万物每时每刻都在产生大量的数据,数据无处不在,数据化运营在今天的物流、零售、电商、金融等等行业中都有诸多成功的实践,但是如何降低企业大数据的建设门槛,使得大数据分析成为一种人人都可以获得的普惠能力呢?在本文中,阿里云高级算法专家缪长风(刘林豆)就为大家分享了如何基于AnalyticDB构建企业实时数仓。
本文根据演讲视频以及PPT整理而成。
本次分享主要将围绕以下三个部分:
1.开启数据实时化时代
2.如何构建实时数仓平台
3.实时数仓未来展望
一、开启数据实时化时代
数据实时化发展趋势

虽然在以前的时候数据量也很大的,只不过大家没有发现数据的价值。现在比较明显的趋势就是只要一个系统上线,必须要对其进行非常好的profile,也就是对其进行很好地量化。当一个新系统上线之后一定会带来非常多的数据,当一个新业务上线则也一定会增加非常多的埋点。所以这里想要分享的第一个趋势就是数据量在当前增长得非常快。第二个趋势就是全数据化,当系统上线了,增加了这么多的profile,但是如果只有这些数据,但是并不对这些数据进行分析就没有办法去度量这些东西,那么业务就依然不会有很长久的生命力,因为不知道接下来会往哪里面进行引进。对于全数据化而言,其实大家都知道没有数据化的企业是没有生命力的,没有数据化的创新一定不会持久,因为不知道接下来的方向应该哪里走。第三个趋势就是处理高效,第三个趋势是因为在第一和第二个趋势的基础上会迸发出越来越多的需求,如果数据处理不够高效,就会导致你发现某些趋势比别人晚,那么业务转身就会慢很多。
传统解决方案-剖析
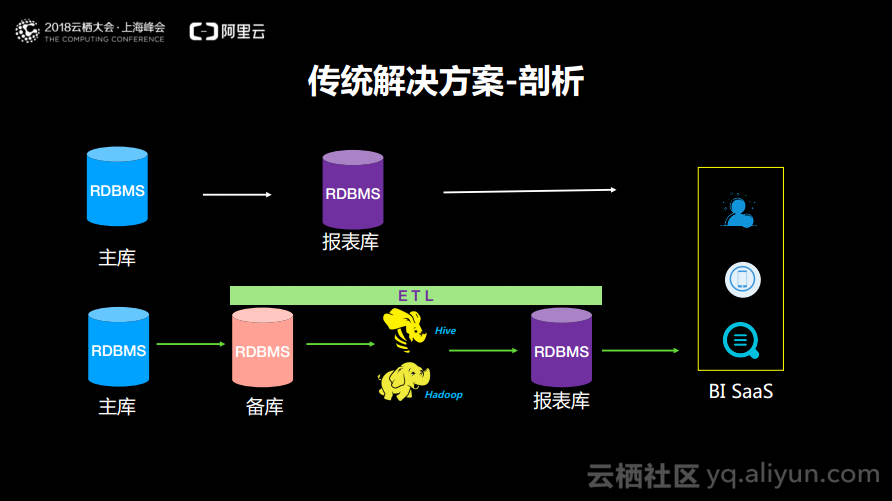
早些年的时候,在阿里巴巴也是采用这样传统的解决方案。而现在不少云上的创业企业也还是这么做的,也就是首先会有一个主库,然后在主库上进行计算或者在备库上计算,计算完成之后再同步到报表库。也有人把自己备库当成了报表库,想要任何数据就需要从备库中查询,查询完成之后就可以做一些BI的SaaS层的展现。这也是目前很多云上初创企业的做法,就是第一时间先将业务系统弄上线,然后再来发展数据化,所以这样的一条道路也是用的最多的。而当业务系统已经有了非常大的起色之后,业务已经盈利了,这时候就可以考虑一些不赚钱的事情了——大数据。下面这条方案一般是体量稍微大一些的客户所做的。常用的做法就是将数据实时地抽取到Hadoop或者其他的处理平台上去,然后每天以小时级别进行计算,计算完成之后流到报表库,这个报表库往往是单机的RDBMS。首先会发现这些Hadoop以及Batch的Job时效性会是一个问题,最多能做到小时级别,而老板往往希望把业务的监控大盘做到秒级别、分钟级别,这就产生了瓶颈。第二个问题点就是数据计算完成之后回到了报表库里面,报表库用的最多的就是MySQL或者PESQL等关系型数据库。当报表库的数据越来越大的时候,就会发现BI的SaaS层的处理就会非常慢。举个列子,我们没有办法将所有的数据都在Hadoop的Hive里面实现预聚合和预计算。当需要在报表库中做交互式查找的时候,代码就会变得异常复杂,而且单机的MySQL一定会成为非常严重的性能瓶颈。
传统解决方案-问题

传统解决方案还存在两大难题,第一个就是报表库的瓶颈,计算扩展性和存储的限制,如果报表达到了100GB的规模就一定会遇到这样的问题,除非你的SQL是一个简单的不能够在简单的增删改查。第二个难题就是ETL链路太长,这是因为需要配置各种各样抽取的作业,定时地进行触发并管理这些数据到Hadoop里面,在Hadoop里面需要去管理这些ETL的节点,几点钟触发,上下游的依赖关系又是什么等,写完数据之后还需要回流到MySQL报表库中去,链路非常长、时效性差,并且复杂性非常高。
实时数仓标准

阿里云一直在思考能够将建设数据仓库的门槛降得更低一些,一直在思考应该如何去做,有没有什么更加便利的方法。后来就度量了实现一个实时的数据仓库所需要具备的能力。第一个就是NO ETL,数据一定不是需要搬来搬去的,将数据搬来搬去一定会出现非常大的问题,因为组件越多,传输的链路越长,出问题的概率就一定越大,维护的成本也就一定越高,也只有非常大的企业才有能力做这样的事情。第二个就是高吞吐的写入,因为需要做实时的数仓,所以企业可能有每秒百万条的数据产生,所以需要很高的吞吐才能让数据流进来。而高吞吐写入的第二点就是能够对接多路数据,也就是对于一个实时数仓而言,数据除了MySQL,可能还有一些日志文件,需要考虑多路数据如何流入进来。第三点就是自由查询,因为数据已经能够实时地以秒级别地落入到实时数仓里面去了,那么就需要考虑查询是否可以支持足够复杂的Query,能否搞定实时交易,这就相当于是自由查询,因为不需要做太多的ETL和预聚合,这里面对自由查询的要求是非常高的,要求SQL条件能够任意地去组合,并且使得分析秒级可见,否者就不能称为一个实时数仓。因为实时数仓一定是交互式的产品,如果查询都到了分钟级别,那么就一定不是交互式的产品了。第四点就是全分布式的,企业接入了实时数仓之后,企业的业务量可能一年会增长10倍,今天购买了4个节点,可能明天就会需要400个节点,所以需要实现全分布式。以上就是构建实时数仓的四大标准。
二、如何构建实时数仓平台
接下来分享如何构建实时数仓平台。这部分将会主要围绕阿里云实时数仓平台AnalyticDB这款产品。虽然这款产品已经上线了很长时间了,但是一些用户还是不太了解。这款产品之前一直在服务于阿里内部以及一些政企,也就是体制内的企业,没有在公有云上做大规模的推广和宣传。
实时数仓平台AnalyticDB
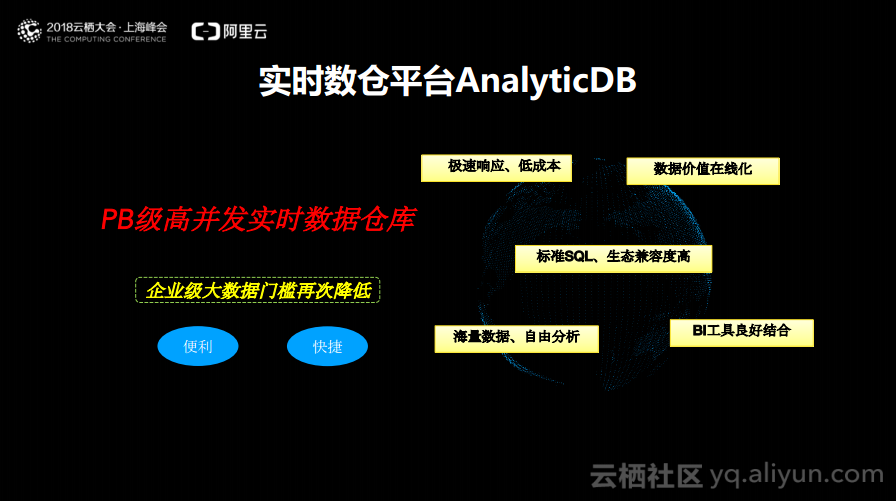
实时数仓平台AnalyticDB的定位就是PB级高并发实时数据仓库,其使命是使企业级大数据建设门槛再次降低,以轻量级的产品使得企业享受到数据所带来的价值。实时数仓平台AnalyticDB具有以下五大关键特性:
1.极速响应、低成本
2.数据价值在线化
3.标准SQL、生态兼容度高
4.海量数据、自由分析
5.BI工具良好结合
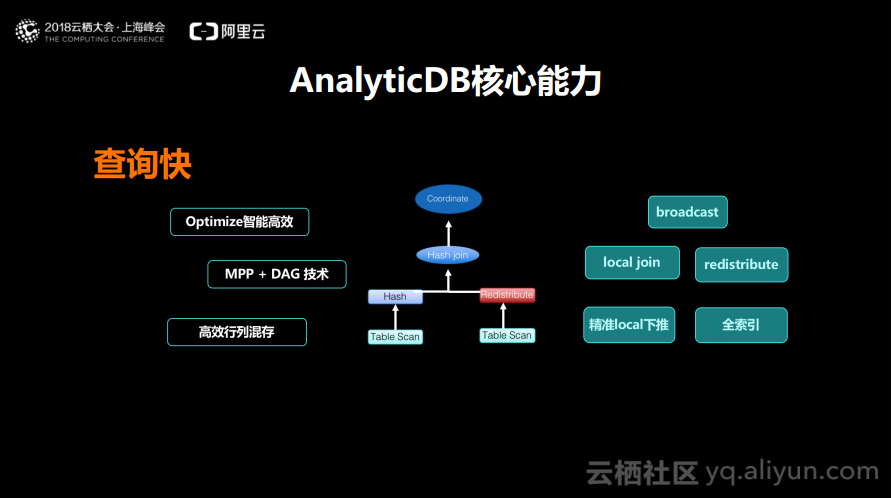
接下来分享一下AnalyticDB的几大核心能力。第一点就是查询快,如果查询不够快,那么一定不是一个实时的交互式的数据库。阿里云对于AnalyticDB的定位是能够直接对接BI的SaaS层的或者报表层的,所以要求一定是查询快,如果查询发出去,等电脑屏保都出现了还没有查询完这个实时数据库一定是不合格的。查询快主要体现在三个方面:首先是高效的Optimize;第次使用了MPP+DAG混合的技术来提升调度,提升复用的能力,降低企业的成本;第三个就是使用高效的行列混合存储技术来尽量介绍底层的Seek IO,尽量提升数据块Block抓取的有效性。通过以上三点能够使得AnalyticDB在数据量线性增长的前提下实现性能的毫秒级别的交互。
AnalyticDB核心能力:极度灵活

AnalyticDB产品的第二大核心优势就是极度灵活。这是什么意思呢?其实做数据库的很多人就会困惑于在阿里云上买数据库数量买多了或者规格买高了怎么办。而AnalyticDB却是极度灵活的,只需要在控制台上简单点击就能够实现规格配置的自由升降。虽然这样弹性伸缩的能力看似是云上很普惠的能力,但是对于数据库产品而言,真正能够做到这样的的确不多。而且AnalyticDB极度灵活还有一个杀手锏,就是当你发现自己的实例买多了,可以一键式完成实例数量的动态调整。也就是说,AnalyticDB在单个规格和实例数量之间灵活地变来变去,可以升高或者降低配置,也可以增加或者减少实例个数。这对于企业以及数据库架构师而言,就能够实现非常灵活地控制成本。
AnalyticDB核心能力:支持高并发
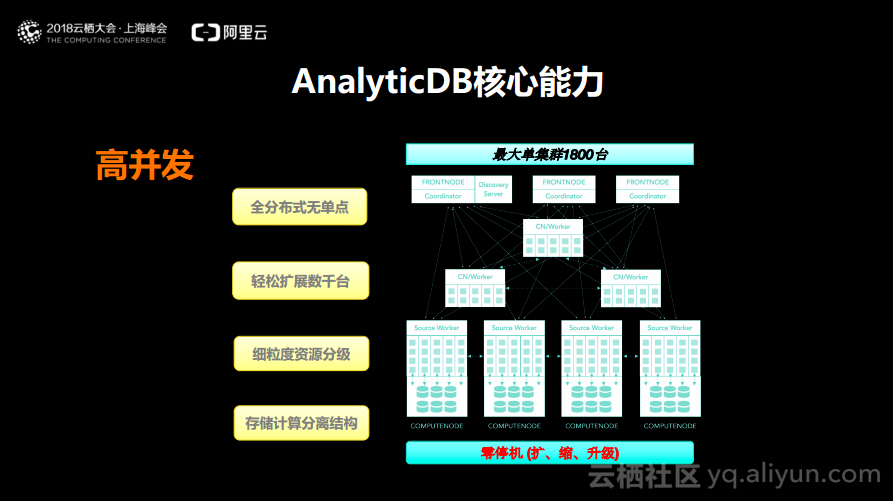
AnalyticDB的第三个能力就是支持高并发,因为在实时数仓里面需要对于数据进行处理,需要面对非常复杂的数据分布以及查询,如果不能够支持高并发,可能就会导致很多问题。AnalyticDB所支持的高并发是可以实现全分布式无单点,可以轻松扩展数千台,可以实现细粒度资源分级以及存储计算分离的结构。在阿里巴巴内部规模最大的集群已经做到1800台物理机,所以大家根本不必担心在云上会遇到容量的瓶颈问题。也正是通过存储与计算分离的结构,使得AnalyticDB的规格、数量可以任意地变来变去,而这是传统的MySQL等数据库中很难见到的,也可以实现在扩容缩容以及升级的过程中,实现零停机,可以完全做到副本切换不影响业务。
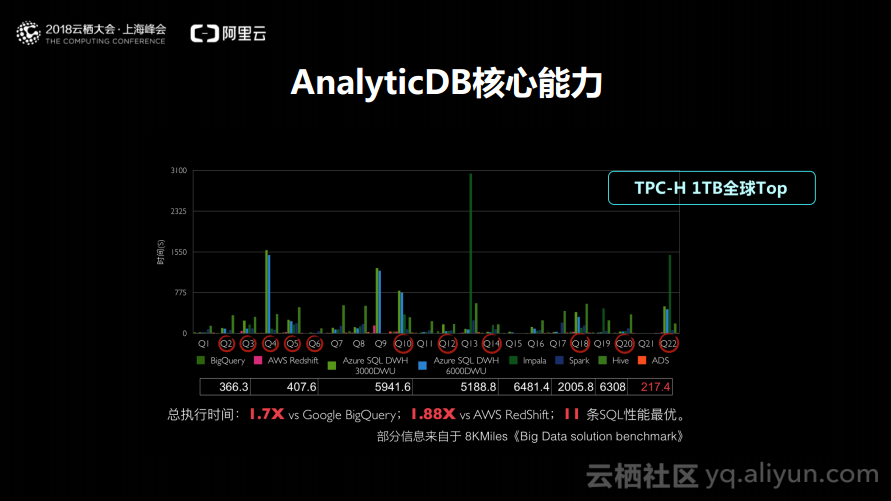
如下图所示的是去年AnalyticDB跑的TPC-H 1TB的测试。在8KMiles所公布的数据中位于第一。
构建实时数仓平台
接下来分享应该如何基于AnalyticDB构建实时数仓平台。数据一般会分为这样的几类,第一类是日志,在企业中分析的非常大的数据来源就是日志,因为需要计算PV、UV等数据,这些数据都来源于日志。
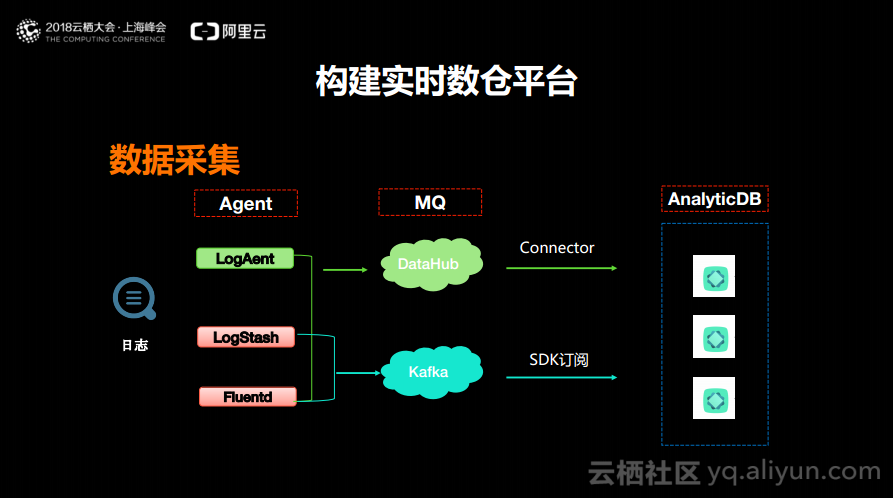
日志采集用的比较多是阿里云上的LogAgent、LogStash以及Fluentd。日志通过配置并启动LogAgent,就可以将日志数据推倒DataHub上去,DataHub上面设置一个Connector就可以将数据默认地推到AnalyticDB里面去,所以只需要配置一个LogAgent并且在DataHub里面new一个Connector,做这样两个配置,数据就可以进来了。而LogStash和Fluentd在开源方面中使用的比较多,同样的可以通过这两个工具将日志数据上传到Kafka里面,而在Kafka里面则可以SDK、标准的MySQLJDBC协议将数据推到AnalyticDB里面去。以上就是日志数据比较典型的操作,如果大家需要处理日志数据就可以按照这样的方案。
除了日志数据之外,还有数据库的数据,这部分也是比较多的。因为大多数需要分析的数据,最高优先级需要分析的数据就是业务数据,这些数据第一时间往往会出现在数据库里面。当数据已经存在Oracle、MySQL以及SQLServer等数据库的时候,想要将数据推入AnalyticDB只需要在DTS上新增一个配置即可,DTS支持全量+增量的数据同步,可以先做全量再做增量,从而将数据迁移到AnalyticDB中。当业务数据库做实时写入的时候,DTS会把拿到的BinLog数据投递到AnalyticDB中,这样一来就可以在AnalyticDB里面运行各种分析的SQL。
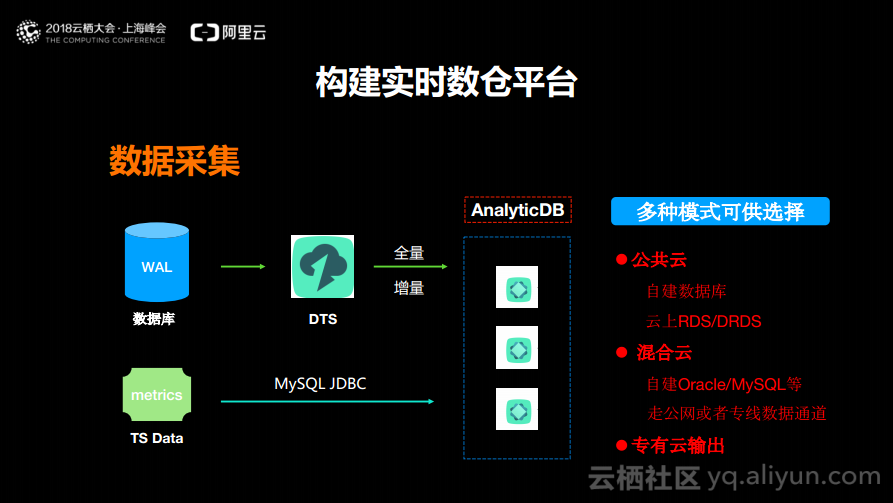
此外还有一类数据叫做TS Data,也就是Metric的数据,所谓Metric的数据就是系统有很多监控的数据和时序的数据,在产生之后可能会觉得这些数据量大,因此是不会将这些数据落盘的,也不会落到数据中,只可能是在进程中的某个端口,做分钟级别的聚合。当然也可以将Metric数据用MySQL JDBC写入到AnalyticDB中去。
综上所述,对于日志、数据库中的数据以及TSData这三种数据而言,都可以通过上述的方式轻松地将数据接入到AnalyticDB里面来。而关于数据库这部分,目前DTS支持多种模式,在公有云上面,如果是自建的数据库可以通过DTS将数据推倒AnalyticDB进行各种复杂分析;如果使用的是云上的RDS或者DRDS,数据也一样可以通过DTS同步进来。对于一些大企业而言,可能数据不在云上,DTS还支持混合云架构,可以架构大家自建的MySQL或者Oracle等自建机房的数据上传到云上面。还有的公司不想和公有云产生任何关联,这个方案还支持专有云。
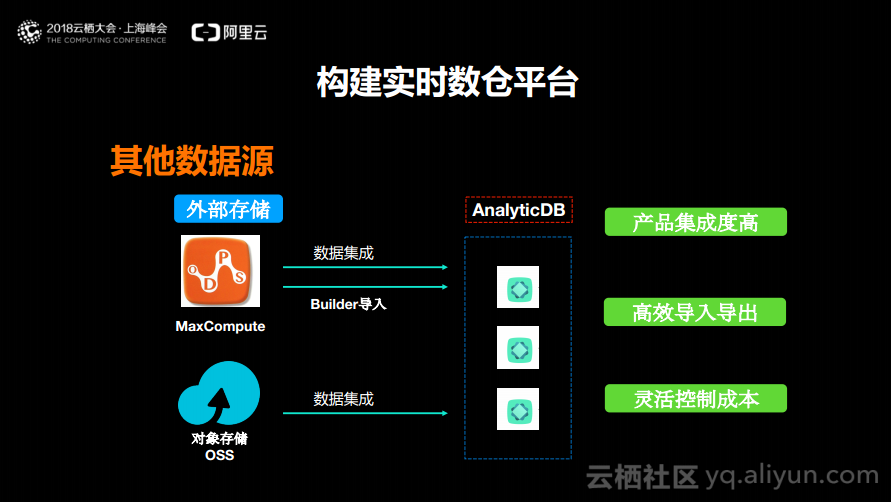
接下来分享其他数据源应该如何进来。首先是阿里云大数据计算平台MaxCompute,其实AnalyticDB能够支持数据集成,能够轻松地将数据实时地加载到AnalyticDB中。如果在MaxCompute中存在大量的数据并且想要做一次性的初始化,而不希望运行得太慢,AnalyticDB还支持Build导入,可以实现一个Job完成1TB数据的导入。还有一类数据来源就是OSS,也可以通过数据集成将数据加载到AnalyticDB里面去。
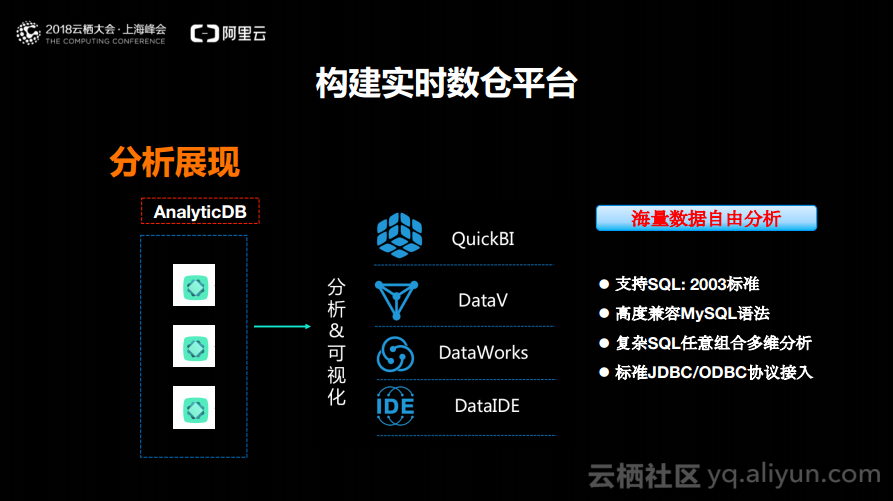
接下来分享AnalyticDB在分析和展现层上面的一些能力以及所支持的BI化产品,包括了QuickBI、DataV、DataWorks以及DataIDE。这些都可以直接对接到AnalyticDB,去做各种相关分析。之所以可以做到这一点是因为AnalyticDB支持SQL 2003标准,高度兼容MySQL语法,能够支持复杂SQL的任意组合并且支持标准的JDBC以及ODBC协议的接入。
如下图所示,目前AnalyticDB也有了很多的案例客户,比如淘宝内部的生意参谋、递四方、EMS、菜鸟物流、天弘基金以及ofo等。

三、实时数仓未来展望
在实时数据分析领域里面一定有很多数据没有办法进行分析,比如对于一串复杂的文本,可能就需要对于某些关键词进行提取,提取关键词之后就可以知道他们处于哪些记录里面。而传统的分析引擎是无法将这些记录与结构化数据结合到一起的。

未来数仓的一个趋势就是融合分析,比如以图搜图,结合面部表情以及线上信息就能够知道图片里是什么样的人,但是也需要和某些历史行为表现作对比,而这些也是传统的数据库无法实现的,因为需要结合结构化和非结构化的数据进行分析。第二个趋势就是硬件加速,需要集成GPU和FPGA,AnalyticDB未来会支持GPU加速,因为大家都知道可以将一些复杂的算子落到硬件上计算的,能够很好地提升计算能力。第三个趋势就是Data Lake的分析与挖掘,在未来云上的数据分析一定不是All in One的,数据仓库一定不是终点,其他的大数据分析平台也一定不是终点。未来云上的数据可能是散落在各个地方的,一定是用最廉价、最高效的、最灵活的组合实现的。对于这样数据散落在各个地方的Data Lake应该如何作分析呢?其实这也是云上数仓的趋势,也就是下层是散落在各个地方的最适合、最廉价存储,上面则是廉价的分析,所以未来数仓的趋势是以最廉价的存储搭配最廉价的分析实现的,而All in One绝对不是终局。
Data Lake Analytics发布
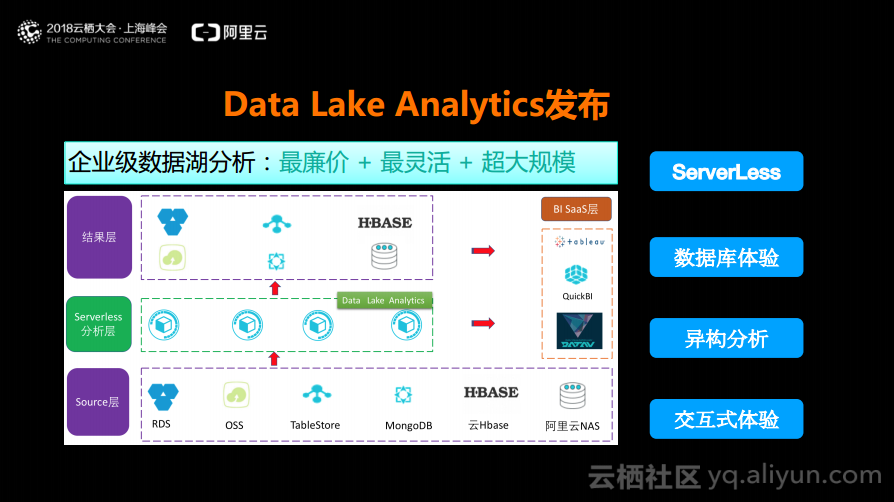
未来数仓的趋势是以最廉价的存储搭配最廉价的分析,什么是最廉价的分析?一定是Serverless的。什么是最廉价的存储?一定是你认为什么便宜就可以将数据存储在什么地方的。Data Lake Analytics则是去做基于下层存储的Source层的Serverless的异构分析。这款产品可以直接分析OSS以及Table Store上的数据,并且可以对这两种数据进行关联分析。Data Lake Analytics产品的定位是Serverless的异构数据源的DataLake的关联分析。举个例子,如果未来大家想做数据清洗就可以“insert MySQL.a表 from select OSS.bBucket joinMySQL.c表”,不要将数据搬来搬去,只需要一句SQL就能够实现将各个数据源的数据实时分析完之后放到结果层里面。未来,Data Lake场景一定是大的趋势,下一代的企业级数据分析一定是在云上用最廉价的存储搭配最廉价的分析。而Data Lake足够灵活,并且成本也足够低,也能够极大地提升效率。Data Lake目前在阿里云上已经开始公测了,大家可以申请体验。
本文根据演讲视频以及PPT整理而成。
本次分享主要将围绕以下三个部分:
1.开启数据实时化时代
2.如何构建实时数仓平台
3.实时数仓未来展望
一、开启数据实时化时代
数据实时化发展趋势
传统解决方案-剖析
传统解决方案-问题
实时数仓标准
二、如何构建实时数仓平台
接下来分享如何构建实时数仓平台。这部分将会主要围绕阿里云实时数仓平台AnalyticDB这款产品。虽然这款产品已经上线了很长时间了,但是一些用户还是不太了解。这款产品之前一直在服务于阿里内部以及一些政企,也就是体制内的企业,没有在公有云上做大规模的推广和宣传。
实时数仓平台AnalyticDB
1.极速响应、低成本
2.数据价值在线化
3.标准SQL、生态兼容度高
4.海量数据、自由分析
5.BI工具良好结合
这里面有几点值得提一下,就是当性能等各方面都很好,那么如何让大家在各方面都能够很好地接受呢?首先要去支持标准SQL,通过BI的SaaS工具很好地去提升,也就是如果你的SaaS工具能够支持标准的JDBC、ODBC就可以直接对接到AnalyticDB上去。如果你会SQL,想要分析自己的数据,只需要将数据接入到AnalyticDB这款实时数仓的产品上去就可以了。
AnalyticDB核心能力:极度灵活
AnalyticDB核心能力:支持高并发
如下图所示的是去年AnalyticDB跑的TPC-H 1TB的测试。在8KMiles所公布的数据中位于第一。
接下来分享应该如何基于AnalyticDB构建实时数仓平台。数据一般会分为这样的几类,第一类是日志,在企业中分析的非常大的数据来源就是日志,因为需要计算PV、UV等数据,这些数据都来源于日志。
除了日志数据之外,还有数据库的数据,这部分也是比较多的。因为大多数需要分析的数据,最高优先级需要分析的数据就是业务数据,这些数据第一时间往往会出现在数据库里面。当数据已经存在Oracle、MySQL以及SQLServer等数据库的时候,想要将数据推入AnalyticDB只需要在DTS上新增一个配置即可,DTS支持全量+增量的数据同步,可以先做全量再做增量,从而将数据迁移到AnalyticDB中。当业务数据库做实时写入的时候,DTS会把拿到的BinLog数据投递到AnalyticDB中,这样一来就可以在AnalyticDB里面运行各种分析的SQL。
综上所述,对于日志、数据库中的数据以及TSData这三种数据而言,都可以通过上述的方式轻松地将数据接入到AnalyticDB里面来。而关于数据库这部分,目前DTS支持多种模式,在公有云上面,如果是自建的数据库可以通过DTS将数据推倒AnalyticDB进行各种复杂分析;如果使用的是云上的RDS或者DRDS,数据也一样可以通过DTS同步进来。对于一些大企业而言,可能数据不在云上,DTS还支持混合云架构,可以架构大家自建的MySQL或者Oracle等自建机房的数据上传到云上面。还有的公司不想和公有云产生任何关联,这个方案还支持专有云。
接下来分享其他数据源应该如何进来。首先是阿里云大数据计算平台MaxCompute,其实AnalyticDB能够支持数据集成,能够轻松地将数据实时地加载到AnalyticDB中。如果在MaxCompute中存在大量的数据并且想要做一次性的初始化,而不希望运行得太慢,AnalyticDB还支持Build导入,可以实现一个Job完成1TB数据的导入。还有一类数据来源就是OSS,也可以通过数据集成将数据加载到AnalyticDB里面去。
三、实时数仓未来展望
在实时数据分析领域里面一定有很多数据没有办法进行分析,比如对于一串复杂的文本,可能就需要对于某些关键词进行提取,提取关键词之后就可以知道他们处于哪些记录里面。而传统的分析引擎是无法将这些记录与结构化数据结合到一起的。
Data Lake Analytics发布






