
摘要:本文从马力作为功率衡量标准为切入点,介绍了大数据领域的计算力衡量标准TPCBB以及MaxCompute2.0在Big Bench上的卓越表现。同时详细地分享了取得优异成绩背后的产品在最新有哪些进展,帮助大家全面的了解MaxCumpute2.0。另外,对于共有云用户非常关注的-数据安全话题,阿里巴巴通过逻辑隔离/资源隔离/运行隔离机制,保障了数据安全,同时实现了安全的数据交换与共享。
演讲嘉宾简介:
云郎,MaxCompute资深产品专家
以下内容根据演讲嘉宾视频分享以及PPT整理而成。
PPT材料下载地址:https://yq.aliyun.com/download/2731
视频地址:https://edu.aliyun.com/lesson_1010_8794?spm=5176.8764728.0.0.x2IAee#_8794
产品地址:https://www.aliyun.com/product/odps
本次的分享主要围绕以下四个方面:
一、背景简介
二、TPCBB
三、MaxCompute2.0演进
四、数据安全
一、背景简介
最近在看一些纪录片,从这里面受到很大的启发,就是它从很多切入点将我们人类的历史真实的再现出来了,在这个过程中我发现在人类的大历史中很多东西都是相通的。我想起来咱们国内一位大家鲁迅说的话“治学要先治史”,通过学习历史,从更深层次上有更多的碰撞,甚至可能上升到哲学的层面,或者文化的层面。所以说搞大数据不可怕,可怕的是搞大数据的还要搞文化。
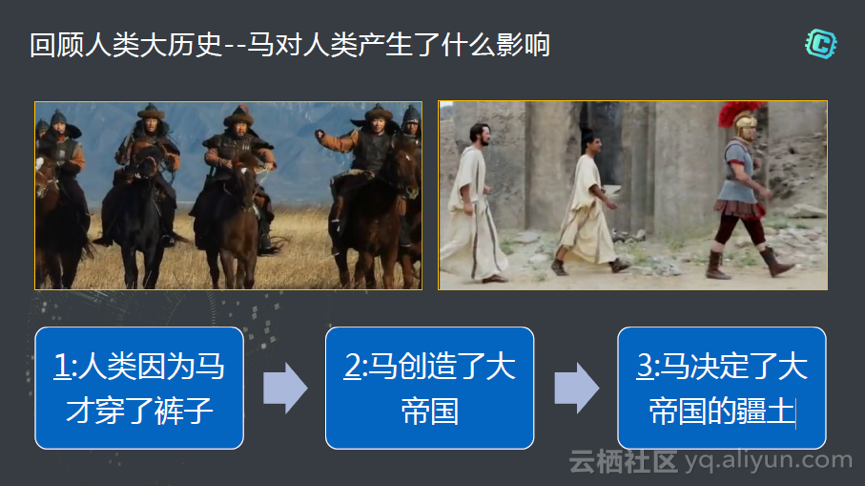
大家有没有看过一个纪录片-人类大历史,它拍了几十集,其中有一集就是讲马的变革,马对人类整个人类历史产生了什么样的影响?小时候学历史有四个字印象比较深,就是胡服骑射。下图中可以很容易想到这是成吉思汗的铁军,另外我们对西方的文明和文化也比较熟悉,提到罗马,看到白袍子的时候可以看到贵族一般穿着很白很白的袍子。在这个纪录片里面,古罗马人的穿着变化就如下图的三个人,逐步演变成三个人都穿裤子,之前都是穿袍子。那么产生的影响,第一个,人类因为马穿上了裤子。第二个,不管是西方的罗马帝国,或者是说我们的成吉思汗的帝国,马起到了很重要的作用,它创造了东方和西方的帝国。同时马决定了疆土,所以马对我们产生了很重要的影响。
整个地球上有6600万个物种,在这么多物种里面为什么马成为了我们人类的最重要的朋友呢?任何事情我们都有很多选择,为什么最终人类会选择马呢?天上飞的昆虫,鸟类很多,是不是可以把它们训练好呢?但问题是它们体量太小,它无法承担人类的重量。第二个,狮子老虎能否训练呢,首先它们很难驯化,另外它们都是肉食动物,吃的比人类还贵,无法饲养。第三类,大象可以表演,很聪明,那么大象为什么不行,因为它体量太大,要把它驯化成大小合适,时间上要花很长很长。最终,只有马结合了我们想要的几方面的优势,第一个马有力量,第二个马的脾性好,第三个,最最重要的就是速度。这是马能成为人力最重要朋友的几点原因。

最早的时候,火车被叫为“铁马”,小汽车最早发明的时候也不叫car,它叫无马马车。到今天,我们做火车,飞机,汽车等,对功率标准的度量叫做“马力”,1公制马力=0.735千瓦(kw)。通过人类大历史,我们知道了马力出现的原因,以及马为什么会成为我们的朋友。

二、TPCBB
那么在大数据领域,我们怎么样去定义它的度量衡呢,作为计算平台,我们怎么样去评估计算力呢?
在最近几年,我们跟国际上很多标准化的组织做了很多大数据方面的benchmark测试,包括最早做sort bench,TPCH,TPC-DS,然后在去年做TPCBB(big bench)。到去年我们发现TPCBB才是衡量大数据计算力的标准。大数据这里面要考虑到数据的种类,有半结构化的,结构化的,以及非结构化的数据,这些都要在场景里面有。另外在分析的场景里面,我们要包含普通的建模,如静态的建模。还有数据的分析和挖掘。还有要做Reporting,因为做报表和静态分析的SQL写法又是不一样的。这是要基本的三个场景。对于查询的类型而言,仅仅有SQL的,做机器学习,自然语言处理,通过标准语言,还有流计算。对于做大数据来说,整个处理的数据,作业,技术要从以上几个角度面面覆盖到。
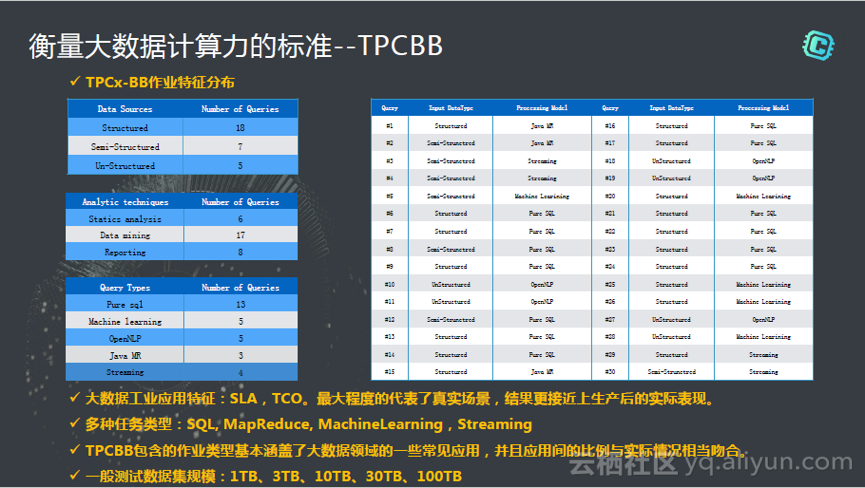
这个测试案例集包含30个,它完整的覆盖了不同的数据类型,不同的技术,不同的查询类型。大家都可以下载到这30个测试集,然后看怎么去做TPCBB。在TPCBB之前是TPC-DS,它在很多面向OLTP场景测试基础外,把我们的benchmark的场景覆盖到了OLAP,就是联机分析的场景。然后TPCBB就进一步的从OLAP延伸,扩展了日志文件,机器学习等等大数据所有的特征。这30个测试场景完整的覆盖了我们对大数据计算层面的全部的诉求。这里面很重要的一点是最大程度代表了真实场景,结果更接近上生产后的实际表现。很多情况下,PB,EB的量级是常见的,目前官方网站上有1TB,3TB,10TB,30TB,最大的规格是100TB。
去年阿里云在北京的云栖大会上,受到一个灵感,跟手机一样,MaxCompute是不是也可以跑个分。在去年做了一个现场跑分,当时调用了北京,深圳的集群,北京的跑得很好,下图是从三个纬度得出的结果。数据集是100TB,首次测试就用了最大的规模。第二个表示每分钟能跑多少任务,我们跑的全球最高8200QPM。还有第三个是成本,达到了最低的$354.7/QPM。所以MaxCompute在数据的容量,性能和性价比上全面的得到了突破。我们找到了大数据的衡量标准,同时也在不断的做优化,期望能得到更多的突破。

三、MaxCompute2.0演进
在计算力得到突破的背后,我们都做了哪些工作。其实MaxCompute在阿里阿巴已经有十年的历史,这十年中并不是一成不变的,从最早开始基本满足阿里巴巴集团内部业务,然后能替代Hadoop,进而成为真正的数据的计算中台,基础设施。在阿里巴巴,99%的存储数据,95%的计算都是跑在MaxCompute上的,我们来看怎么样演进的。如下图,近期重点优化的内容大家已经可以看到,那可能没看到的是我们最近在做的索引支持,如果MaxCompute深度使用的话,这方面的优化会带来非常大的帮助,在性能,成本,全盘扫描等方面得到极大的优化。包括数据组织结构跟ORC的兼容,因为大家知道不同数据组织结构和ORC在存储的压缩比和性能上是有一定平衡的。所以在这方面我们会挑选最好的数据组织方式,很快可以看到给大家带来的优势,最终的体会就是MaxCompute更便宜了。另外我们在语言层面,NewSQL的优化,以及优化器,语言的覆盖程度上有了全面的优化和升级。从2.0上线差不多有快1年,这个过程非常漫长,直到5月份才把原先2.0上试用的开关关闭,真正的面向全网打开了。

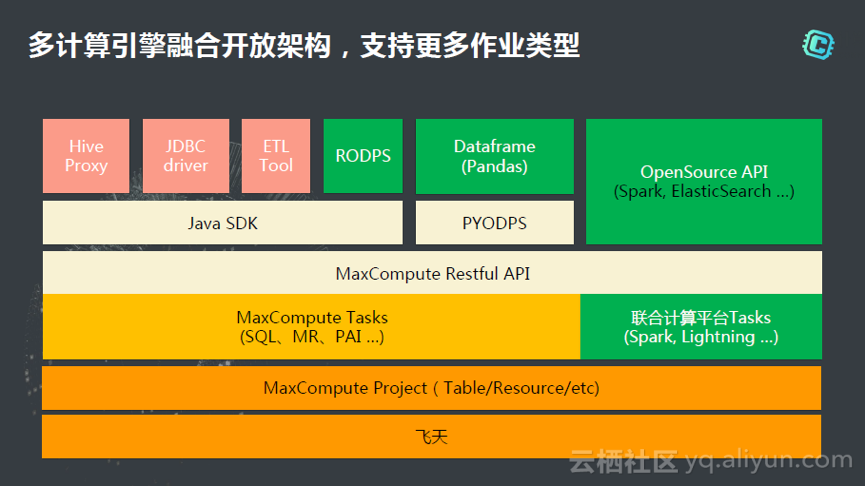
下图是在MaxCompute上支持的作业类型,从去年开始我们开始思考怎么样和生态进行结合。也就是说在数据只有一份的情况下,怎么样支持更多的任务类型,在这个过程中,不用对数据进行搬家,不用多一步的copy。数据在project级别是达到共享的,在这个之上我们集成联合计算平台支持更多的作业类型。在这里可以预先发布的是我们会支持实时交互式分析作业,也就是说表的数据量比较小的情况下,我们可以秒级响应结果,叫做“闪电(Lightning)”。第二个是我们会支持Spark的作业类型,Spark可以直接访问MaxCompute的表,而不用来回导入导出,搬迁。这样我们可以达到联合计算平台的目的:在统一的数据基础上,支持更多作业类型,满足更多的计算场景。
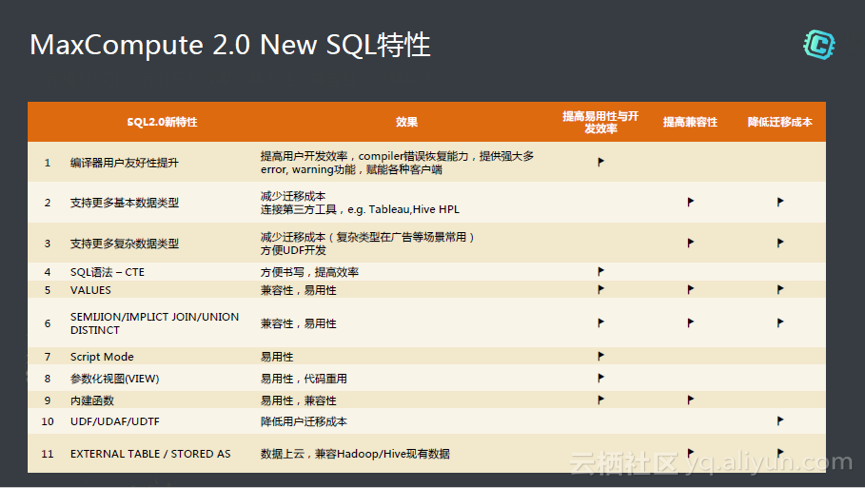
在SQL方面的优化包括编译器的优化,支持复杂数据类型等。整体做的工作围绕提高易用性与开发效率,提高兼容性,和降低迁移成本等三个方面,从开发者的角度做的优化。
SQL得天独厚的是它可以声明,写出来的东西大家都可以看得懂,不用去翻代码就可以知道要解决什么问题,但在这个过程中它失去了一定的灵活性。那么通过Function这种函数的形式,通过Java函数,通过Python函数的形式将两者之间做更好的结合。也就是说SQL加上Function,在保持声明的简化性上以及复杂业务的支持上达到最完美的结合。在Function方面,MaxCompute2.0上也推出了更多的内置函数,通过函数提高复杂业务逻辑的方便程度。

那么怎么样处理非结构化的数据,在阿里云上非结构化的数据都存在OSS上,里面存了文件,图片,视频等等。在阿里云上半结构化的数据存在TableStore上。这是阿里云上两个最重要的数据源。在这边定义一个外表,把OSS作为非结构化的数据源,还有TableStore作为半结构化数据源,直接Select来操作非结构化和半结构化的数据。因为在OSS和TableStore上都是通过API,这边提供新的数据库的方式,进一步降低非结构化数据操作的成本和开发的便捷程度。所以外表非常有效的补充了MaxCompute的计算场景和数据的范围。

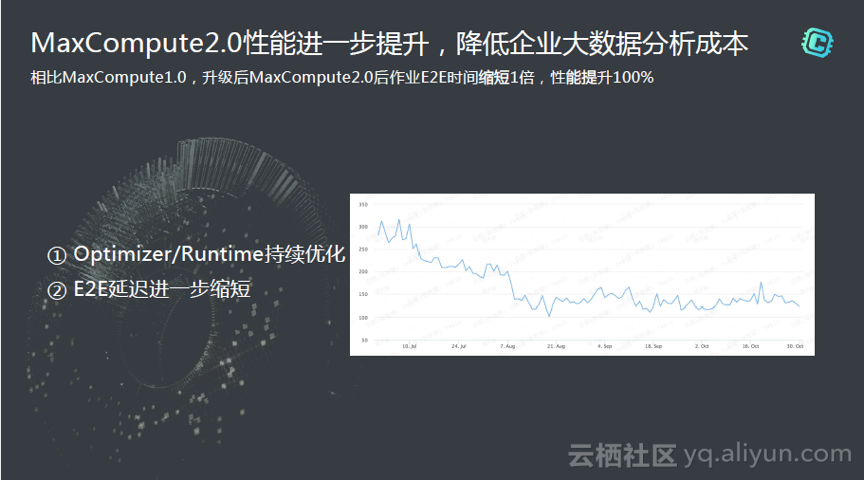
性能一直是阿里极致追求的,可以看到我们每年都在不断的努力,持续的优化性能。MaxCompute2.0的性能提升了一倍,当大家每天晚上12点开始跑作业的时候,我们不希望到第二天9点才跑完。如果我们提升一倍,一层,二层,三层表的计算在早上5,6点跑完的话被业务同学找的机会就小一些了。所以说性能在离线作业中是非常非常关键的。还有调度量加大,跑几万作业,每天晚上堆积,怎么样能减少这个量,所以这一点上性能也是非常重要的。
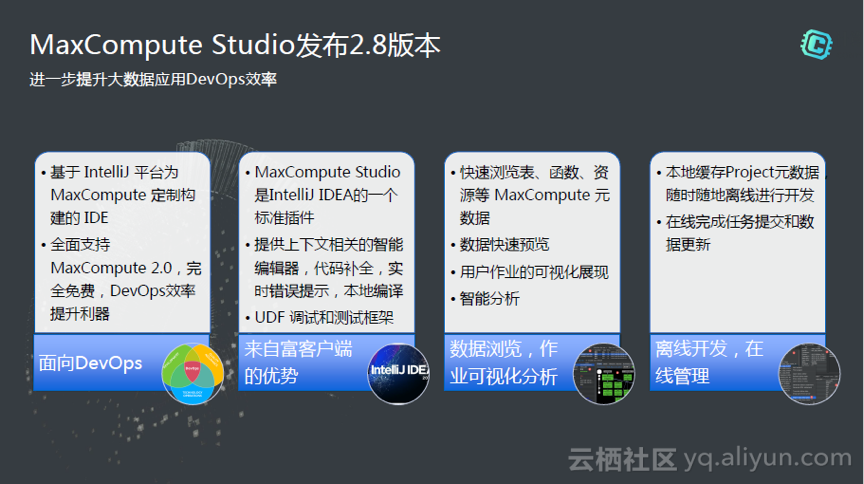
因为阿里在做计算引擎,在工具方面Studio有很多新的特性。并且Studio发布的非常快,它是基于IntelliJ平台,为MaxCompute定制构建的IDE。
还有命令行的发布,很多管理人员会喜欢非常高效的黑屏,操作命令,授权,管理数据。我们命令行也在不断的发布新的版本,大家可以根据不同的角色选用不同的工具。比如开发者可以用Studio,管理者推荐使用客户端的方式做日常管理。

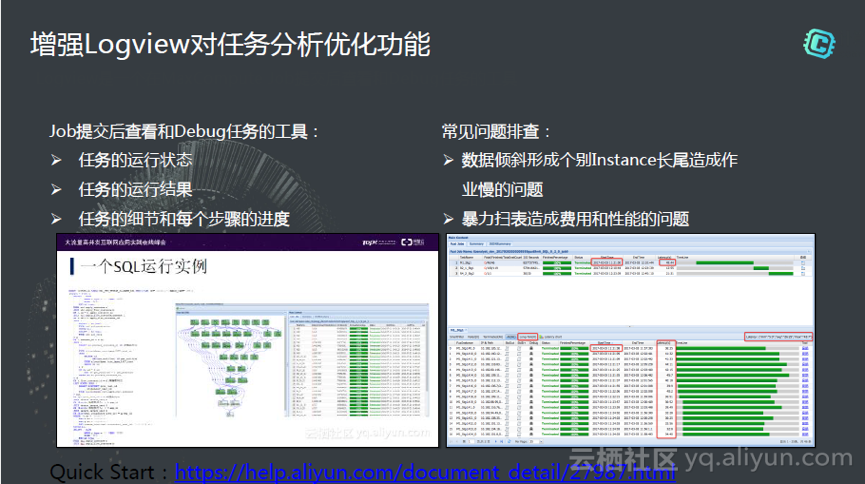
Logview是一个共享的服务,深深被用户打动的是说终于不用从很多的日志里面搜下发的任务相关信息,一个任务发布完之后,我们会推给他一个链接,打开之后需要的所有相关信息,上下文都会完整的打出来,这里面包括常见的全盘扫描,数据清洗等等所有关于性能方面的问题通过DAG图,通过任务可以详细的进一步分析,定位,诊断。经常有情况是下发的任务很大,需要同时几千个核计算,其中只要有一个跑得慢,整个拉慢了作业,我们可以通过Logview进行调优、诊断。
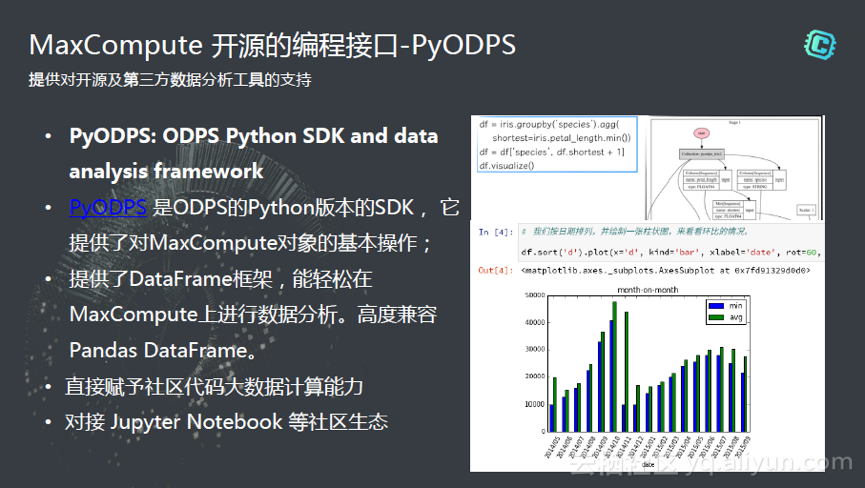
我们推出PyODPS,大家可以用它来以非常简单的开发方式来调度非常复杂的计算。同时PyODPS,也就是Python的SDK可以很方便的跟Pandas DataFrame整合。这样可以得到很高的开发效率。
另外还有R,我们认为在国内R应该有更好的推广,所以我们支持了RODPS。
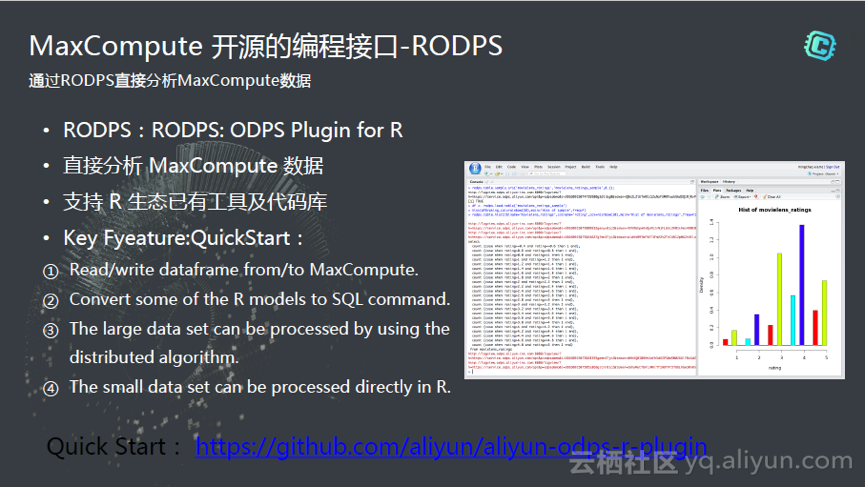
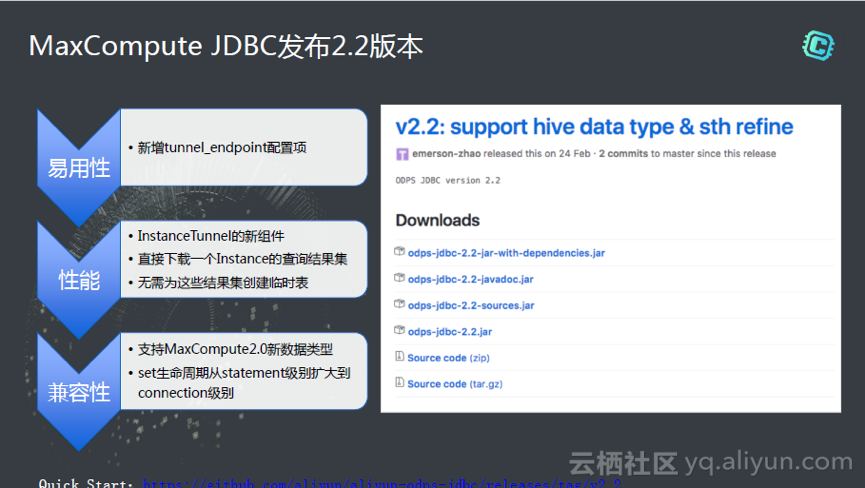
还有JDBC,现在大家用的很少,大家大部分通过SDK访问,那么大家也可以通过JDBC,进一步的和第三方集成。
还有我们ETL工具集成中,开源了很多项目,包括Flume插件,OGG插件,Sqoop,Kettle插件,还有Hive的Data Transfer。我们都是通过这一套机制开源了很多项目,通过下图链接,可以做ETL工具的集成。

在互联网公司内,包括最早加入阿里时,一个很明显的感受是都不愿意记文档,但是跟客户沟通之后发现看不到代码情况下,文档是作为长期沟通的东西。我们作为产品在这上面也做了很多工作,在云栖社区有MaxCompute葵花宝典,我们关注的不仅仅是技术,还有工具,文档,传播等方面也做了很多工作。

四、数据安全
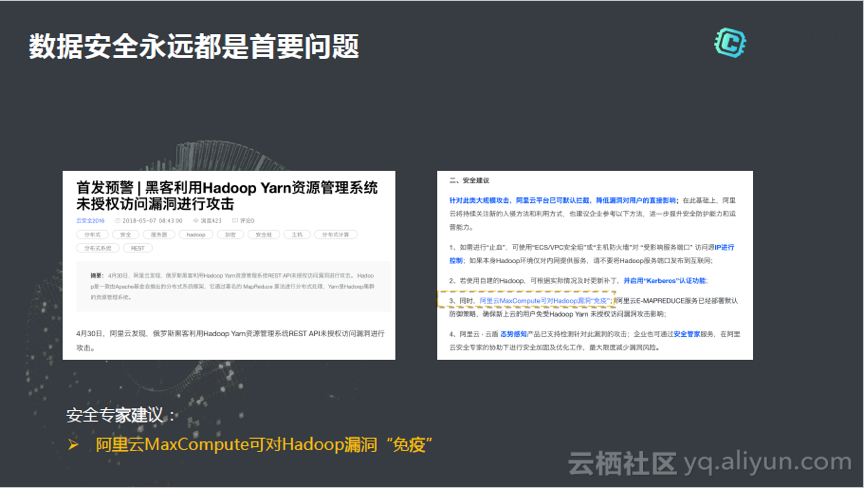
数据安全用于都是首要的问题,没有安全就没有云计算。这个问题在产品经理角度来看永远都是第一的,任何蛛丝马迹的安全问题一定是最优先要解决的问题,数据安全就是身家性命。在4月27日,Hadoop Yarn遇到一个安全漏洞,阿里有一个很强大的安全部叫云盾,也给出了很多安全建议,其中有一条是说阿里云的MaxCompute可对Hadoop漏洞免疫。阿里云的MaxCompute在公有云上运行这么久,我们的数据安全是零安全事故。
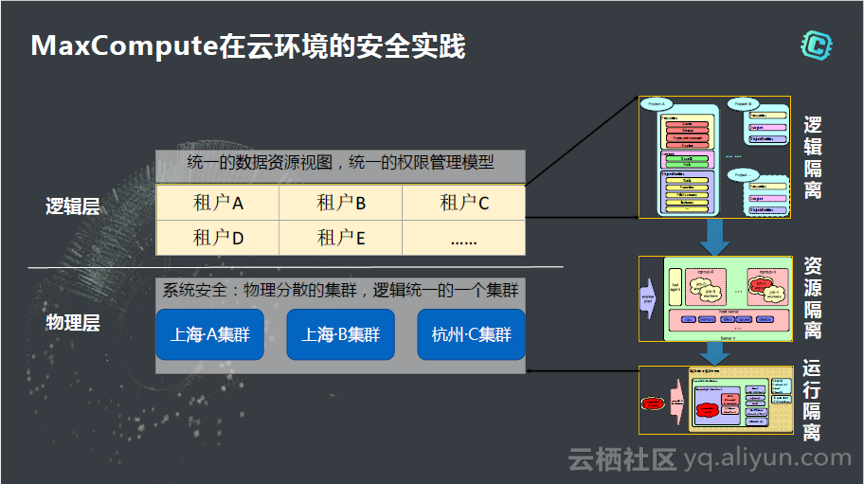
我们是怎么样做安全的,下图是我们的数据中心,每次要开一个Region。下面来看看MaxCompute特别的安全机制,首先在逻辑层,MaxCompute是标准的Severless服务,也就是说它是无服务器的云服务,这个集群里面通过租户隔离。之后做逻辑隔离,里面最大的隔离程度是project,在project里面按照表,按照列做更细粒度的授权控制。所以逻辑层非常细的隔离从而确保模型是足够的,而不是说开放出了文件系统。在数据不能被别人拿到,偷走的情况下,一旦作业运行起来,它要进到内存里面,进到CPU里面,这时候该怎么隔离呢?所以还需要资源的隔离,当每个UDF调起来之后,都会把它放到独立的资源池里面,一个隔离的资源环境里面运行,确保资源方面和运行时候内存的安全。所以整体来说,云的安全不仅有多租户就够了,要从逻辑层面,资源层面,和运行层面全面的进行隔离,确保每个租户在共享之间达到安全可靠。
另外数据仅仅有安全是不够的,安全和共享一定是结伴而来的,所以通过逻辑机制不但做到了安全,同时也做到了安全的数据交换和共享。这是我们想要的,并不是说绝对的安全,什么都不发生,那数据一定是死水一潭。
最近我们和Forrester也有合作,Forrester一直在做云上评测,我们这次MaxCompute,DataWorks,以及推的阿里云的云上数据仓库解决方案,被评为第一象限,然后非常荣幸得到了第二名的排名。第一个是AWS,第二个是阿里巴巴,第三个是Google,第四个是Microsoft,以及后面的很多。这个过程中也在思考他们是怎么认识当前云上数据仓库(CDW,Cloud Data Warehouse)的,分为三类,第一种是标准的多租户的CDW,第二个是独立专享的CDW,还有一个是托管的CDW。这三个差别非常大,第一类,如MaxCompute共享集群,还有BigQuery也是Serverless。专有的是说整个大的里面完全给出一块,所有资源都是被锁定的,不可能被共享,只是逻辑上做了资源的划分。还有托管的,如果把虚机当作物理资源的话,在那个层面就划分出来了。
另外也从不同角度做出全面的判断,包括自助服务,弹性能力,自动升级,数据加载能力,卸载能力,混合云,数据复原等等。

回到最开始的故事,路遥知马力。每个人都有数据帝国的梦想,怎么样去扩展疆土来决定帝国半径的大小,选择什么样的千里马非常重要。我们非常希望MaxCompute成为大数据旅途上的“千里马”。MaxCompute努力的方向仍然很朴素,回到初心,我们希望能更开放,有更好的生态,更快更经济,然后更简单更易用,同时更稳定,能够日行千里夜行八百。从马力到计算力,思考更多,也希望大家能选到心仪的大数据的千里马,让每一位的大数据历程跑的更远,帝国建的更加强大。
如需了解更多关于MaxCompute产品和技术信息,可加入“MaxCompute开发者交流”钉钉群;
群号11782920,或扫描如下二维码加入钉钉群。



