近日,伯克利和MIT研究者发布的一篇名为《Do CIFAR-10 Classifiers Generalize to CIFAR-10?》的新论文提出了学界一个尖锐的问题:包括CIFAR10在内的知名基准测试集,都存在验证集过拟合问题。
这一论文引起了Keras之父François Chollet的关注与力挺,关于数据集的讨论在推特上一发不可收拾,包括Gary Marcus和François都连发数条推特对此问题进行了讨论。
在连续20几个小时的连续发推中,François Chollet肯定了这篇论文带来对过测试集拟合问题的思考,但是也提出了一些论文中不恰当的地方。
最后,大神也提出了自己的建议,通过高熵验证过程(如k-fold验证)来解决这个问题。
让我们先来看看这篇论文到底说了什么。

这篇论文创建了一组真正“未出现过”的同类图像来测量 CIFAR-10 分类器的准确率,以验证当前的测试集是否会带来过拟合风险。
论文中称,我们通常只能获取具备同样分布的有限新数据。现在大家普遍接受在算法和模型设计过程中多次重用同样的测试集。但显而易见的是,当前的研究方法论忽视了一个关键假设:分类器与测试集应该独立存在。
这种不独立带来了显而易见的威胁——研究社区可能会设计出只在特定测试集上性能良好,但无法泛化至新数据的模型。
大数据文摘微信公众号后台回复"过拟合"下载本篇论文
显而易见,目前深度学习领域的很多“标题党论文”,都存在验证集过拟合问题,包括CIFAR10在内的知名基准测试集。
大量“标题党”论文
François Chollet称很高兴在这篇论文《Do CIFAR-10 Classifiers Generalize to CIFAR-10?》看到对验证集过拟合的量化。从2015年以来,ImageNet数据集也存在这样的问题。
接下来的一天中,François Chollet之后还针对这一问题发表了很多评论。
以下为François Chollet推特部分内容:
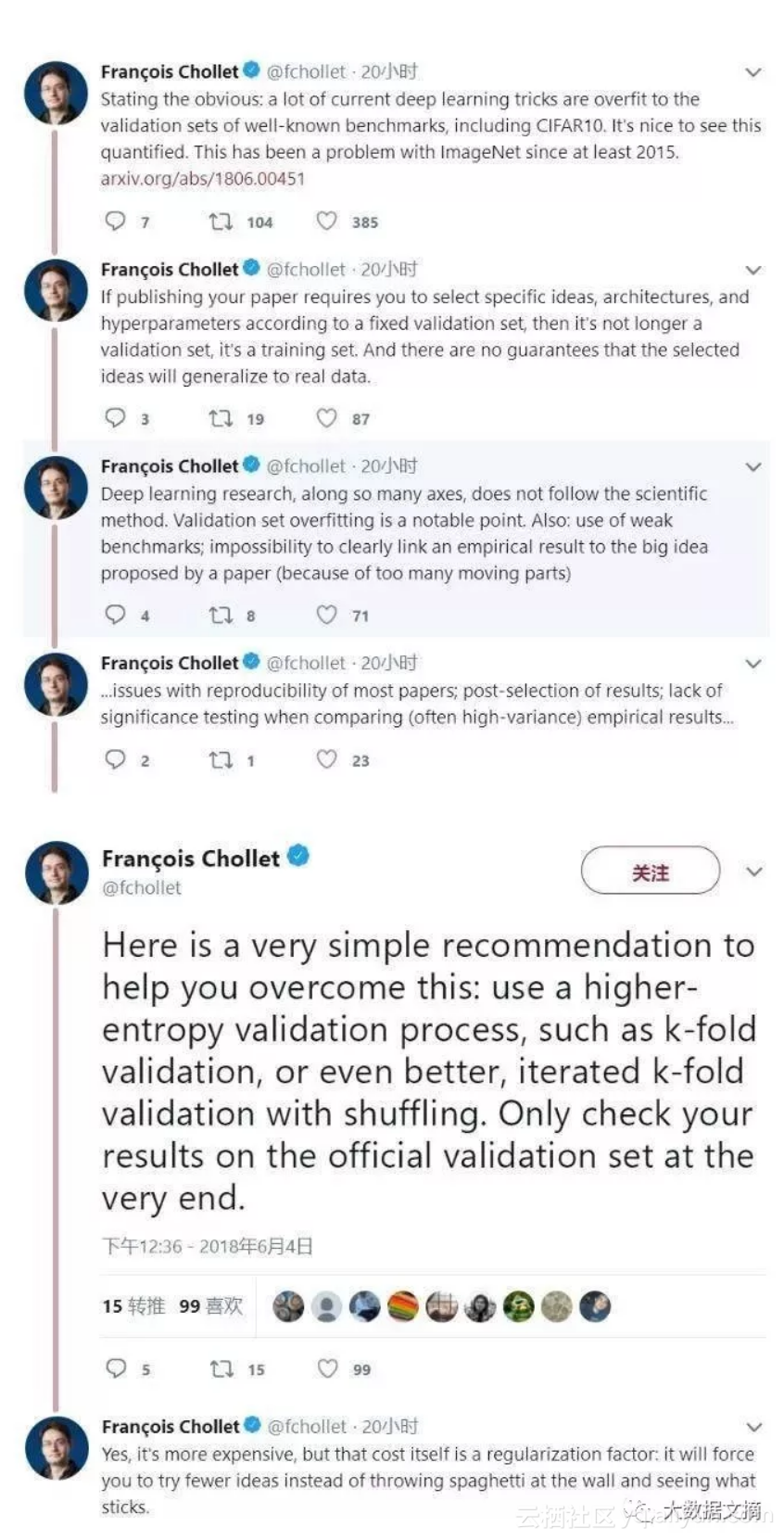
如果为了发论文,针对固定验证集,选择特定的方法、体系结构和超参,那么它就已经不再是验证集,而是训练集,而且不能保证选定方法能推广到真实数据。
很多深度学习研究并未遵循科学方法,验证集过拟合问题不容忽视。另外,使用弱基准测试集,很难将实验结果与论文提出的重大想法建立明确的联系(因为有的太多可变因素)。
同样,想要复现大多数论文中的模型或想法也很困难。例如实验结果的后选择、对比实验结果时缺乏显著性检验等问题。
假如你正在参加Kaggle比赛,如果你使用从训练集(包括public leaderboard)分离出来的固定验证集来评估你的模型/想法,那么你的模型在private leaderboard上的表现肯定很一般。学术研究同样如此。
François Chollet还提出了克服该问题的一个简单建议:用高熵验证过程(如k-fold验证),用带shuffling的递归k-fold验证更好。并且只在最终官方验证集上检验结果。
的确成本更高了,不过成本也是正则化项,迫使你尝试更少更明智的方法。
同时,François Chollet对前段时间引起轩然大波的文章,计算机视觉和 AI 领域专家 Filip Piekniewski的文章《AI Winter Is Well On Its Way》也发表了自己的见解:
自动驾驶汽车是一个很好的例子,因为在这种情况下,存在两种相互竞争的方法:一种是符号方法,另一种是深入学习方法,即通过端到端的学习。其中一种方法会到达L4,在一定程度上甚至会达到L5,另一种却永远达不到。
这并不是说深度学习本质上无法与无人驾驶相融合,而是因为状态空间维度极高,深度学习系统需要在系统运行的同一维度的密度抽样中进行训练。
由于这种具有代表性的密度抽样是不可取的,即使在大量利用模拟环境的情况下,符号方法也将占上风,具体来说,虽然这种方法大多是抽象性的,但却将人类抽象概念与学习的感知基元结合了起来。
让我们用François Chollet的一段话做结:
与大多数事物一样,科学也是一种不精确的艺术,一种靠知识创造的艺术。就像所有的艺术一样,它有我们应该遵循的精确规则。这些规则很容易被破坏,但你破坏的规则越多,你的努力也就越低效。(Science, like most thing, is an inexact art. The art of knowledge creation. And like any art, it has precise rules that one should follow. Any of these rules may be broken, but the more of them you break, the less effective your effort.)
原文发布时间为:2018-06-6
本文作者:文摘菌

