核心观点: 服务的本质是数据的流转与变换
数据的变换依赖于数据的流转,只有流转的数据才能够被变换。基于这个理念,我们提出了Transformer架构。
基本概念定义
Transformer。 我们的每一个服务应用,都是一个数据转换器。数据在这些Transformer之间进行流动和转换。流动的过程就是Pipeline形成的过程(Pipeline的概念在后续会有定义)。典型的例子比如你开发的一个Spark Streaming程序,一个Storm程序,一个Tomcat Web服务,都是一个Transformer。
- Estimator 。它是一类问题的抽象与实现。现实生活中,我们要解决的问题举例有,实时计算问题,离线批量问题,缓存问题,Web服务问题等。对这些问题,我们都有一些可扩张,灵活动态的,具有平台性质的Estimator。比如MR 可以解决大部分离线批量问题,比如Spark则可以解决实时计算,离线批量等多个方面的问题。比如Storm则可以解决实时计算问题,比如Tomcat。并不是所有的Estimator 都能够实现平台特质,隔离底层的。譬如 基于Spark的Transformer 可以实现以资源为需求的动态部署。但基于Tomcat的Transormer则不行,因为Tomcat本身并没有做到分布式的,以资源为粒度的提供给上层Transormer使用的特质。
- Parameter 。 每个Transformer都有自己的参数,每个Estimator有自己的参数。Parameter就是所有参数的集合。如果进行扩展,他可以包括Transformer/Estimator/Pipeline/Core/OS 等各个层次的参数。
- Pipeline。 数据在Transfomer之间流动的形成了Pipeline。每一个Transformer 以自己作为Root节点,都会向下延伸出一个树状结构。
- DataFrame。数据框。数据需要被某种形态进行表示。可以是byte数组,可以一个son字符串。这里我们用DataFrame 对 数据表示( Data Represention )。 它是各个Transformer之间交换数据的表示和规范。
Transformer架构概览
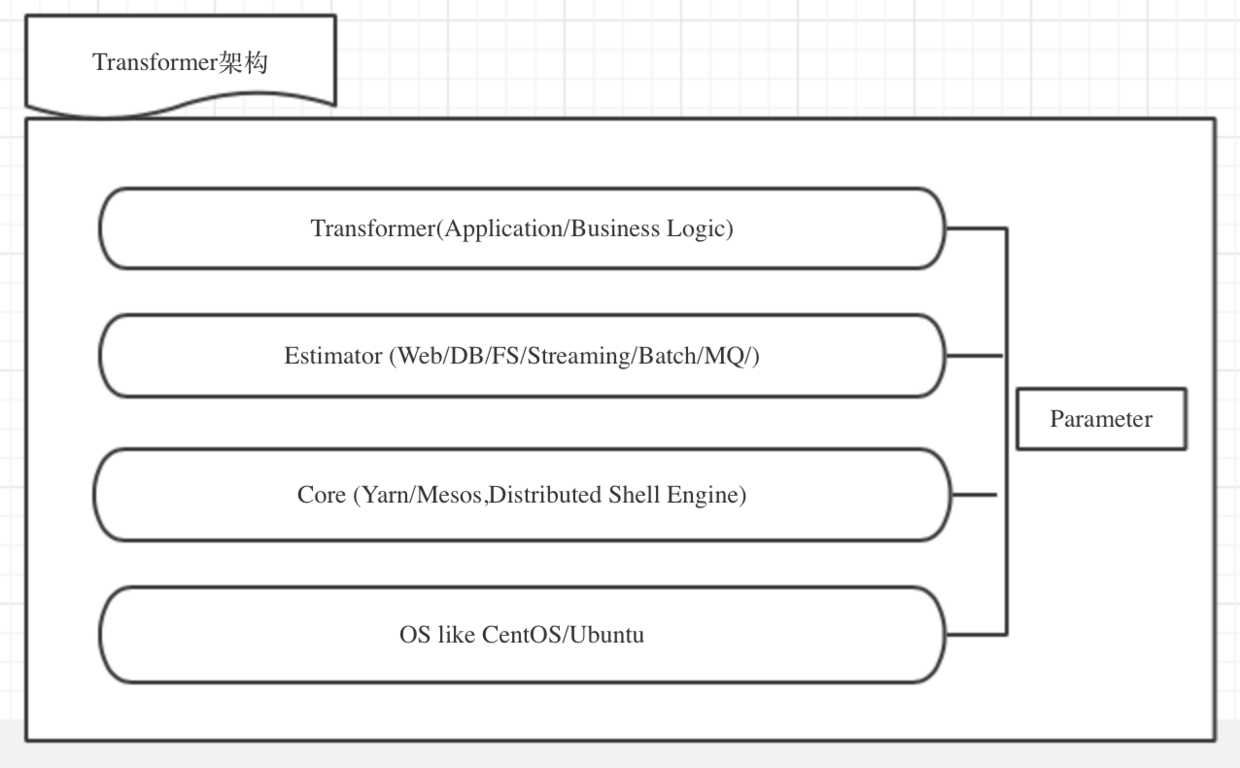
Transformer架构概览
什么是资源需求为主导的Estimator
在前文中,我们在对Estimator进行第一的时候,我们提到了平台特质,以资源为导向等概念。那么这些指的是什么呢?
如果上层的Transformer可以按资源进行申请,并且被提交到Estimator上运行,则我们认为该Estimator 是具有平台特质,以资源为导向的。典型的比如Spark。
但是譬如Tomcat,他本身虽然可以运行Web类的Transformer,但是Transformer无法向Tomcat提出自己的资源诉求,比如CPU/内存等,同时Tomcat本身也没办法做到很透明的水平扩展(在Transformer不知情的情况下)。所以我们说Tomcat 是不具备平台特质,并且不是以资源为导向的Estimator。
但是,当我们基于Core层开发了一套容器调度系统(Estimator),则这个时候Tomcat则只是退化成了Transfomer的一个环境,不具备Estimator的概念。
在Transformer架构中,我们努力追求Estimator 都是具备平台特质,并且以资源为导向的服务平台。
Transformer/Estimator/Pipeline的关系
下面以搜索为例子,简单画了个三者之间的关系。特定的Transformer依赖于特定的Estimator运行,不同的Transformer 构建了Pipeline实现了数据的流动,数据流动到具体的Transformer后发生数据的transform行为。
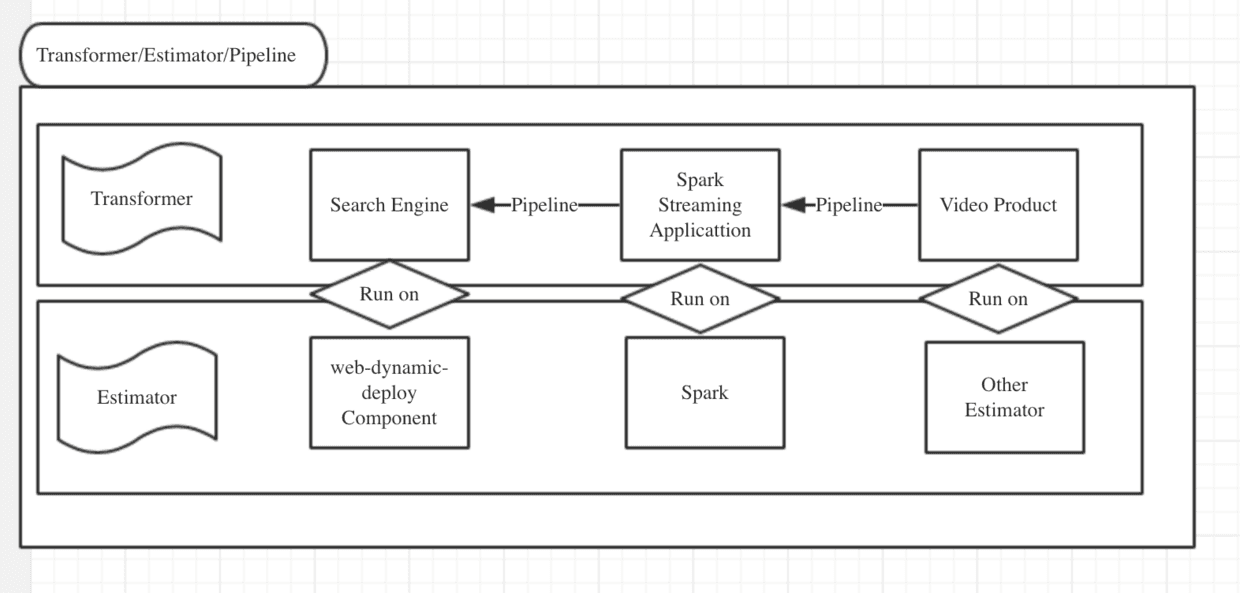
Transformer/Estimator/Pipeline的关系
Transformer 架构可以对互联网也进行建模
Transformer 和Pipeline构建了一个复杂的网络拓扑。在Pipeline流动的的DataFrame则实现了信息的流动。如果我们跳出公司的视野,你会发现整个公司的网状服务体系只是全世界网络体系的一小部分。整个互联网是一张复杂的大网。而整个互联网其实也是可以通过上面五个概念进行涵盖的。
利用Transformer概念去理解我们已经存在的概念
譬如,我们部署服务到底是一件什么样的事情?
你可能觉得这个问题会比较可笑。然而,如果之前我们提出的概念是正确或者合理的,让我们离真理更近了一步的话,那么它应该能够清晰的解释,我们部署或者下线一个服务,或者一个服务故障,到底是什么?
所谓部署服务,不过是新建一个Transformer,并且该Transformer和已经存在的的Transformer通过Pipeline建立了联系,在网络拓扑中形成一个新的节点。这个新的Transformer无论业务有多复杂,不过是实现了一个对数据transform的逻辑而已。
Transformer 的优势
前文我们提到了具有平台特质,以资源为导向的Estimator,可以给我们带来如下的好处:
- 这些Estimator 底层共享 Yarn/Mesos这个大资源池,可以提高资源利用率
- Estimator如果已经实现了Adaptive Resource Allocation,则根据Transformer的运行情况,可以动态添加或者缩进对应的资源
- Transformer 部署变得异常简单,申明资源即可。开发人员无需关心起如何运行。一切由Estimator来解决。
- 有了Estimator的规范和限制,Transformer开发变得成为套路,真正只要关注如何transform,和哪些Transformer建立Pipline
- 平台组和应用组只能划分清晰。平台组总结数据处理模式,提供抽象的Estimator供应用组进行开发和运行
除了这些,对我们进行架构设计也具有极大的知道意义。让我们换了一种思考模式去思考面对新的需求,如何设计的问题。
我们不希望每次遇到一个新的业务问题,都需要根据自己的聪明才智,通过经验,得到一个解决方案。任何事情都是有迹可循的。正如吴文俊提出的机器证明,可以通过流程化的方式让计算机来证明几何问题。当面临一个新的业务问题的时候,我们应该有标准的流程可以走。
当设计一个平台的时候,我们只要关注Estimator就好,我们必须已经有大量的以及随时具备上线新的Estimator的能力。 之后面对实际的各种业务需求,应该由基于这些Estimator的Transformer去应对,构建Transformer 按如下方式思考去获得答案:
针对业务逻辑,定义好如何对数据进行Transform
哪个Estimator 最适合这个Transformer?
从已经存在的Transformer中找出我们需要建立Pipeline的Transformer
一个复杂的业务必定是由多个Transfomer进行构建的,每个Transfomer的构建流程都可以遵循这个方式。
用Transformer架构思考样例
假设我现在有个搜索服务,我要新接入一个产品,再次假设新产品的数据已经远远不断的放到了Kafka里。
这个时候,我们需要新建立一个Transformer。
哪个Estimator 最适合这个Transformer?
数据进入索引,必然有个吞吐量和实时性的权衡。如果你追求实时性,譬如要达到毫秒级,这个时候实时计算里的Estimator Storm是个更好的选择。而如果是秒级的,可能Spark Streaming是个更好的选择。假设我们选择了Spark Streaming,则说明我们的Transformer是个Spark Streaming程序。
从已经存在的Transformer中找出我们需要建立Pipeline的Transformer
这里我们要连接的Transformer 非常清晰,就是搜索和Kafka。 他们之间需要通过我们新的Transformer将数据进行流转。为了解决他们的数据表示的不一致性(DataFrame的不一致),所以我们需要新的Transformer 能够做两次转换,将Kafka的数据转换为搜索能够认识的数据表示形态。
针对业务逻辑,定义好如何对数据进行Transform
你需要调研Kafka里的DataFrame以及搜索需要的DataFrame,实现transform逻辑。
程序员根据这三点进行是靠,按照Estmator的规范(这里是Spark Streaming 的编程规范),写了几十行(或者百余杭代码),然后提出资源要求,譬如:
- 10颗核
- 10G内存
- 无磁盘要求
这个时候他package好后,通过一个简单的submit 命令(或者如果你有web提交任务的界面),带上资源要求,将服务进行提交。
过了几秒,你就会发现数据已经神奇的从Kafka流入到搜索,通过搜索的API我们已经能够检索的数据了。
整个过程从设计,从实现,我们都是严格按照规范来做的。我们无需有所谓的服务器。我们只要知道根据Transformer架构去思考,然后提出自己需要的资源,就可以实现一个新的业务逻辑。可能一到两小时就搞定了整件事情。
个人感觉
Transformer 架构,不仅仅能建模我们的数据平台,也能建模我们传统的Web服务,还能对机器学习流程进行建模。





