

摘要:阿里云HBase2.0也就是阿里云即将要上线的ApsaraDB for HBase2.0。它不仅兼容开源HBase2.0,也承载着阿里多年大规模HBase使用的技术积淀,还有广大公有云用户喜欢的商业化功能。在大数据量场景中已经具有如此优势的云HBase2.0。HBase与云究竟碰撞出了什么样的火花?云能给HBase带来什么样的能力?本文中,阿里云高级技术专家封神(曹龙)就为大家揭晓了答案。
本文内容整理自演讲视频以及PPT。
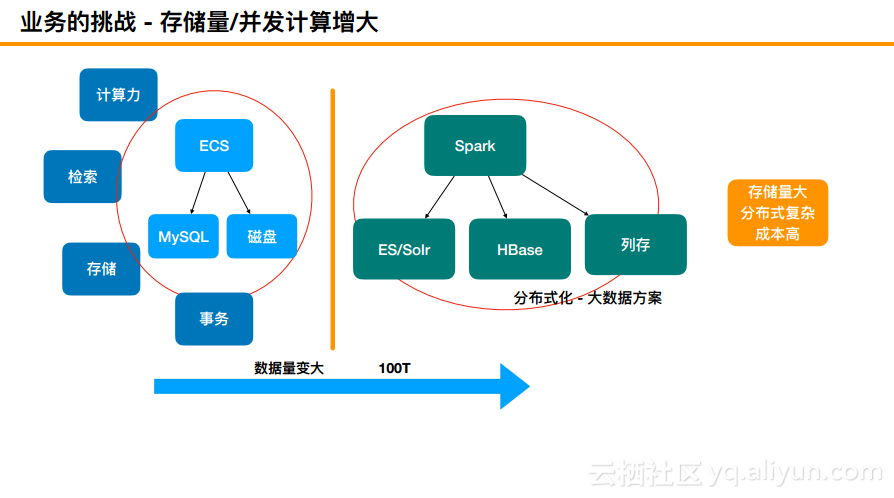
存储量/并发计算增大
随着关系型数据库存储和业务的挑战,数据量慢慢变大。其实,在以前包括阿里在内的很多企业使用的往往是使用ECS下面挂载MySQL数据库或者磁盘这样的方式,这样的架构能够具备四种能力,即计算力、检索、存储以及事务。而当数据量变大之后,阿里就换成了另外一套架构,主要使用Spark+下层的ES/Solr和HBase以及列存相应的组件。这样的架构则面对着数据量大、分布式复杂以及成本高等问题。
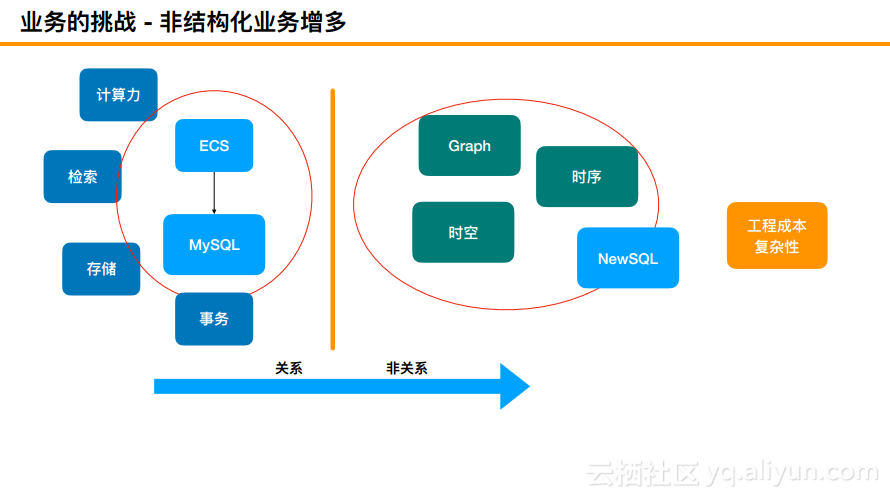
非结构化业务增多
目前来说,非结构化业务也在逐渐地增多,包括时序和时空数据以及最新的NewSQL等,这里的NewSQL虽然属于比较时髦的词,但是实际上是在分布式上加了一些SQL的能力。这里对于工程的挑战就是比较复杂。
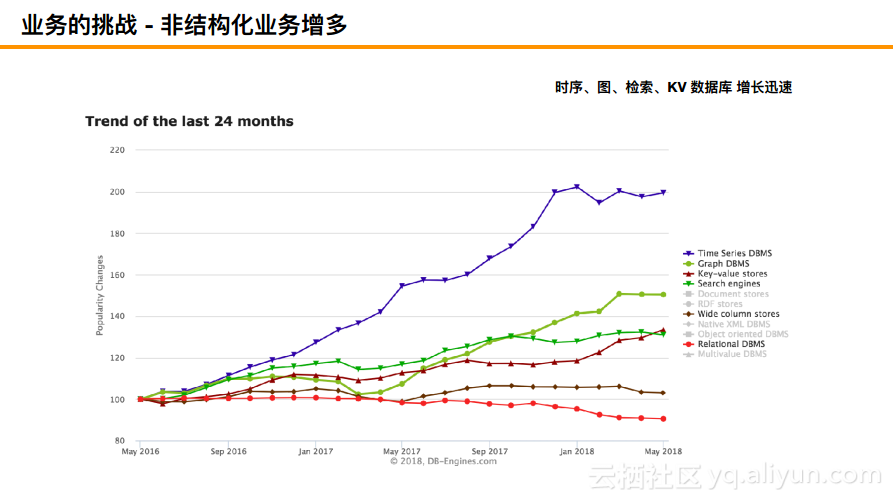
如下图所示的是DB-Engines Ranking的市场关注度的大致趋势图。可以看到在2016年到现在已经过去的两年时间中不同类型数据存储大致的情况,可以看到关系型数据库关注度呈现下降的趋势,两年的时间内关注度就下降了将近一半;而关注度增长最快的是时序数据,在最近一年其增长了将近两倍,而图以及KV等数据存储也在增长。可以发现,在关注度方面,非关系型数据越来越多,这也是因为我们的业务变得更加多元化,特别是物联网的加快发展。
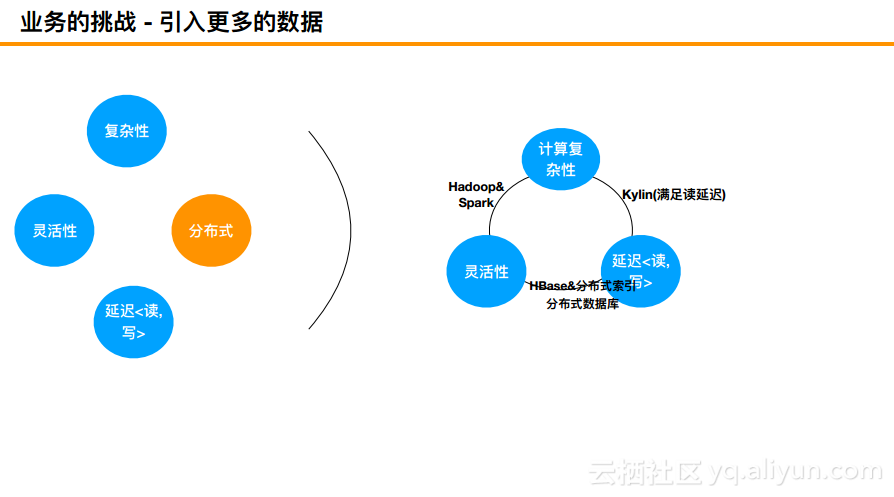
引入更多的数据
其实可以将数据世界大致分为四个象限:复杂性、灵活性、读写延迟以及分布式。分布式肯定是少不了的,缺少了分布式什么问题都解决不了,所以就需要在另外的复杂性、灵活性和读写延迟中寻找平衡。大致发现Hadoop、Spark解决的是灵活性和复杂性的问题;一边则是满足读延迟, Kylin主要满足读延迟的,提前需要Build一些Cube;另外在延迟及灵活性上一般是使用HBase加上solr等搭配。包括Hadoop以及Spark也都可以和HBase进行组合实现一些业务,kylin也是构建在HBase之上的,并且很多企业也都是这样做的。
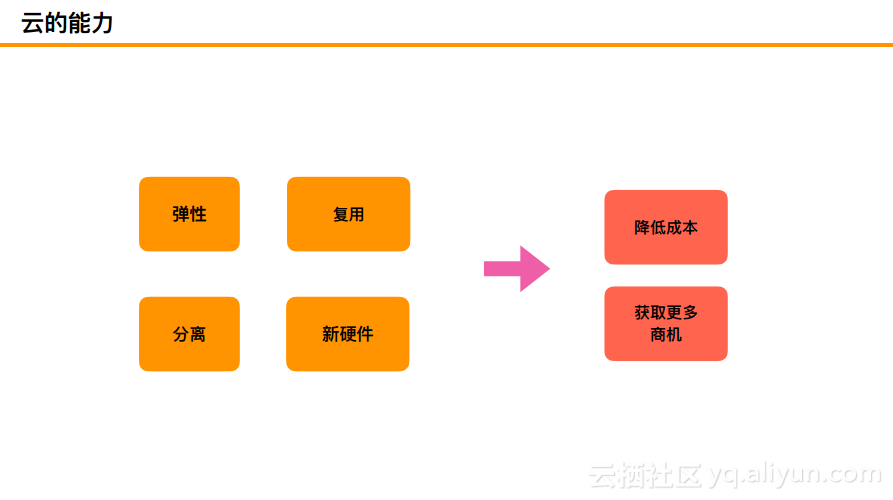
云的能力
因为本文的主题是云能够为HBase带来什么,其实云所能带来很多东西。比如云带来的弹性、复用、分离以及新硬件等特性,对于目前层出不穷的新硬件而言,像RDMA、FPGA、GPU等新硬件,很多小公司不会自己去购买这些,但是在云上就会提供这些硬件的能力,并且不同公司可以去复用这些硬件。云所带来的价值更多地就是为了降低成本,以及快速构建系统获取更多的商机。 这些就是云的能力。
总结-四大因素
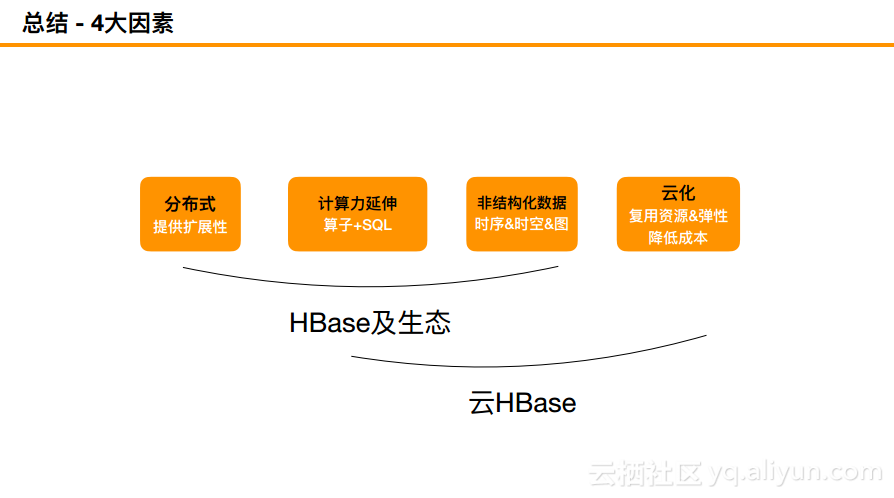
云的能力可以大致总结为四大因素,即分布式、计算力延伸、非结构化数据以及云化。HBase生态就能够很好地解决前三点问题,而云HBase就融合最后一点的云化能力。
二、云HBase架构的思考
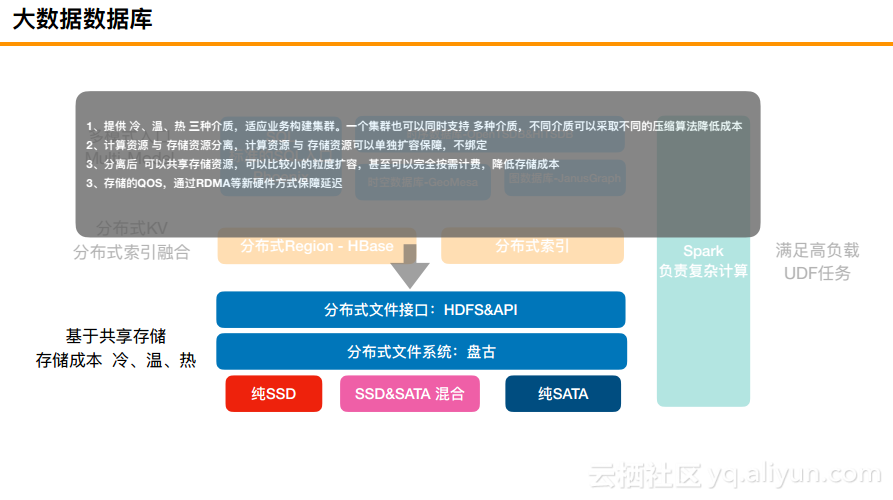
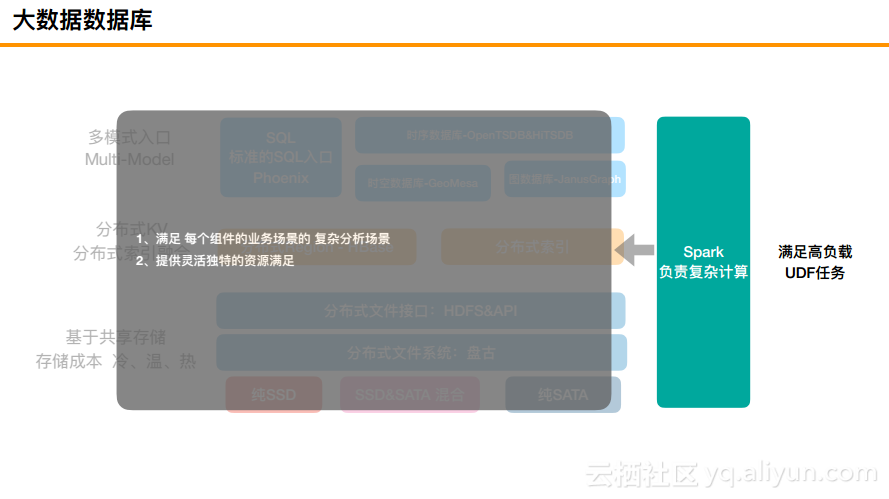
大数据数据库
首先,所有的底层存储将会提供冷、温、热三种介质,一种是纯粹的SSD,一种是SSD和SATA混合,这里用到了2块SSD和10块SATA,也就是SSD作为一个写的缓存,而第三种是纯粹的SATA,且做了EC。在这之上是阿里的分布式文件系统盘古以及文件接口。每个集群也可以同时支持多种介质,不同介质可以采取不同的压缩算法降低成本。此外,计算资源和存储资源也是完全分离的,分离之后可以进行单独的扩容,完全不用担心到底是存储多还是计算多.
HBase天生就提供了分布式KV的核心能力,但是实际上还缺少一些分布式检索的能力,所以需要融合分布式索引。在这一层需要构建分布式KV及检索的能力、降低大内存计算的影响以及KV及索引互相之间内嵌数据同步,满足数据一致性的要求。
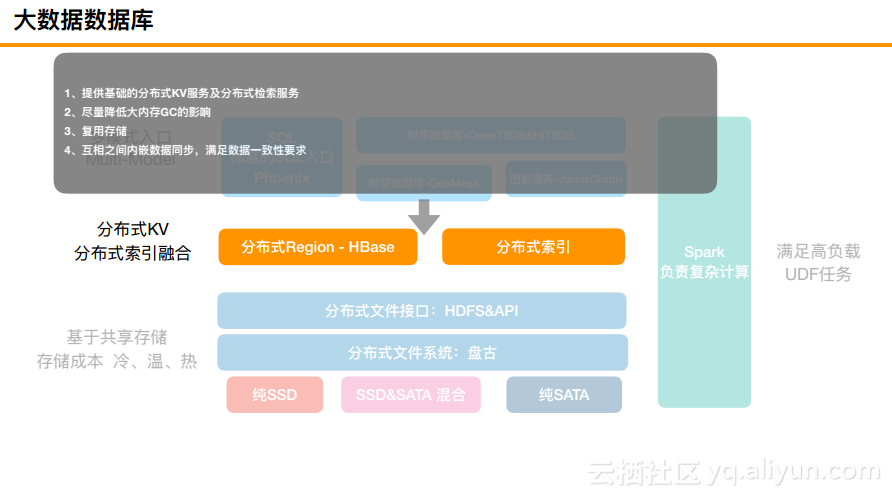
第三层就是多模式的入口,这一层提供了NewSQL入口,可以满足百TB的TP需求,并且提供了一定的聚合能力。包括对于时序数据库而言,之前也看到了DB-Engines Ranking排名来看,时序数据库发展是最快的,时序两倍、图一倍增速。这里的核心能力就是打造一个Proxy层,提供基础非结构化的Graph、时序和时空等能力。
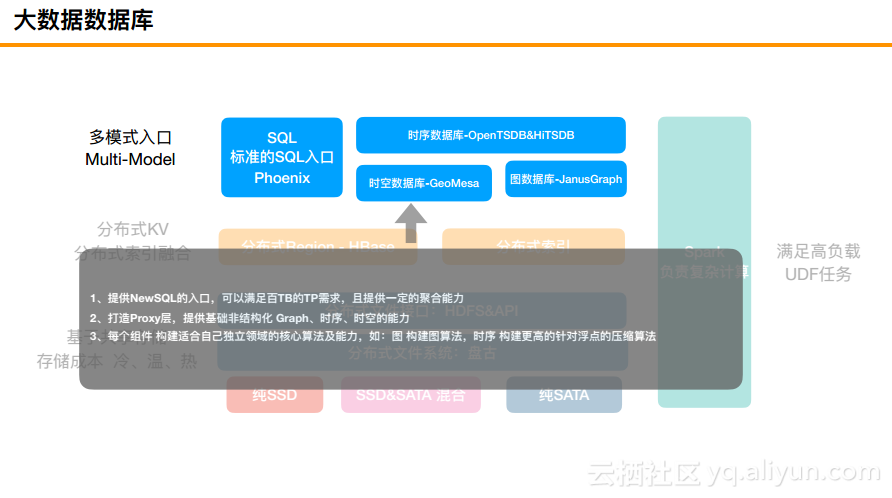
最后是必须要引入Spark的能力,上面的聚合都是单独的Client节点或者Proxy进行的聚合,是无法满足非常复杂的场景的。HBase结合Spark将会提供灵活独特的资源满足。这就是阿里巴巴的大数据数据库的总体结构,相信很多公司自己在做的时候也大致是这样的,当然对于具体的每一层而言都可能以自己的方式进行构建。
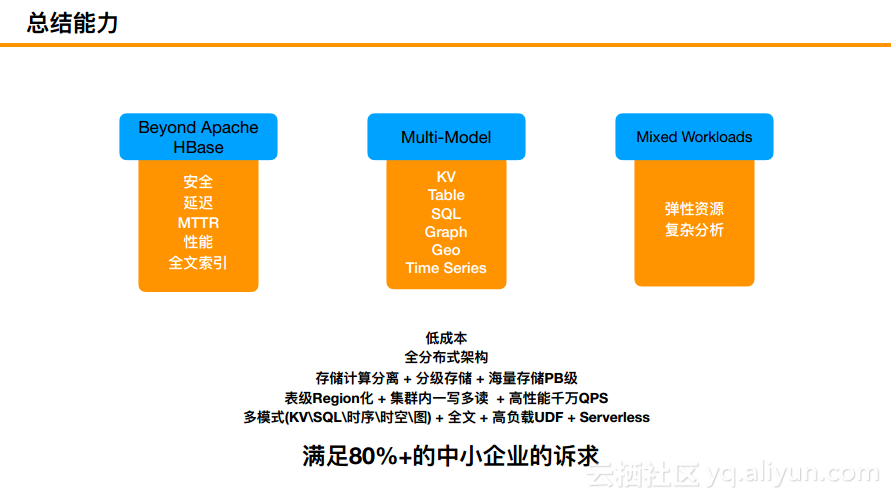
总结能力而言就是超越Apache HBase、多模式的数据库以及混合的负载,最终实现低成本、全分布式架构等能力,能够满足80%以上中小企业的诉求。
三、部署细节
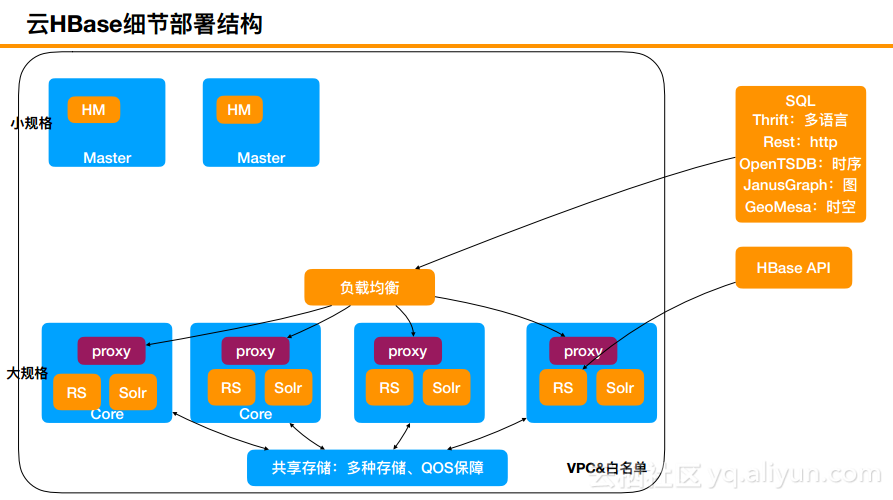
云HBase细节部署结构
对于云HBase的部署结构而言,会先在大规格上面部署proxy接口,前面做一个负载均衡去提供SQL、Thrift的Rest、OpenTSDB、JanusGraph以及GeoMesa这样的能力,RS和Solr等组件都会直接承接到下面的共享存储。
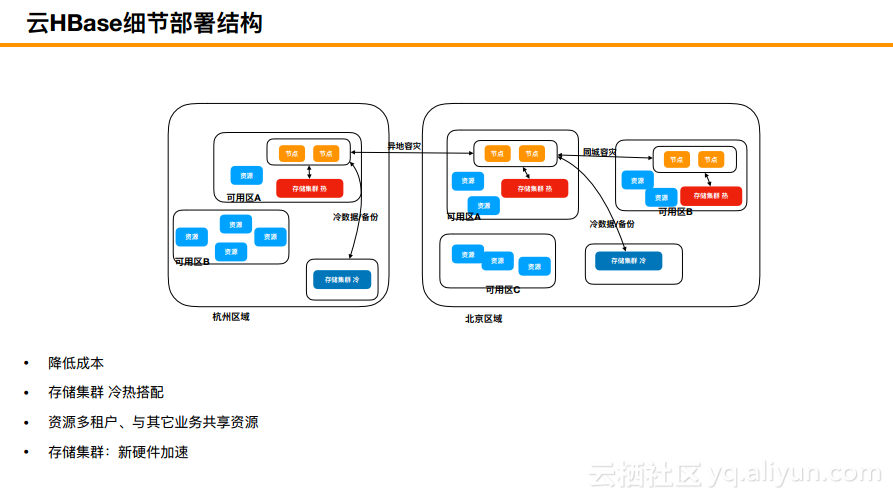
下图所展现的是全局的部署结构。图中分为杭州区域和北京区域,当然除此之外还有其他区域,每个区域之间有一个类似移动容灾的能力。这套集群的存储节点和可用区A的数据是放在一起的,冷存储是多个可用区混合的。对于阿里云等云厂商而言,可用区的概念就是其爆炸半径,也就是某一个炸弹在某个地方爆炸了但是却不能影响云中心,这就是可用区的概念。大概两个可用区之间,一般而言的延迟是1到2毫秒,甚至是3毫秒,所以如果是比较热的数据尽量可用区内放,如果是比较冷的数据,比如车联网或者20~30毫秒延迟也没有什么影响的情况下,如果访问频次也比较低,那么就可以直接把这些数据拖出来。基本原则是:在多个可用区大家共享一个冷集群可以降低成本,而热集群和温集群则是每个可用区都有以此来保证低延迟。两地之间也可以做一些容灾的事情。
四、运维能力
运维能力主要首先体现在产品层、接入层和网络层,无论是滴滴、360还是其他的公司也都是这样做的,阿里云是按照非常标准的网络协议或者云协议来实现的。
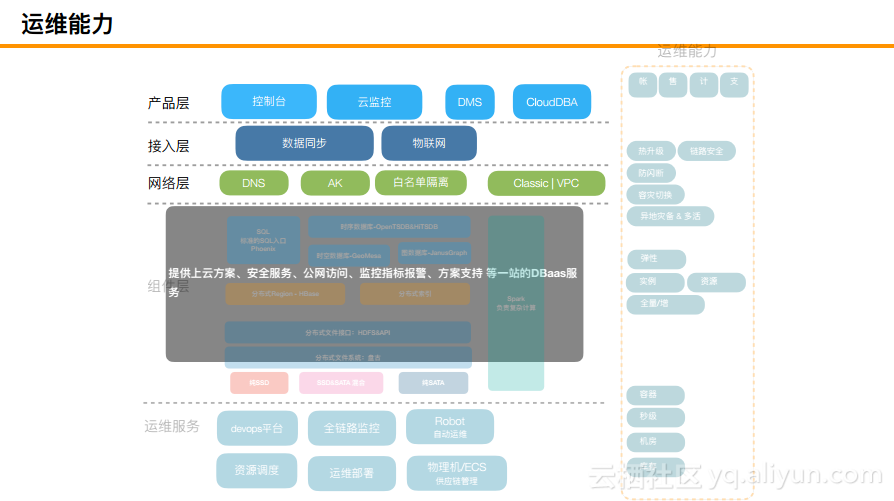
其次,阿里云大数据数据库服务所能提供的自动化运维能力包括自动部署集群、自动守护进程、可用性检测以及报警、节点和磁盘扩容等。
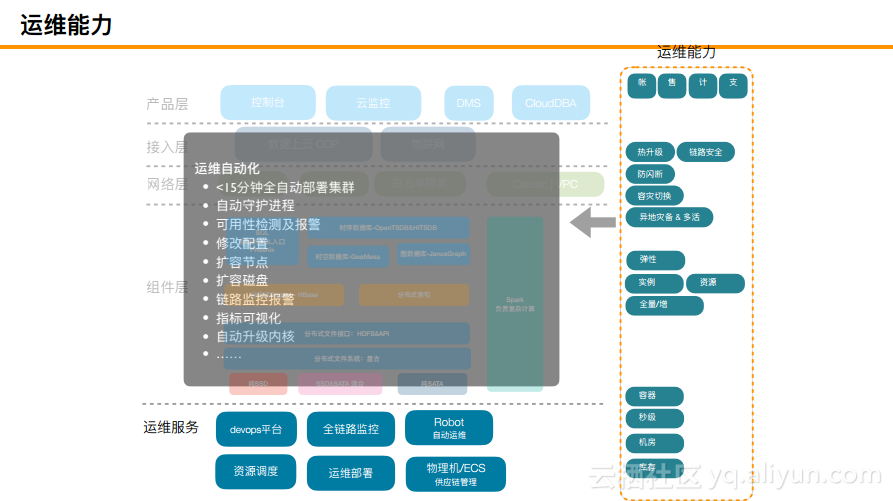
总结而言,阿里云大数据数据库所提供的运维能力如下所示。可能仅需要点一个按钮,成千上百的进程就生成了,而且可以在15分钟之内交付集群,但是如果线下自己搭建则是非常困难的。而且不需要提前规划容量,因为存储和计算分离,所以可以随时进行调整,发现资源少了或者多了,随时都可以通过点击按钮进行调整,也是非常方便的。

五、生态组件
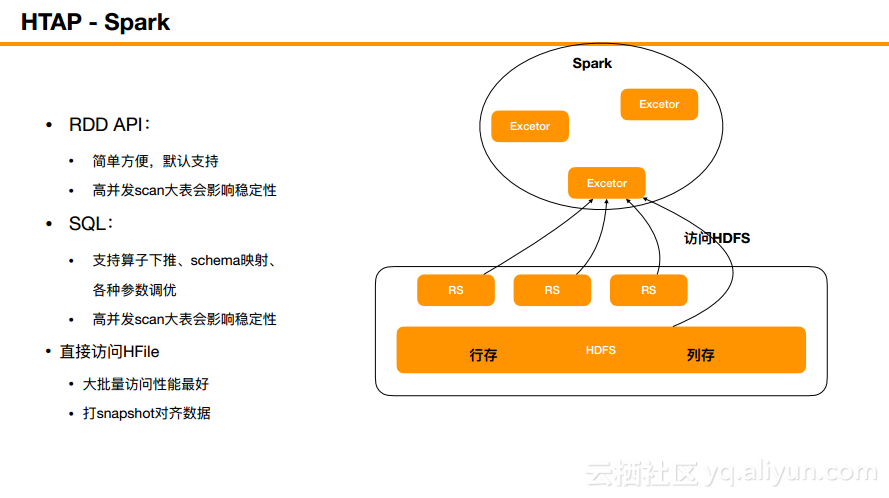
对于生态组件这部分由于时间关系,就简单讲下。Phoenix、JanusGraph、OpenTSDB、GeoMesa单独讲也不少内容。讲下Spark,目前HTAP非常火爆。跟HBase结合做复杂分析的是Spark,Spark可以配合HBase一起做非常复杂的计算。推荐直接采取SQL的入口,比较简单方便,且目前做了不少优化,比如算子下沉等。
六、实际案例
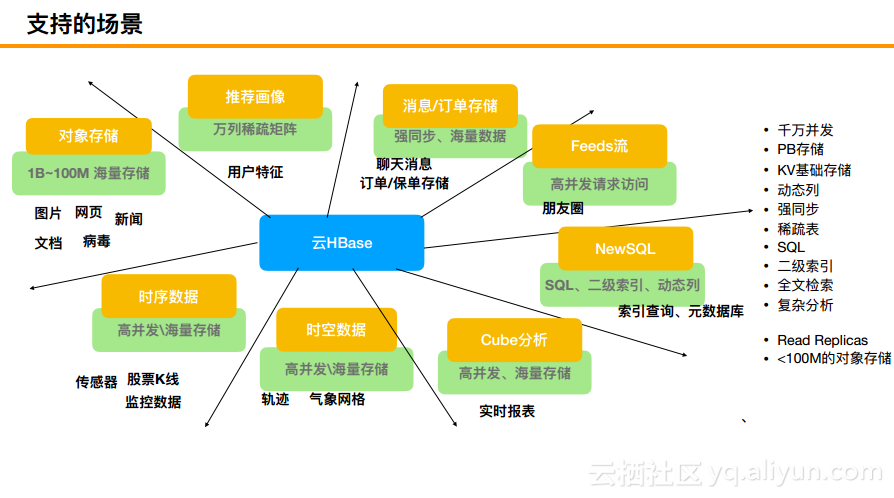
HBase能够支持大概8种场景,即对象存储、推荐画像、消息/订单存储、Feeds流、NewSQL、Cube分析、时空数据、时序数据等场景。
客户案例 - 某车联网公司
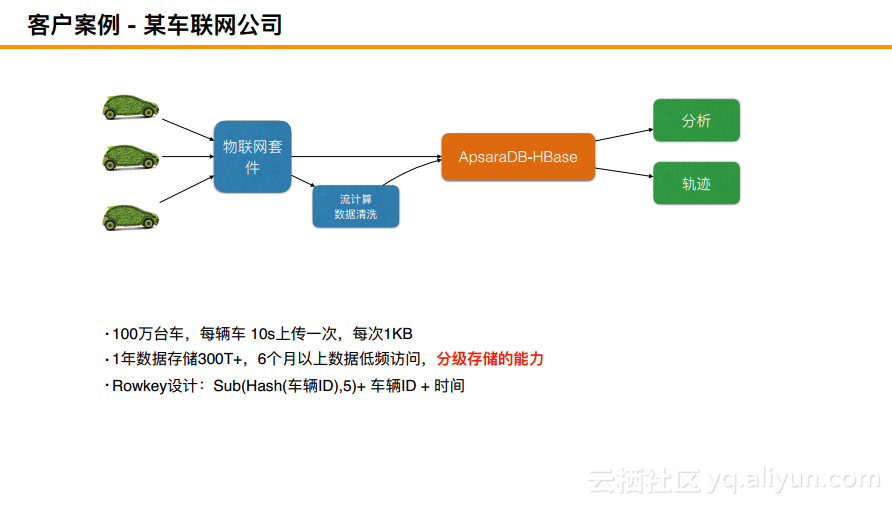
该车联网公司大概有一百万辆车,那么一年大概需要存储300T的数据,对于300T的数据而言,6个月以上是低频访问,而6个月之前则可以放到冷存储,可以以1.3份EC进行访问。设计使得HBase能够同时支持两种文件系统,一种文件系统支持写入HDFS,另外一种支持写入另一种介质。
客户案例 - 大数据风控公司
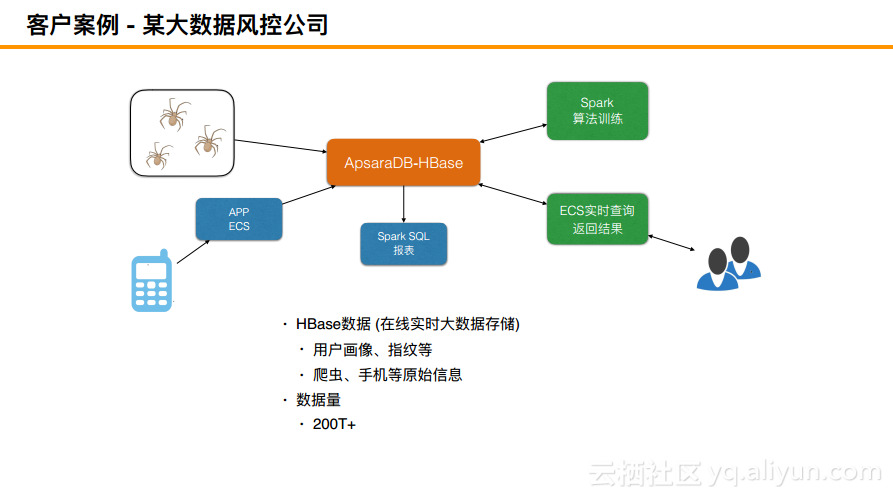
另外一个案例是大数据风控公司,其主要做的是大数据风控存储,其首先需要爬取很多数据过来并将这些数据塞到HBase里面去,并做了一些Spark算法训练,再去做一些ECS的实时数据报表,这也是一个非常典型的场景。
客户案例 - 某社交公司
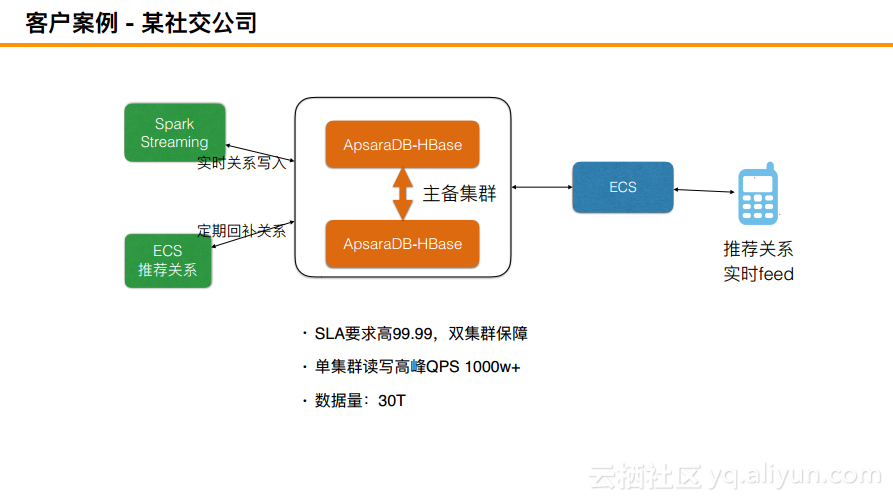
某社交公司的案例大致就是相当于用户注册了一个账号,就需要向你推荐其他的人,如何实现推荐呢?其实就是当注册完成之后,数据会立即流入到SparkStreaming里面,之后立即查找用户标签,并根据用户标签对大量相关的用户进行推荐。
客户案例 - 某基金公司
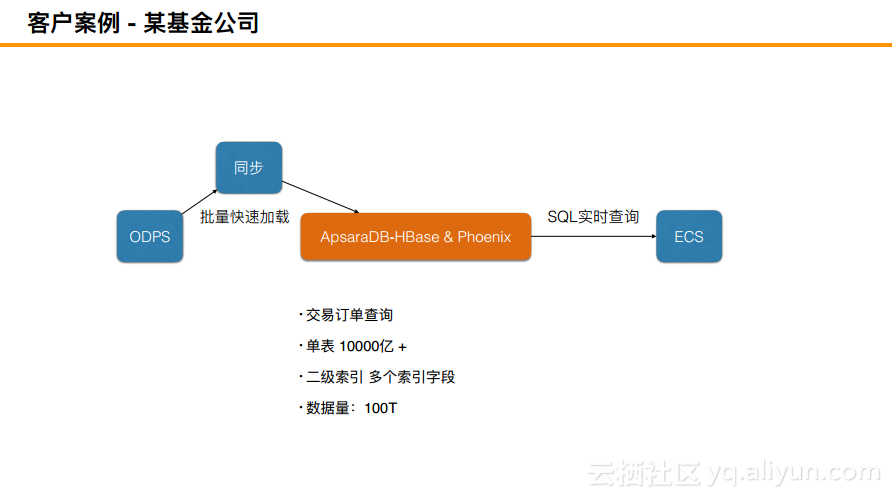
这个基金公司的数据量非常多,有万亿以上的数据,能够达到100T以上,其是使用Phoenix做搜索和实时查询的,其将索引通过ODPS+Spark将数据拖取出来并放入到HBase里面去,简单而言就是需要支持如此大的数据量在延迟比较低的情况下的查询。
客户案例 - 某公司报表系统
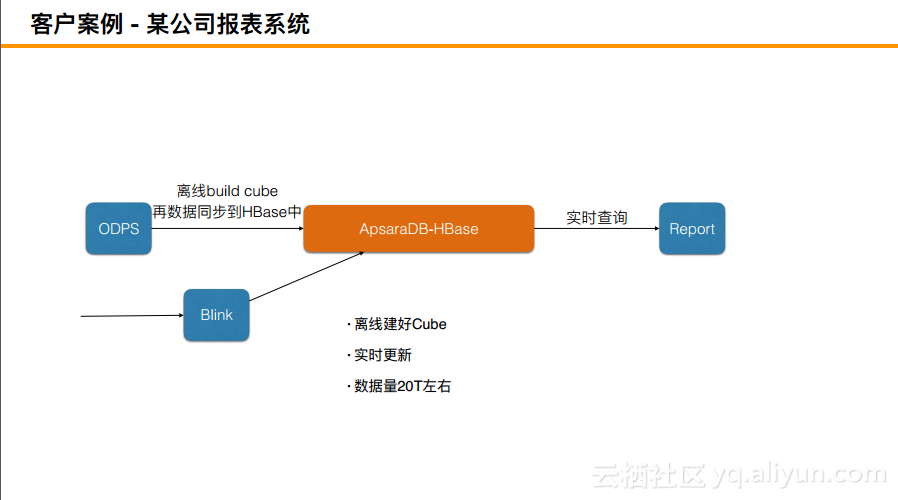
大部分做报表的公司基本都是这样操作的,最适合的就是用Lambda最适合查询低延迟、数据量大并且简单的场景,并且可以定制业务本身,来满足业务诉求。离线建好Cube,流式实现实时更新,并且数据量可以达到20T+左右。
七、展望未来
硬件发展带来的变化
大家能够发现硬件的发展变化是非常快的,万兆网的普及以及存储和计算的分离不断加速;其次,固态存储容量更大,价位更低,未来SSD甚至会比SATA更加便宜;此外,内存也在不断增长,并且去向可持久化,未来使用内存当做存储也能会快速实现。
提升分析能力
原来需要结合Spark所提供的分析能力,如何实现及时分析以及行转列等。
不断加强单个组件的能力
阿里云的技术团队也在不断加强单个组件的能力,包括完善和满足图、时空、时序的诉求。
其实还有非常有意思的两点,离线Compaction和备份即是分析。
离线Compaction
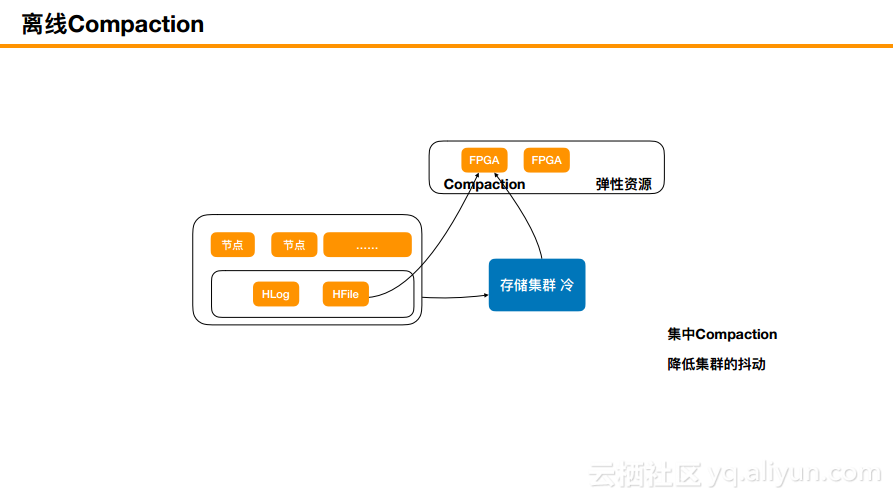
离线Compaction其实是非常耗费临时流量的,这时候通过引入弹性资源,因为ECS里面有FPGA的弹性资源,当将FPGA的弹性资源申请过来,把数据拖到弹性资源池进行Compaction,这是不会对原集群的CPU计算产生影响的。阿里云技术团队在这部分使得集群没有Major的影响。
备份及分析
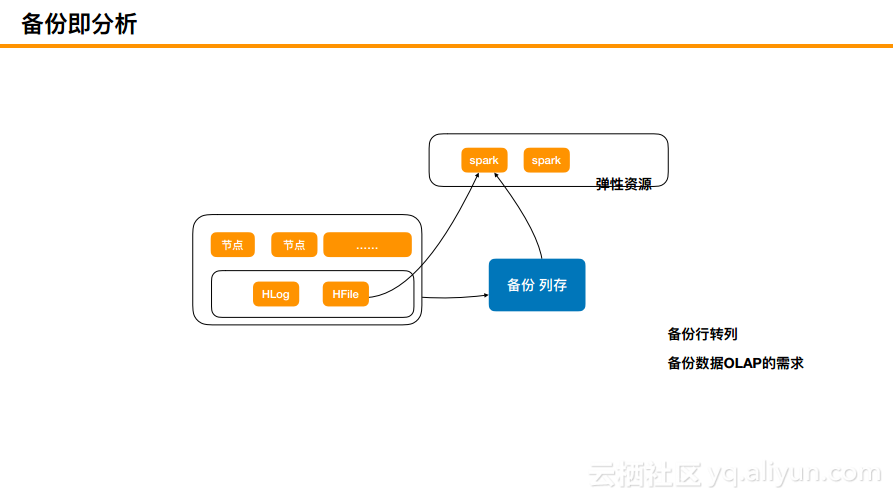
其次因为云上很多数据需要备份,既然需要备份,那么为何不备份成列存?比如HBase是行存的,将其备份成列存,这样就可以直接满足列式分析,这也是目前阿里云在研究的内容,也就是将备份数据作为直接分析的场景。比如上图中的HBase前面的数据流过来,将实时或者半实时的数据转化为列存,在列存储上面架一个Spark就可以满足非常高的复杂分析的要求。
总结与回顾
本文主要分享了为什么选择HBase、HBase部署细节、云管控做了什么事情、生态组件以及实际案例等,最后分享了一些对于HBase未来的展望。
本文内容整理自演讲视频以及PPT。
存储量/并发计算增大
随着关系型数据库存储和业务的挑战,数据量慢慢变大。其实,在以前包括阿里在内的很多企业使用的往往是使用ECS下面挂载MySQL数据库或者磁盘这样的方式,这样的架构能够具备四种能力,即计算力、检索、存储以及事务。而当数据量变大之后,阿里就换成了另外一套架构,主要使用Spark+下层的ES/Solr和HBase以及列存相应的组件。这样的架构则面对着数据量大、分布式复杂以及成本高等问题。
目前来说,非结构化业务也在逐渐地增多,包括时序和时空数据以及最新的NewSQL等,这里的NewSQL虽然属于比较时髦的词,但是实际上是在分布式上加了一些SQL的能力。这里对于工程的挑战就是比较复杂。
其实可以将数据世界大致分为四个象限:复杂性、灵活性、读写延迟以及分布式。分布式肯定是少不了的,缺少了分布式什么问题都解决不了,所以就需要在另外的复杂性、灵活性和读写延迟中寻找平衡。大致发现Hadoop、Spark解决的是灵活性和复杂性的问题;一边则是满足读延迟, Kylin主要满足读延迟的,提前需要Build一些Cube;另外在延迟及灵活性上一般是使用HBase加上solr等搭配。包括Hadoop以及Spark也都可以和HBase进行组合实现一些业务,kylin也是构建在HBase之上的,并且很多企业也都是这样做的。
因为本文的主题是云能够为HBase带来什么,其实云所能带来很多东西。比如云带来的弹性、复用、分离以及新硬件等特性,对于目前层出不穷的新硬件而言,像RDMA、FPGA、GPU等新硬件,很多小公司不会自己去购买这些,但是在云上就会提供这些硬件的能力,并且不同公司可以去复用这些硬件。云所带来的价值更多地就是为了降低成本,以及快速构建系统获取更多的商机。 这些就是云的能力。
二、云HBase架构的思考
大数据数据库
首先,所有的底层存储将会提供冷、温、热三种介质,一种是纯粹的SSD,一种是SSD和SATA混合,这里用到了2块SSD和10块SATA,也就是SSD作为一个写的缓存,而第三种是纯粹的SATA,且做了EC。在这之上是阿里的分布式文件系统盘古以及文件接口。每个集群也可以同时支持多种介质,不同介质可以采取不同的压缩算法降低成本。此外,计算资源和存储资源也是完全分离的,分离之后可以进行单独的扩容,完全不用担心到底是存储多还是计算多.
总结能力而言就是超越Apache HBase、多模式的数据库以及混合的负载,最终实现低成本、全分布式架构等能力,能够满足80%以上中小企业的诉求。
三、部署细节
云HBase细节部署结构
对于云HBase的部署结构而言,会先在大规格上面部署proxy接口,前面做一个负载均衡去提供SQL、Thrift的Rest、OpenTSDB、JanusGraph以及GeoMesa这样的能力,RS和Solr等组件都会直接承接到下面的共享存储。
四、运维能力
运维能力主要首先体现在产品层、接入层和网络层,无论是滴滴、360还是其他的公司也都是这样做的,阿里云是按照非常标准的网络协议或者云协议来实现的。
五、生态组件
对于生态组件这部分由于时间关系,就简单讲下。Phoenix、JanusGraph、OpenTSDB、GeoMesa单独讲也不少内容。讲下Spark,目前HTAP非常火爆。跟HBase结合做复杂分析的是Spark,Spark可以配合HBase一起做非常复杂的计算。推荐直接采取SQL的入口,比较简单方便,且目前做了不少优化,比如算子下沉等。
六、实际案例
HBase能够支持大概8种场景,即对象存储、推荐画像、消息/订单存储、Feeds流、NewSQL、Cube分析、时空数据、时序数据等场景。
客户案例 - 大数据风控公司
客户案例 - 某社交公司
客户案例 - 某基金公司
客户案例 - 某公司报表系统
七、展望未来
硬件发展带来的变化
大家能够发现硬件的发展变化是非常快的,万兆网的普及以及存储和计算的分离不断加速;其次,固态存储容量更大,价位更低,未来SSD甚至会比SATA更加便宜;此外,内存也在不断增长,并且去向可持久化,未来使用内存当做存储也能会快速实现。
提升分析能力
原来需要结合Spark所提供的分析能力,如何实现及时分析以及行转列等。
不断加强单个组件的能力
阿里云的技术团队也在不断加强单个组件的能力,包括完善和满足图、时空、时序的诉求。
其实还有非常有意思的两点,离线Compaction和备份即是分析。
离线Compaction
备份及分析
总结与回顾
本文主要分享了为什么选择HBase、HBase部署细节、云管控做了什么事情、生态组件以及实际案例等,最后分享了一些对于HBase未来的展望。
本文由云栖志愿小组贾子甲整理,编辑不与





