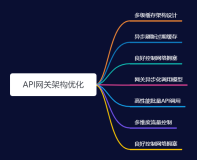
云上架构概述
云上搭建架构不单单需要考虑到性能和可用性,还有安全性、可管理性、弹性等层面都需要注意,实际工作中每一个环节都需要顾及到。
传统架构与云上架构设计方法对比,传统的架构设计周期会比较长,一般的企业架构都会考虑今后3到5年的规划,解决的主要是有无的问题,是从0到1的架构搭建。云上的架构设计周期相对来说比较短,需求明确且主要是解决或优化已有的问题。
云上架构的高性能
什么是性能性能是很难衡量的,狭义上的性能指的是运行速度的快慢,广义的性能则涉及更多的内容,如功耗、利用率、性能价格比、速度等。不同视角下关注性能的侧重点不同,用户视角下关注的是从请求发送到获得响应的整个时间间隔,对用户来说时间越长性能越差。从架构和开发者视角出发更多是关注响应延时、系统吞吐量以及并发处理能力,而更重要的是明确了解用户反映问题的根源。
高性能架构设计的基本步骤
搭建高性能架构有4个基本步骤,首先要明确性能的目标,接着分析系统中影响目标实现的所有问题,找到问题后再着手解决这些问题,最后通过性能评估的手段来测试当前性能指标。如果评估结果与性能目标之前存在差异,就说明影响性能的问题还没有被全部找到,这时需要重新开始进行之前的步骤。
整个过程其实是一个循环,即使某一次性能评估达标,但随着时间的推移业务的发展还是会出现新的性能需要。
进一步分析
性能目标指的是制定的符合高性能的指标,比如页面响应时间小于1秒,并发用户可以达到1万,高峰期每秒处理10000万用户请求等。
然后要根据性能目标分析当前业务系统中不同层次有哪些影响性能指标的问题,比如网络层方面的带宽、延迟,计算层方面的Cpu处理能力、是否采用集群,以及一些其他方面的影响因素。所以说系统性能高低由整体的处理能力决定,不由单一因素决定。
分析出问题后就开始解决问题,这时可以从两个方面着手。一方面是最简便也是大多数人首先会想到的,即提升系统硬件配置,如果硬件资源的升级能够解决问题,那么就直接采用这种方式,它最大的好处在于不用对现有的代码逻辑做任何的修改。但是大部分的情况下往往无法简单的通过硬件升级解决所有问题,还需要从架构的层次上入手,降低服务器压力,采用可扩展架构提高性能。
传统的测试可以使用LoadRunner之类的工具,云上则可以使用阿里云性能测试服务PTS。PTS与传统的性能测试最大的不同在于LoadRunner需要自己搭建,同时搭建好的测试系统会受限于本身的服务上限,服务器的数量决定了所能模拟的测试压力。PTS则可以快速的模拟大量并发请求,因为是云上所以PTS后端能够通过集群的方式模拟用户需要的并发量。
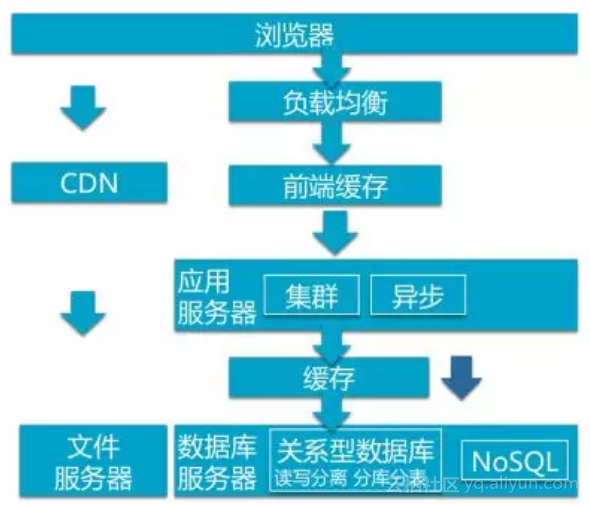
上图是我们提出的相对较好的架构方案,前端由负载均衡服务响应用户请求,在把请求转发给后端具体的服务器之前会有一个前端缓存,用来提升响应时间以及减轻后端压力。后端服务器通过集群方式响应用户请求,同时应用之间通过异步进行交互。访问数据库之前先通过缓存响应请求,在不能命中的时候再去访问数据库。
使用缓存时有个问题需要特别注意,即缓存与数据库的数据不一致。针对这一问题解决方式是不同的,要根据不同的需求来选择。比如有一种方式是在写数据库的数据同时更新缓存中的数据或者让缓存失效,这样用户在读取的时候,要么获取的是最新数据,要么得从数据库中重新读取数据。
某客户在阿里云上的高性能架构
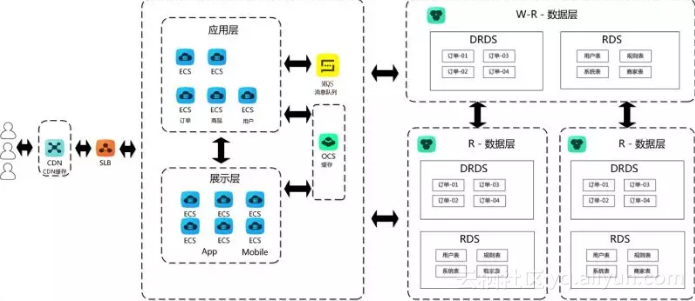
上图是我们某个客户的云上架构。前端用户请求通过CDN服务响应,CDN主要用来做服务加速,对于可以满足的响应直接使用CDN解决,无法满足的请求转发给后端SLB。
从图中可以看到不同的应用使用的服务器数量不同,这里所有的服务都被部署到ECS上,ECS又挂载在SLB后面,另外其中还有OCS数据缓存,用户请求的数据如果无法从缓存中获取到,就从数据库中读取。
数据库的设计同样也非常复杂,首先它实现了一套读写分离,其次有一个DRDS分布式关系型数据库,能够挂载多个RDS实例,所有的请求都会发送给DRDS,而DRDS则相当于中间的路由代理,它会根据请求从不同的RDS中获取数据。
使用DRDS有几点需要注意,第一DRDS必须要和RDS结合使用,DRDS本身不存储数据,数据的存储都是在RDS上;第二DRDS后的RDS实例必须是Mysql数据库;第三DRDS有两种使用方式,一种是表的拆分一种是表的不拆分,如果不拆分DRDS会将表存在某一个RDS实例。
云上架构的高可用
高可用的定义
从字面意思上来看高可用其实就是为了减少停工时间,保持服务高度可用性。系统做高可用首先要具备自动侦测、自动切换、和自动恢复的能力。
自动侦测:通过冗余侦测发现运行的情况,将所汇集的讯息记录下来,以供维护参考。
自动切换:确认对方故障,则正常主机代替故障主机工作。
自动恢复:故障主机修复后,自动切换回修复完成的主机上。
高可用设计的前提
进行高可用设计时一般建议事先对自身架构做层次化和模块化的改造,按照应用层、基础设施层进行高可用设计,再按照功能划分模块,模块之间松耦合,且要求稳定可靠易于扩展,结构简单易于维护。
高可用设计方式
高可用设计包含三种方式,分别是主从方式,主机工作,备机处于监控准备;双机互备,两台主机同时运行各自服务工作且相互监测;集群工作,多台主机一起工作,各自运行一个或几个服务。
高可用架构设计原则
假定失效设计:假定任何环节都会出问题,然后倒推设计;
多可用区设计:尽最大可能避免架构中的单点故障;
自动扩展设计:不进行设计调整,就能满足业务量增长;
自我修复设计:内建容错及检查能力,应用能够在部分组件失效时自我修复继续工作;
松耦合设计:耦合度越小,扩展性越好,容错能力越强
多可用区设计
在SLB实例下绑定不同可用区的ECS,从而避免因为单个可用区的故障而导致对外服务的不可用。多可用区的云数据库RDS可以实现同城的数据灾备,OSS存储的数据默认会保存在多个不同可用区中。
健康检查自我修复
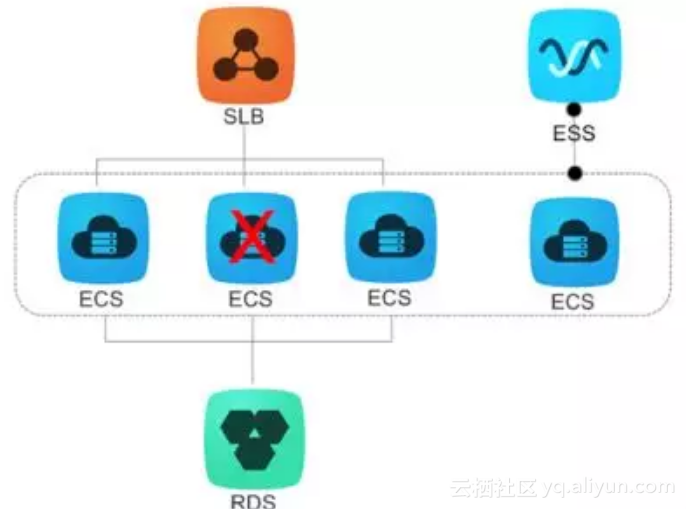
如果某台ECS实例不健康,导致健康中实例数低于最小值,弹性伸缩就会自动创建健康的ECS实例代替不健康的实例。
松耦合设计
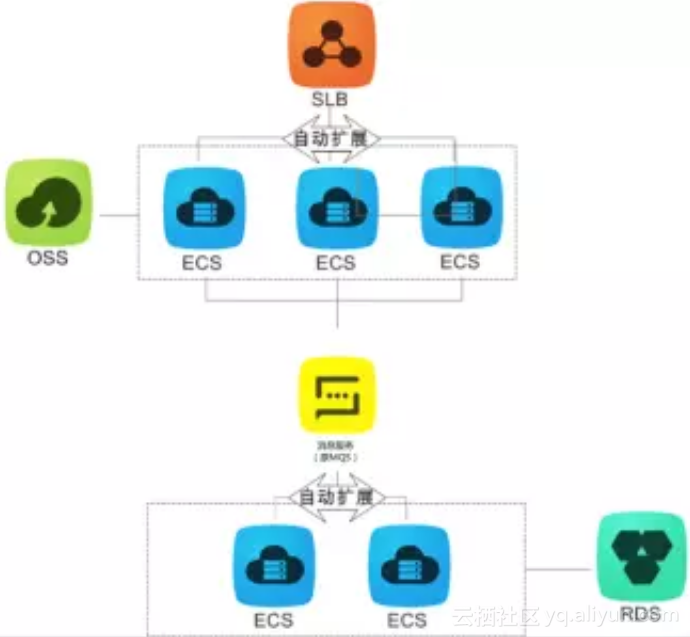
通过消息解耦将原应用拆分成独立的模块,模块间的影响小,就不会因为部分失效导致整体不可用。
原文发布时间为:2018-06-12
本文作者:翟永东