简介
对于任何业务而言,基于时间进行分析都是至关重要的。库存量应该保持在多少?你希望商店的客流量是多少?多少人会乘坐飞机旅游?类似这样待解决的问题都是重要的时间序列问题。
这就是时间序列预测被看作数据科学家必备技能的原因。从预测天气到预测产品的销售情况,时间序列是数据科学体系的一部分,并且是成为一个数据科学家必须要补充的技能。
如果你是菜鸟,时间序列为你提供了一个很好的途径去实践项目。你可以非常轻易地应用时间序列,它会带领你进入更大的机器学习世界。

Prophet是Facebook发布的基于可分解(趋势+季节+节假日)模型的开源库。它让我们可以用简单直观的参数进行高精度的时间序列预测,并且支持自定义季节和节假日的影响。
本文中,我们将介绍Prophet如何产生快速可靠的预测,并通过Python进行演示。最终结果将会让你大吃一惊!
本文目录
1. Prophet有什么创新点?
2. Prophet预测模型
3. Prophet实战(附Python和R代码)
Prophet有什么创新点?
当预测模型没有按预期运行时,我们希望针对问题来调整模型的参数。调整参数需要对时间序列的工作原理有全面的理解。例如automated ARIMA首先输入的参数是差分的最大阶数,自回归分量和移动平均分量。普通分析师不知道如何调整顺序来避免这种表现,这是一种很难掌握积累的专业知识。

Prophet包提供了直观易调的参数,即使是对缺乏模型知识的人来说,也可以据此对各种商业问题做出有意义的预测。
Prophet预测模型
时间序列模型可分解为三个主要组成部分:趋势,季节性和节假日。它们按如下公式组合:
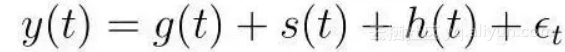
Prophet使用时间为回归元,尝试拟合线性和非线性的时间函数项,采取类似霍尔特-温特斯( Holt-Winters )指数平滑的方法,将季节作为额外的成分来建模。事实上,我们将预测问题类比为拟合曲线模型,而不是精确地去看时间序列中每个时点上的观测值。
1. 趋势
趋势是对时间序列中的非周期部分或趋势部分拟合分段线性函数,线性拟合会将特殊点和缺失数据的影响降到最小。
这里要问一个重要问题-我们是否希望目标在整个预测区间内持续增长或下降?通常情况下,一些非线性增长的案例会有最大容量限制,比如以下案例:
假设我们要预测未来12个月某app在某地区的下载量,最大下载量总是受该地区智能手机用户总数的限制。然而,智能手机用户的数量也会随着时间的推移而增加。
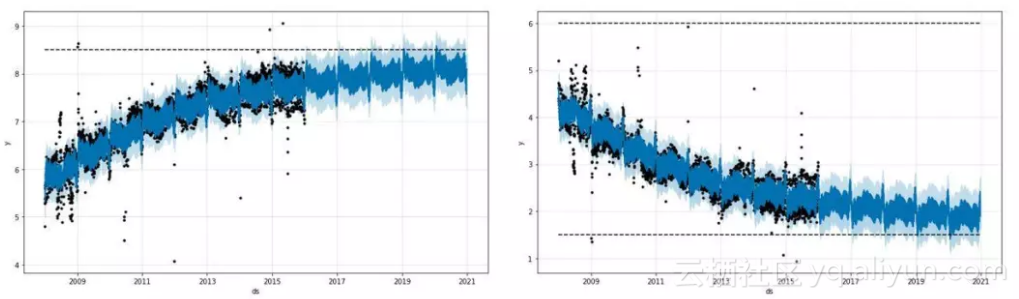
基于这样的领域知识,分析师可以定义时间序列预测的容量限制为C(t)。
另一个要回答的问题是-时间序列是否会因为其他现象发生潜在变化,例如新产品发布、不可预见的灾难等。这种情况下,增长率是会改变的。这些突变点是自动选择的,然而有需要的时候也可以手动输入突变点。在下图中,点线代表给定时间序列中的突变点。
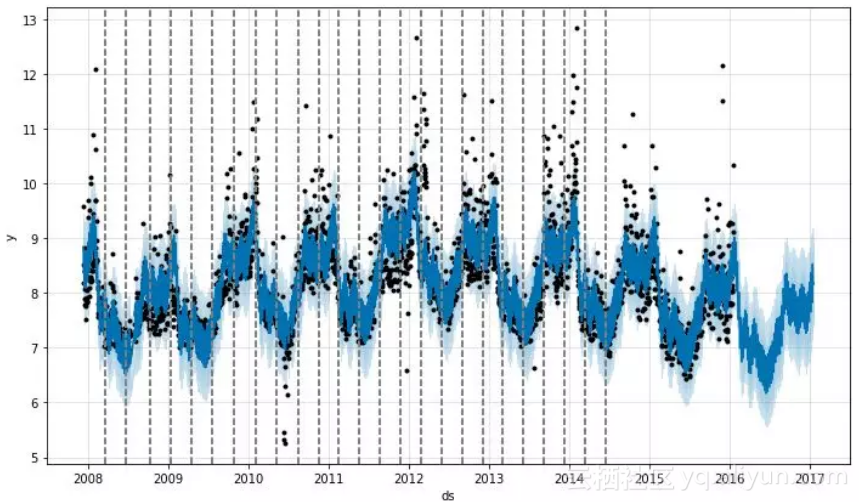
随着突变点数量的增多,拟合变得更灵活。在研究趋势成分时,分析师要面临两个基本问题:
-
过拟合
-
欠拟合
参数changepoint_prior_scale可以用来调整趋势的灵活性并解决以上两个问题。参数的值越大,拟合的时间序列曲线越灵活。
2. 季节性
为了拟合并预测季节的效果,Prophet基于傅里叶级数提出了一个灵活的模型。季节效应S(t)根据以下方程进行估算:
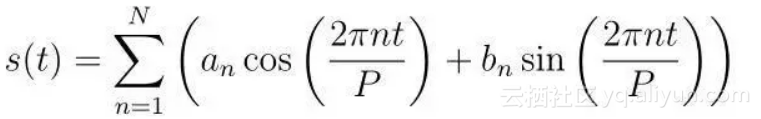
P是周期(年度数据的P是365.25,周数据的P是7)。
对季节性建模时,需要在给定N的情况下,估计参数[a1,b1……aN, bN]。
傅里叶阶数N是一个重要的参数,它用来定义模型中是否考虑高频变化。对时间序列来说,如果分析师认为高频变化的成分只是噪声,没必要在模型中考虑,可以把N设为较低的值。如果不是,N可以被设置为较高的值并用于提升预测精度。
3. 节假日和大事件
节假日和大事件会导致时间序列中出现可预测的波动。例如,印度的排灯节(Diwali)每年的日期都不同,在此期间人们大多会购买大量新商品。
Prophet允许分析师使用过去和未来事件的自定义列表。这些大事件前后的日期将会被单独考虑,并且通过拟合附加的参数模拟节假日和事件的效果。
Prophet实战(附Python代码)
目前Prophet只适用于Python和R,这两者有同样的功能。
Python中,使用Prophet()函数来定义Prophet预测模型。让我们看一下最重要的参数。
1. 趋势参数
| 参数 |
描述 |
| growth |
‘linear’或‘logistic’用来规定线性或逻辑曲线趋势 |
| changepoints |
包括潜在突变点的日期列表(不指明则默认为自动识别) |
| n_changepoints |
若不指定突变点,则需要提供自动识别的突变点数量 |
| changepoint_prior_scale |
设定自动突变点选择的灵活性 |
2. 季节&假日参数
| 参数 |
描述 |
| yearly_seasonality |
周期为年的季节性 |
| weekly_seasonality |
周期为周的季节性 |
| daily_seasonality |
周期为日的季节性 |
| holidays |
内置的节假日名称和日期 |
| seasonality_prior_scale |
改变季节模型的强度 |
| holiday_prior_scale |
改变假日模型的强度 |
yearly_seasonality、weekly_seasonality和daily_seasonality取值为True或False,没有上一节中讨论的傅里叶项。若值为True,默认取傅里叶项为10。Prior scales用来定义拟合过程中季节或节假日的权重程度。
3. 通过Prophet预测客运交通
现在我们已经了解了这个神奇工具的细节,接下来让我们通过实际的数据集来看看它的潜力。这里我在Python中运用Prophet来解决下面链接(DATAHACK平台)中的实际问题。
DATAHACK平台:
https://datahack.analyticsvidhya.com/contest/practice-problem-time-series-2/
该数据集是一个单变量的时间序列,即某新型公共交通服务的每小时客运量。基于给定的过去25个月的历史交通流量数据,我们可以尝试预测未来七个月的交通情况。
基本的探索性数据分析(EDA)可以通过以下课程获取:
课程链接:
https://trainings.analyticsvidhya.com/courses/course-v1:AnalyticsVidhya+TS_101+TS_term1/about
Python实现如下:
导入所需要的包并读入数据集
#Importing datasets
import pandas as pd
import numpy as np
from fbprophet import Prophet
#Read train and test
train = pd.read_csv('Train_SU63ISt.csv')
test = pd.read_csv('Test_0qrQsBZ.csv')
#Convert to datetime format
train['Datetime'] = pd.to_datetime(train.Datetime,format='%d-%m-%Y %H:%M')
test['Datetime'] = pd.to_datetime(test.Datetime,format='%d-%m-%Y %H:%M')
train['hour'] = train.Datetime.dt.hour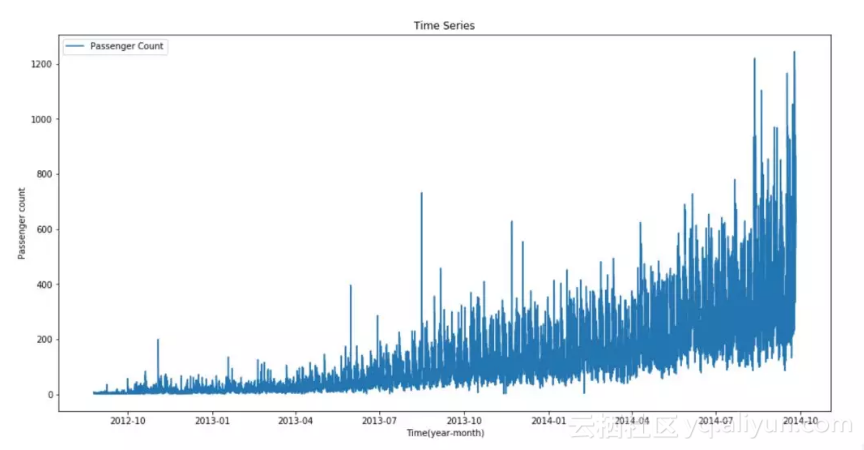
我们可以看到时间序列中有很多噪声。我们可以对其进行重采样并汇总,得到一个噪声更少的新序列,进而更易建模。
# Calculate average hourly fraction
hourly_frac = train.groupby(['hour']).mean()/np.sum(train.groupby(['hour']).mean())
hourly_frac.drop(['ID'], axis = 1, inplace = True)
hourly_frac.columns = ['fraction']
# convert to time series from dataframe
train.index = train.Datetime
train.drop(['ID','hour','Datetime'], axis = 1, inplace = True)
daily_train = train.resample('D').sum()Prophet要求时间序列中的变量名为:
y -> 目标(Target)
ds -> 时间(Datetime)
因此,下一步是基于上述规范来转换数据文件:
daily_train['ds'] = daily_train.index
daily_train['y'] = daily_train.Count
daily_train.drop(['Count'],axis = 1, inplace = True)
拟合Prophet模型:
m = Prophet(yearly_seasonality = True, seasonality_prior_scale=0.1)
m.fit(daily_train)
future = m.make_future_dataframe(periods=213)
forecast = m.predict(future)
我们可以通过以下命令来查看各个成分:
m.plot_components(forecast)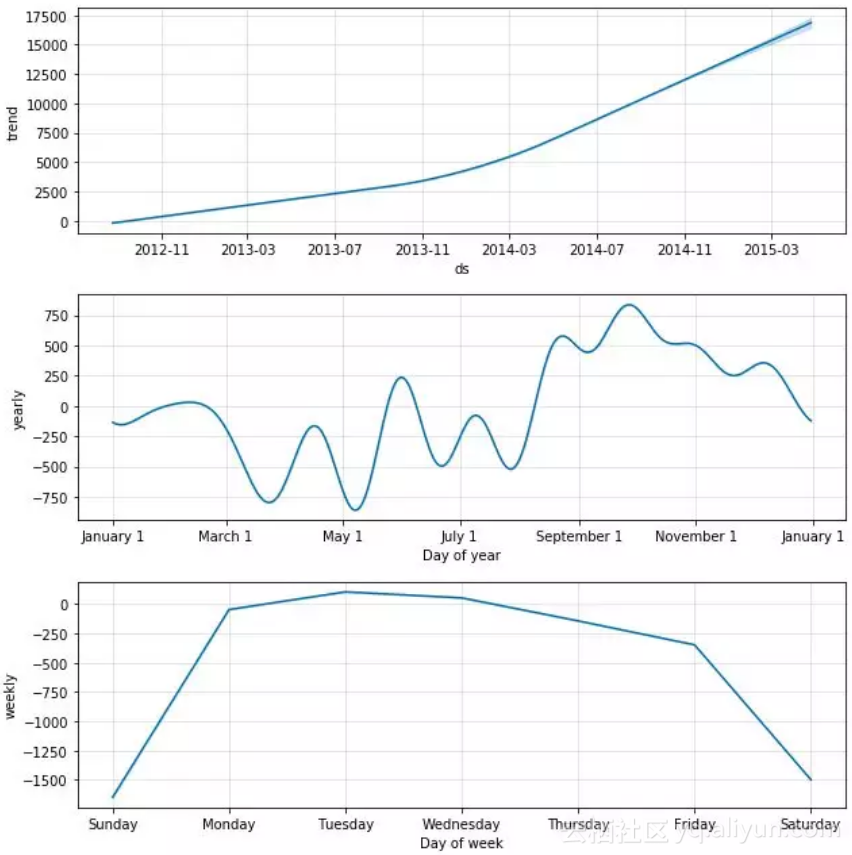
将0到23作为节点均等划分每小时,接下来我们可以把每日预测转化为每小时预测。基于每日数据的预测如下。
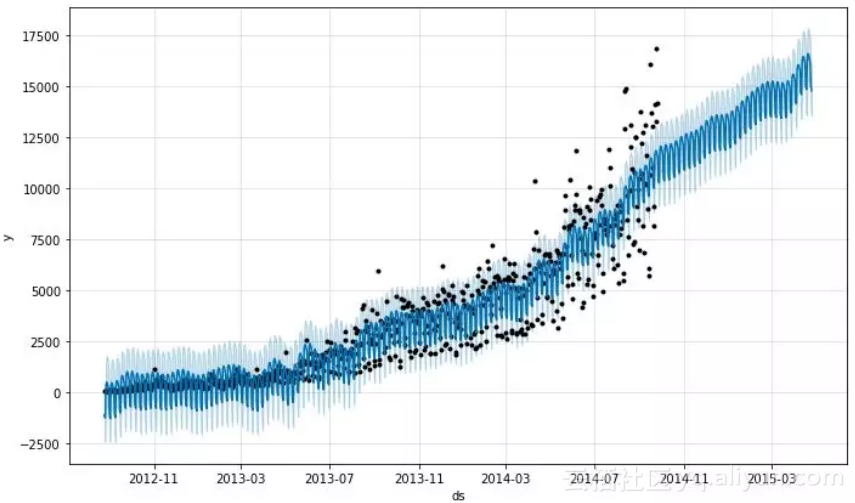
# Extract hour, day, month and year from both dataframes to merge
for df in [test, forecast]:
df['hour'] = df.Datetime.dt.hour
df['day'] = df.Datetime.dt.day
df['month'] = df.Datetime.dt.month
df['year'] = df.Datetime.dt.year
# Merge forecasts with given IDs
test = pd.merge(test,forecast, on=['day','month','year'], how='left')
cols = ['ID','hour','yhat']
test_new = test[cols]
# Merging hourly average fraction to the test data
test_new = pd.merge(test_new, hourly_frac, left_on = ['hour'], right_index=True, how = 'left')
# Convert daily aggregate to hourly traffic
test_new['Count'] = test_new['yhat'] * test_new['fraction']
test_new.drop(['yhat','fraction','hour'],axis = 1, inplace = True)
test_new.to_csv('prophet_sub.csv',index = False)我在公共积分榜上得到了206分,并得到了一个稳定的模型。读者可以继续调整超参数(季节性或变化性的傅里叶阶数)以得到更好的分数。读者也可以尝试使用不同的方法将每日转化为每小时的数据,可能会得到更好的分数。
R代码实现如下:
应用R解决同样的问题。
library(prophet)
library(data.table)
library(dplyr)
library(ggplot2)
# read data
train = fread("Train_SU63ISt.csv")
test = fread("Test_0qrQsBZ.csv")
# Extract date from the Datetime variable
train$Date = as.POSIXct(strptime(train$Datetime, "%d-%m-%Y"))
test$Date = as.POSIXct(strptime(test$Datetime, "%d-%m-%Y"))
# Convert 'Datetime' variable from character to date-time format
train$Datetime = as.POSIXct(strptime(train$Datetime, "%d-%m-%Y %H:%M"))
test$Datetime = as.POSIXct(strptime(test$Datetime, "%d-%m-%Y %H:%M"))
# Aggregate train data day-wise
aggr_train = train[,list(Count = sum(Count)), by = Date]
# Visualize the data
ggplot(aggr_train) + geom_line(aes(Date, Count))
# Change column names
names(aggr_train) = c("ds", "y")
# Model building
m = prophet(aggr_train)
future = make_future_dataframe(m, periods = 213)
forecast = predict(m, future)
# Visualize forecast
plot(m, forecast)
# proportion of mean hourly 'Count' based on train data
mean_hourly_count = train %>%
group_by(hour = hour(train$Datetime)) %>%
summarise(mean_count = mean(Count))
s = sum(mean_hourly_count$mean_count)
mean_hourly_count$count_proportion = mean_hourly_count$mean_count/s
# variable to store hourly Count
test_count = NULL
for(i in 763:nrow(forecast)){
test_count = append(test_count, mean_hourly_count$count_proportion * forecast$yhat[i])
}
test$Count = test_count尾记
Prophet确实是进行快速准确的时间序列预测的好选择。对于具备良好领域知识但是缺少预测模型技能的人来说,Prophet可以让他们直观地调整参数。读者可以直接在Prophet中拟合以小时为单位的数据并且在评论中讨论是否能得到更好的结果。
原文发布时间为:2018-06-11
本文作者:ANKIT CHOUDHARY