我们知道Zookeeper的一致性是解决分布式事务的。
那么分布式事务代表的是强一致性。
强一致性解决的代表有以下协议(注意这几个协议跟zookeeper是没任何关系的,这是分布式的理论基础):
1. 2PC(二阶提交),顾名思义它分成两个阶段,先由一方进行提议(propose)并收集其他节点的反馈(vote),再根据反馈决定提交(commit)或中止(abort)事务。我们将提议的节点称为协调者(coordinator),其他参与决议节点称为参与者(participants, 或cohorts)。
在阶段1中,协调者发起一个提议,分别问询各参与者是否接受。
在阶段2中,协调者根据参与者的反馈,提交或中止事务,如果参与者全部同意则提交,只要有一个参与者不同意就中止。
如下图:
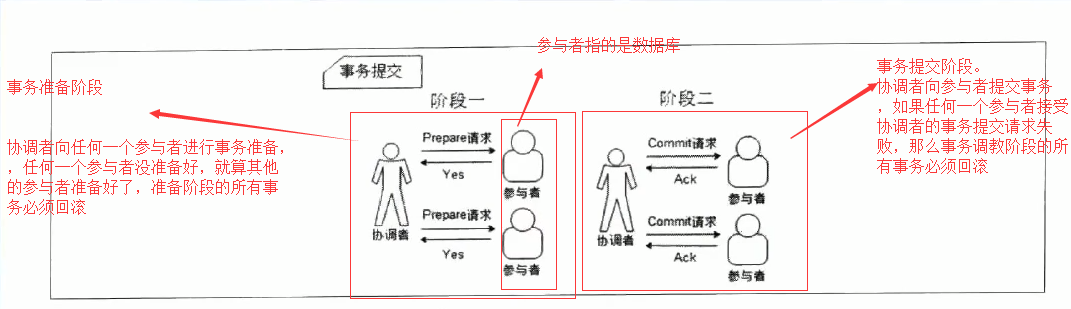
在异步环境并且没有节点宕机的模型下,2PC可以满足全认同、值合法、可结束,是解决一致性问题的一种协议。但如果再加上节点宕机的考虑,2PC是否还能解决一致性问题呢?
答案是可以的。
因为协调者如果在发起提议后宕机,那么参与者将进入阻塞状态、一直等待协调者回应以完成该次决议。这时需要另一角色把系统从不可结束的状态中带出来,我们把新增的这一角色叫协调者备份。协调者宕机一定时间后,协调者备份接替原协调者工作,通过问询各参与者的状态,决定阶段2是提交还是中止。这也要求 协调者/参与者 记录历史状态,以备协调者宕机后备份对参与者查询、协调者宕机恢复后重新找回状态。
从协调者接收到一次事务请求、发起提议到事务完成,经过2PC协议后增加了2次RTT(propose+commit),带来的时延增加相对较少。
这种方式有一定的缺点,就是增加了备份参与者,节点的沟通就越频繁,出现网络问题的概率就越大。
因此二阶段提交的总结是:2PC可以在异步网络+节点宕机恢复的模型下实现一致性
2. 3PC(三阶段提交):其实就是对二阶段提交进行改进了。
在二阶段提交中中一个参与者的状态只有它自己和协调者知晓,假如协调者提议后出现自身宕机,在备用启用之前,一个参与者又宕机了,其他参与者就会进入既不能回滚、又不能强制commit的阻塞状态,直到参与者宕机恢复。
那么会有这样的疑问:
1.可不可以去掉阻塞,使系统可以在commit/abort前回滚到决议发起前的初始状态呢?
2.当次决议中,参与者间可不可以知道对方的状态,又或者参与者间根本不依赖对方的状态
三阶段提交增加了一个准备提交阶段来解决以上问题。如下图:
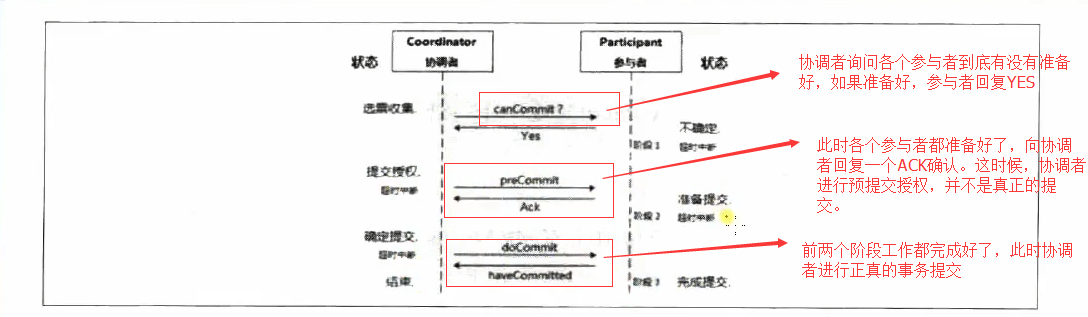
参阅这如果在不同阶段宕机,3阶段提交的处理方式:
第一阶段:协调者或备份未收到宕机参与者的反馈,直接中止事务;宕机的参与者恢复后,读取记录发现未发出赞成反馈,则自行中止该次事务。
第二阶段:协调者未收到宕机参与者的precommit ACK,之前已经收到了宕机参与者的赞成反馈,因为只有之前已经收到了宕机参与者的赞成反馈才进入了阶段二,协调者进行事务提交;协调者备份可以通过问询其他参与者获得这些信息;宕机的参与者恢复后发现收到precommit或已经发出赞成反馈,则自行commit这次事务。
第三阶段:即使协调者或协调者备份未收到宕机参与者的事务提交的 ACK,也要结束本次事务;宕机的参与者恢复后发现收到事务提交或者提交预授权,也将自行commit本次事务
3PC总结:三阶段提交有了准备提交(prepare to commit)阶段,3PC的事务处理延时也增加了1个RTT,变为3个RTT(propose+precommit+commit),但是它防止参与者宕机后整个系统进入阻塞态,增强了系统的高可用性,对一些特殊的业务场景是非常有用的。
这些2PC,3PC体现的层面,在JAVAEE中体现出来的是只要是JTA(Java Transaction API)。
JTA:提供了跨数据库连接(或其他JTA资源)的事务管理能力。JTA事务管理则由JTA容器实现,J2ee框架中事务管理器与应用程序,资源管理器,以及应用服务器之间的事务通讯。
JTA提供的支持有Jboss,Jboss类似与Tomcat的一个容器。Tomcat是天生不支持JTA的,要引入JOTM(Java Open Transaction Manager)可以解决。
3. NWR。N:代表数据分了多少片,即多少个节点。W:每次写入多少个节点算成功。R:每次读取多少个节点算成功。如下图:
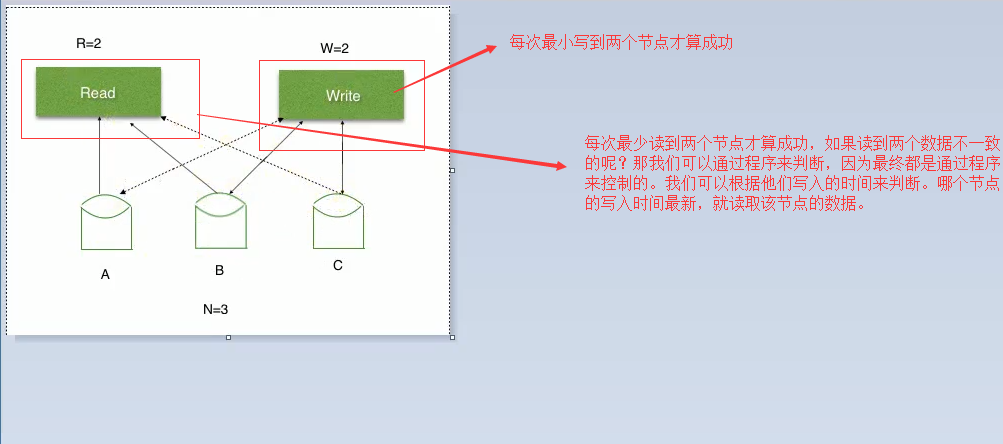
这样NWR也最终可以达到强一致性。
Zookeeper的核心算法——Paxos算法(Master选举算法)。
Paxos协议分为两个阶段。
这里我们首先要明确什么是提案:提案:[编号,值]即[key,value]。当Master宕机后,从节点向Acceptor提出提案让我这个从节点做Master,这些体验要给Acceptor决策。
整个过程分为两个阶段:
-
phase1(准备阶段)
-
Proposer向超过半数(n/2+1)Acceptor发起prepare消息(发送编号)
-
如果prepare符合协议规则Acceptor回复promise消息,否则拒绝
-
-
phase2(决议阶段或投票阶段)
-
如果超过半数Acceptor回复promise,Proposer向Acceptor发送accept消息(此时包含真实的值)
-
Acceptor检查accept消息是否符合规则,消息符合则批准accept请求
-
约束条件:
1.Acceptor必须接受他接收到的第一个提案。注意:这个是不完备的。如果恰好一半Acceptor接受的提案具有value A,另一半接受的提案具有value B,那么就无法形成多数派,无法批准任何一个value。
2.当且仅当Acceptor没有回应过编号大于n的prepare请求时,Acceptor接受(accept)编号为n的提案。
3.只有Acceptor没有接受过提案Proposer才能采用自己的Value,否者Proposer的Value提案为Acceptor中编号最大的Proposer Value;
4.一个提案被选中需要过半数的Acceptor接受。
根据上述过程当一个proposer发现存在编号更大的提案时将终止提案。这意味着提出一个编号更大的提案会终止之前的提案过程。如果两个proposer在这种情况下都转而提出一个编号更大的提案,就可能陷入活锁,违背了Progress的要求。这种情况下的解决方案是选举出一个leader,仅允许leader提出提案。但是由于消息传递的不确定性,可能有多个proposer自认为自己已经成为leader。Lamport在The Part-Time Parliament一文中描述并解决了这个问题。
step1:,设置时钟:proposer令localClock=globalClock.incrementAndGet()。为了让这套系统能正确运行,我们需要一个精确的时钟。由于操作系统的物理时钟经常是有偏差的,所以我们决定采用一个逻辑时钟。时钟的目的是给系统中 发生的每一个事件编排一个序号。假设我们有一台单独的机器提供了一个全局的计数器服务。它只支持一个方法:incrementAndGet()。这个方法 的作用是将计数器的值加一,并且返回增加后的值。我们将这个计数器称为globalClock。globalClock的初始值为0。然后,系统中的每个其它机器,都有一个自己的localClock,它的初始值来自globalClock。
step2:prepare:proposer向所有Acceptor发送一个prepare消息。接收方应返回它最近一次accept的value,以及 accept的时间,若在它还没有accept过value,那么就返回空。proposer只有在收到过半数的response之后,才可进入下一个阶段。一旦收到reject消息,那么就重头来。
step3:构造Proposal:proposer从prepare阶段收到的所有values中选取时间戳最新的一个。如果没有,那么它自己提议一个value。
step4:发送Proposal:proposer把value发送给其它所有机器,消息的时间戳取自localClock。接收方只要检查消息时间戳合法,那么就接受此value,把这个value和时间戳写入到硬盘上,然后答复OK,否则拒绝接受。proposer若收到任何的reject答复,则回到 step1。否则,在收到过半数的OK后,此Proposal被通过。
算法图解如下:
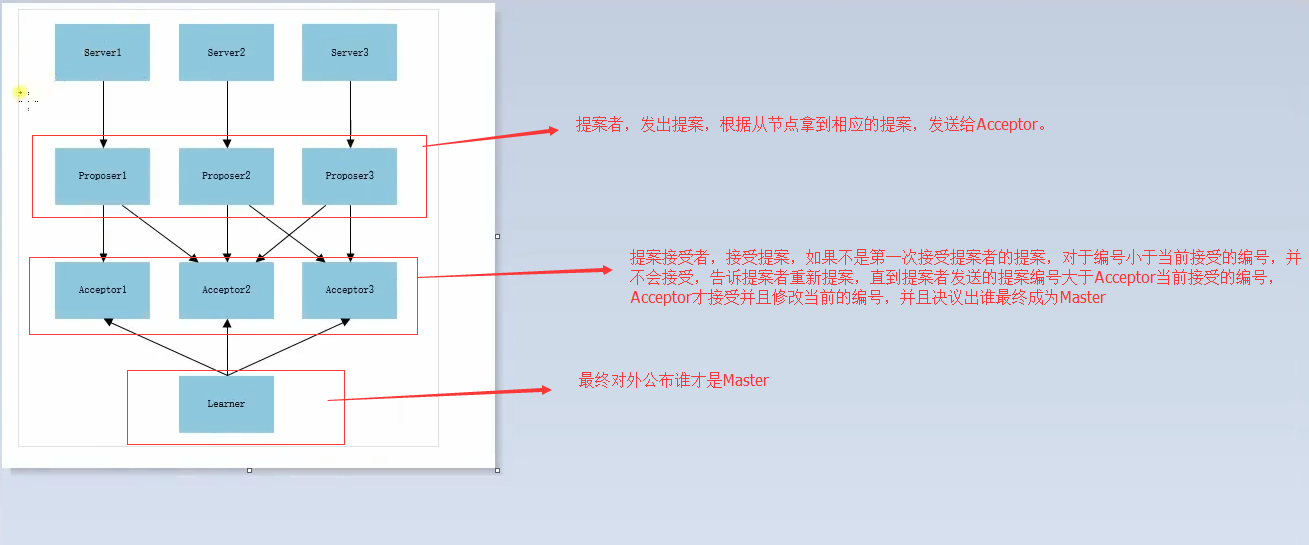
Phase1(准备阶段)
每个Server都向Proposer发消息称自己要成为leader,Server1往Proposer1发、Server2往Proposer2发、Server3往Proposer3发;
现在每个Proposer都接收到了Server1发来的消息但时间不一样,Proposer2先接收到了,然后是Proposer1,接着才是Proposer3;
Proposer2首先接收到消息所以他从系统中取得一个编号1,Proposer2向Acceptor2和Acceptor3发送一条,编号为1的消
息;接着Proposer1也接收到了Server1发来的消息,取得一个编号2,Proposer1向Acceptor1和Acceptor2发送一条,编号为2的消息; 最后Proposer3也接收到了Server3发来的消息,取得一个编号3,Proposer3向Acceptor2和Acceptor3发送一条,编号为3的消息;
这时Proposer1发送的消息先到达Acceptor1和Acceptor2,这两个都没有接收过请求所以接受了请求返回[2,null]给Proposer1,并承诺不接受编号小于2的请求;
此时Proposer2发送的消息到达Acceptor2和Acceptor3,Acceprot3没有接收过请求返回[1,null]给Proposer2,并承诺不接受编号小于1的请求,但这时Acceptor2已经接受过Proposer1的请求并承诺不接受编号小于的2的请求了,所以Acceptor2拒绝Proposer2的请求;
最后Proposer3发送的消息到达Acceptor2和Acceptor3,Acceptor2接受过提议,但此时编号为3大于Acceptor2的承诺2与Accetpor3的承诺1,所以接受提议返回[3,null];
Proposer2没收到过半的回复所以重新取得编号4,并发送给Acceptor2和Acceptor3,然后Acceptor2和Acceptor3通过
Phase2(决议阶段)
Proposer3收到过半(三个Server中两个)的返回,并且返回的Value为null,所以Proposer3提交了[3,server3]的议案;
Proposer1收到过半返回,返回的Value为null,所以Proposer1提交了[2,server1]的议案;
Proposer2收到过半返回,返回的Value为null,所以Proposer2提交了[4,server2]的议案;
Acceptor1、Acceptor2接收到Proposer1的提案[2,server1]请求,Acceptor2承诺编号大于4所以拒绝了通过,Acceptor1通过了请求;
Proposer2的提案[4,server2]发送到了Acceptor2、Acceptor3,提案编号为4所以Acceptor2、Acceptor3都通过了提案请求;
Acceptor2、Acceptor3接收到Proposer3的提案[3,server3]请求,Acceptor2、Acceptor3承诺编号大于4所以拒绝了提案;
此时过半的Acceptor都接受了Proposer2的提案[4,server2],Larner感知到了提案的通过,Larner学习提案,server2成为Leader;

