分布式系统八大谬论:
1.网络相当可靠
2.延迟为0
3.传输带宽是无限的
4.网络相当安全。
5.拓扑结构不会改变
6.必须要有一名管理员
7.传输成本为0
8.网络同质化。
分布式最常出现的问题:
1.通信异常。表现为网络通信成功,失败,超时这三种。
2.节点故障。表现为宕机,OOM
因此我们不要秀技术而分布式。特殊场景特殊使用。
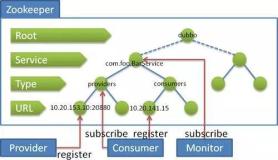
Zookeeper设计目的
1.最终一致性:client不论连接到哪个Server,展示给它都是同一个视图,这是zookeeper最重要的性能。
2.可靠性:具有简单、健壮、良好的性能,如果消息被到一台服务器接受,那么它将被所有的服务器接受。
3.实时性:Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。但由于网络延时等原因,Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口。
4.等待无关(wait-free):慢的或者失效的client不得干预快速的client的请求,使得每个client都能有效的等待。
5.原子性:更新只能成功或者失败,没有中间状态。
6.顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息a在消息b前发布,则在所有Server上消息a都将在消息b前被发布;偏序是指如果一个消息b在消息a后被同一个发送者发布,a必将排在b前面。
Zookeeper工作原理
Zookeeper 的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和 leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。
为了保证事务的顺序一致性,zookeeper采用了递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递增计数。
CAP理论,指的是在一个分布式系统中,不可能同时满足Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性)这三个基本需求,最多只能满足其中的两项。
1、一致性:
指数据在多个副本之间是否能够保持一致的特性。当执行数据更新操作后,仍然剋保证系统数据处于一致的状态。
2、可用性(高可用):
系统提供的服务必须一直处于可用的状态。对于用户的每一个操作请求总是能够在“有限的时间内”返回结果。这个有限时间是系统设计之初就指定好的系统运行指标。返回的结果指的是系统返回用户的一个正常响应结果,而不是“out ot memory error”之类的系统错误信息。
3、分区容错性(数据分片):
分布式系统在遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足一致性和可用性的服务,除非是整个网络环境都发生了故障。组成分布式系统的每个节点的加入与退出都可以看成是一个特殊的网络分区。
一个分布式系统无法同时满足这三个条件,只能满足两个,意味着我们要抛弃其中的一项,如下图所示:
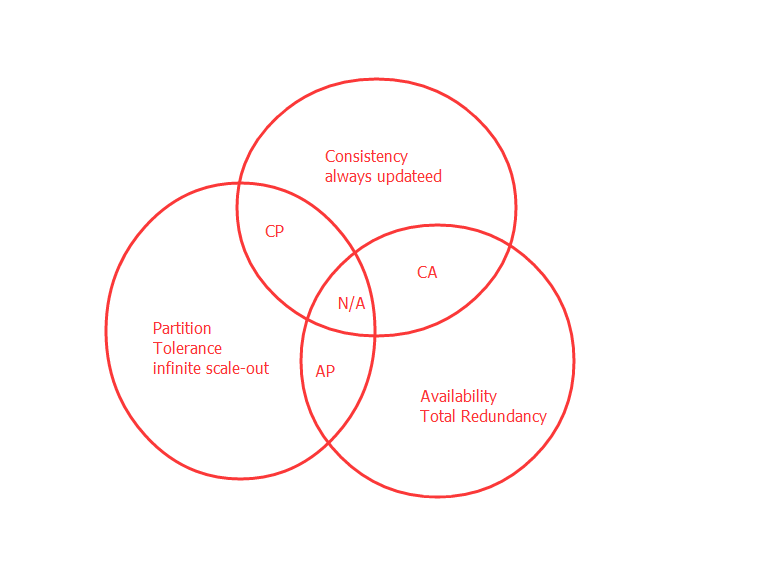
1、CA,放弃P:将所有数据都放在一个分布式节点上。这同时放弃了系统的可扩展性。
2、CP,放弃A:一旦系统遇到故障时,受影响的服务器需要等待一段时间,在恢复期间无法对外提供正常的服务。
3、AP,放弃C:这里的放弃一致性是指放弃数据强一致性,而保留数据的最终一致性。系统无法实时保持数据的一致,但承诺在一个限定的时间窗口内,数据最终能够达到一致的状态。
对于分布式系统而言,分区容错性是一个最基本的要求,因为分布式系统中的组件必然需要部署到不通的节点,必然会出现子网络,在分布式系统中,网络问题是必定会出现的异常。因此分布式系统只能在C(一致性)和A(可用性)之间进行权衡。
BASE理论是指,Basically Available(基本可用)、Soft-state( 软状态/柔性事务)、Eventual Consistency(最终一致性)。是基于CAP定理演化而来,是对CAP中一致性和可用性权衡的结果。
核心思想:即使无法做到强一致性,但每个业务根据自身的特点,采用适当的方式来使系统达到最终一致性。
1、基本可用:
指分布式系统在出现故障的时候,允许损失部分可用性,保证核心可用。但不等价于不可用。比如:搜索引擎0.5秒返回查询结果,但由于故障,2秒响应查询结果;网页访问过大时,部分用户提供降级服务,等。
2、软状态:
软状态是指允许系统存在中间状态,并且该中间状态不会影响系统整体可用性。即允许系统在不同节点间副本同步的时候存在延时。
3、最终一致性:
系统中的所有数据副本经过一定时间后,最终能够达到一致的状态,不需要实时保证系统数据的强一致性。最终一致性是弱一致性的一种特殊情况。
BASE理论面向的是大型高可用可扩展的分布式系统,通过牺牲强一致性来获得可用性。ACID是传统数据库常用的概念设计,追求强一致性模型。
ACID,指数据库事务正确执行的四个基本要素的缩写。包含:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。