Coprocessors
之前我们的filter都是在客户端定义,然后传到服务端去执行的,这个Coprocessors是在服务端定义,在客户端调用,然后在服务端执行,他有点儿想我们熟悉的存储过程,传一些参数进去,然后进行我们事先定义好的操作,我们常常用它来做一些比如二次索引啊,统计函数什么的,它也和自定义filter一样,需要事先定好,然后在hbase-env.sh中的HBASE_CLASSPATH中指明,就像我的上一篇中的写的那样。
Coprocessors分两种,observer和endpoint。
(1)observer就像触发器一样,当某个事件发生的时候,它就出发。
已经有一些内置的接口让我们去实现,RegionObserver、MasterObserver、WALObserver,看名字就大概知道他们是干嘛的。
(2)endpoint可以认为是自定义函数,可以把这个理解为关系数据库的存储过程。
所有的Coprocessor都是实现自Coprocessor 接口,它分SYSTEM和USER,前者的优先级比后者的优先级高,先执行。
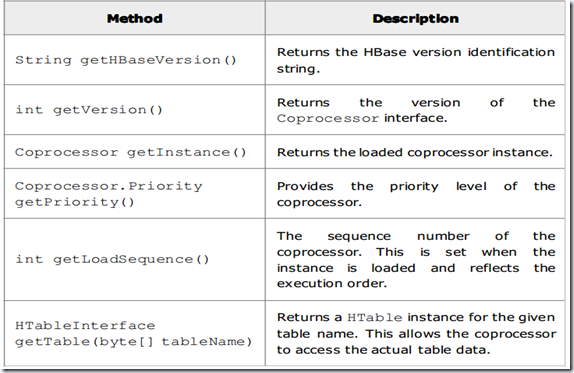
它有两个方法,start和stop方法,两个方法都有一个相同的上下文对象CoprocessorEnvironment。
void start(CoprocessorEnvironment env) throws IOException;
void stop(CoprocessorEnvironment env) throws IOException;
这是CoprocessorEnvironment的方法。
Working with Tables
对表进行操作的时候,必须先调用getTable方法活得HTable,不可以自己定义一个HTable,目前貌似没有禁止,但是将来会禁止。
并且在对表操作的时候,不能对行加锁。
Coprocessor Loading
Coprocessor加载需要在配置文件里面全局加载,比如在hbase-site.xml中设置。
<property>
<name>hbase.coprocessor.region.classes</name>
<value>coprocessor.RegionObserverExample,coprocessor.AnotherCoprocessor</value>
</property>
<property>
<name>hbase.coprocessor.master.classes</name>
<value>coprocessor.MasterObserverExample</value>
</property>
<property>
<name>hbase.coprocessor.wal.classes</name>
<value>coprocessor.WALObserverExample,bar.foo.MyWALObserver</value>
</property>
我们自定义的时间可以注册到三个配置项上,分别是hbase.coprocessor.region.classes,hbase.coprocessor.master.classes,
hbase.coprocessor.wal.classes上,他们分别负责region,master,wal,注册到region的要特别注意小心,因为它是针对所有表的。
<property>
<name>hbase.coprocessor.region.classes</name>
<value>coprocessor.RegionObserverExample</value>
</property>
注册到这三个触发器上,可以监控到几乎所有我们的操作上面,非常恐怖。。可以说是想要什么就有什么,详细的代码大家自己去摸索。
EndPoint的可以用来定义聚合函数,我们可以调用CoprocessorProtocol中的方法来实现我们的需求。
调用coprocessorProxy() 传一个单独的row key,这是在单独一个region上操作的。
要在所有region上面操作,我们要调用coprocessorExec()方法 传一个开始row key 和结束row key。
Demo
说了那么多废话,我都不好意思再说了,来个例子吧,统计行数的。
public interface RowCountProtocol extends CoprocessorProtocol {
long getRowCount() throws IOException;
long getRowCount(Filter filter) throws IOException;
long getKeyValueCount() throws IOException;
}public class RowCountEndpoint extends BaseEndpointCoprocessor implements
RowCountProtocol {
private long getCount(Filter filter, boolean countKeyValues)
throws IOException {
Scan scan = new Scan();
scan.setMaxVersions(1);
if (filter != null) {
scan.setFilter(filter);
}
RegionCoprocessorEnvironment environment = (RegionCoprocessorEnvironment) getEnvironment();
// use an internal scanner to perform scanning.
InternalScanner scanner = environment.getRegion().getScanner(scan);
int result = 0;
try {
List<KeyValue> curVals = new ArrayList<KeyValue>();
boolean done = false;
do {
curVals.clear();
done = scanner.next(curVals);
result += countKeyValues ? curVals.size() : 1;
} while (done);
} finally {
scanner.close();
}
return result;
}
@Override
public long getRowCount() throws IOException {
return getRowCount(new FirstKeyOnlyFilter());
}
@Override
public long getRowCount(Filter filter) throws IOException {
return getCount(filter, false);
}
@Override
public long getKeyValueCount() throws IOException {
return getCount(null, true);
}
}<property>
<name>hbase.coprocessor.region.classes</name>
<value>coprocessor.RowCountEndpoint</value>
</property>JAVA 客户端调用
在服务端定义之后,我们怎么在客户端用java代码调用呢,看下面的例子你就明白啦!
public class EndPointExample {
public static void main(String[] args) throws IOException {
Configuration conf = HBaseConfiguration.create();
HTable table = new HTable(conf, "testtable");
try {
Map<byte[], Long> results = table.coprocessorExec(
RowCountProtocol.class, null, null,
new Batch.Call<RowCountProtocol, Long>() {
@Override
public Long call(RowCountProtocol counter)
throws IOException {
return counter.getRowCount();
}
});
long total = 0;
for (Map.Entry<byte[], Long> entry : results.entrySet()) {
total += entry.getValue().longValue();
System.out.println("Region: " + Bytes.toString(entry.getKey())
+ ", Count: " + entry.getValue());
}
System.out.println("Total Count: " + total);
} catch (Throwable throwable) {
throwable.printStackTrace();
}
}
}
通过table的coprocessorExec方法调用,然后调用RowCountProtocol接口的getRowCount()方法。
然后遍历每个Region返回的结果,合起来就是最终的结果,打印结果如下。
Region:
testtable,,1303417572005.51f9e2251c29ccb2...cbcb0c66858f.,
Count: 2
Region:
testtable,row3,1303417572005.7f3df4dcba3f...dbc99fce5d87.,
Count: 3
Total Count: 5Batch.Call call =Batch.forMethod(RowCountProtocol.class,"getKeyValueCount");
Map<byte[], Long> results = table.coprocessorExec(RowCountProtocol.class, null, null, call);采用Batch.Call方法调用同时调用多个方法
Map<byte[], Pair<Long, Long>> results =table.coprocessorExec(
RowCountProtocol.class,
null, null,
new Batch.Call<RowCountProtocol, Pair<Long, Long>>()
{
public Pair<Long, Long> call(RowCountProtocol counter) throws IOException {
return new Pair(counter.getRowCount(),counter.getKeyValueCount());
}
});
long totalRows = 0;
long totalKeyValues = 0;
for (Map.Entry<byte[], Pair<Long, Long>> entry :results.entrySet()) {
totalRows +=
entry.getValue().getFirst().longValue();
totalKeyValues +=entry.getValue().getSecond().longValue();
System.out.println("Region: " +Bytes.toString(entry.getKey()) +", Count: " + entry.getValue());
}
System.out.println("Total Row Count: " + totalRows);
System.out.println("Total KeyValue Count: " +totalKeyValues);调用coprocessorProxy()在单个region上执行
RowCountProtocol protocol = table.coprocessorProxy(RowCountProtocol.class, Bytes.toBytes("row4"));
long rowsInRegion = protocol.getRowCount();
System.out.println("Region Row Count: " +rowsInRegion);