之前写了一篇文章《Weex 框架中 JS Framework 的结构》概述了 JS Framework 的整体结构,其中编译过程写的有些简略,这里再详细介绍一下。
一句话概括 JS Framework 的编译过程就是: 将 JS Bundle 转换成 Virtual DOM 发送到原生模块渲染。
这个过程涉及三种数据类型:JS Bundle 、Virtual DOM 、Vm 。
-
JS Bundle是由.we文件转换过来的,会被视为代码而执行。 -
Virtual DOM是描述页面结构的 JSON 数据,用于给原生模块发送消息。 -
Vm是 View Model 的简写,属于 MVVM 结构中的一部分,会执行模板编译、数据绑定等操作。
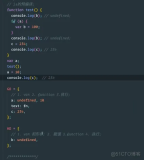
简化版的 Vm 构造函数如下:
// html5/default/vm/index.js
function Vm() {
// ...
// 初始化生命周期
initEvents(this, externalEvents)
this.$emit('hook:init')
// ...
// 监听 data 中的数据
initState(this)
this.$emit('hook:created')
// ...
// 启动模板编译
build(this)
}在 Vm 构造函数最后调用 build 函数启动模板的编译,是一种尾递归,便于 js 引擎优化。
整体编译流程
在调用 build 触发编译后,真正实现编译功能的是 compile 方法(代码位置在 html5/default/vm/compiler.js 中)。build 方法并不递归,它做的只是根据配置项选择合适的参数,然后调用 compile 方法。
compile 方法
compile 接受四个参数:
-
vm: 待编译的 Vm 对象。 -
target: 需要编译的节点,是模板中的标签经过 transformer 转换后的结构。 -
dest: 当前节点父节点的 Virtual DOM。 -
meta: 元数据,在内部调用时可以用来传递数据。
在 compile 函数的最后,会调用 compileNativeComponent 编译生成原生组件,除了它和 createBlock 两个方法以外,其他都是会触发递归的。
分发编译逻辑

compile 函数内部并没有渲染逻辑,他只是将不同类型的节点交给不同的函数来编译;换句话说说,它是负责逻辑的分发和实现递归的。同样职责的函数还有 compileChildren ,他会对每个子节点(模板中的子标签)调用 compile。 compileFragment 方法可以编译数组,其中每个数据项都会调用 compile 方法,但是会共用一个 Block。
创建 Block
在上述的方法中,createBlock 是实际的创建节点的操作,可以视为递归的终止条件。创建的 block 是封装后的 Virtual DOM 节点,结构如下:
{
blockId,
start, // 节点的起点位置,Comment 节点,在当前元素的前一个位置
element, // 实际的节点元素,Element 节点
end, // 节点的结束位置,Comment 节点,在当前元素的后一个位置
}这样做的目的一方面是将 Element 和 Fragment 操作统一化,另一方面是为了 UI 更新时能够快速定位到节点。
编译指令
Weex 的模板标签上支持使用指令,最基本的是 if 和 repeat 指令,详细用法参考官方文档。
if 指令
if 指令可以控制节点的显示和隐藏,用法如下:
<text if={{visible}}>Show something here.</text>这段模板会被 transformer 转换成下面这种结构:
{
"type": "text",
"shown": function () { return this.visible }
}编译 if 指令时,先会创建一个 Block,然后创建 Watcher 执行数据绑定。当 this.visible 发生变化时,会更新视图,若 shown 函数返回为真,则会调用 compile 方法重新编译节点,否则会调用 removeTarget 将节点从父节点中删除。
repeat 指令
repeat 指令可以根据模板循环渲染数组中的所有数据。假设有如下某个 .we 文件:
<script>
module.exports = {
data: {
images: [
{ source: 'somewhere/a.png' },
{ source: 'somewhere/b.png' },
{ source: 'somewhere/c.png' }
]
}
}
</script>
<template>
<list>
<cell repeat={{images}}>
<image src="{{source}}"></image>
</cell>
</list>
</template>编译生成的结果如下:
{
"type": "list",
"children": [
{
"type": "cell",
"append": "tree",
"repeat": function () { return this.images },
"children": [
{
"type": "image",
"attr": {
"src": function () { return this.source }
}
}
]
}
]
}遇到 repeat 指令时,会调用 compileRepeat 方法,它先整理好数据,然后调用 bindRepeat 执行编译。编译过程中会将 repeat 指令所在的节点视为模板,循环展开对应的数据,逐条调用 compileItem 渲染每个节点。期间也会添加数据绑定,当数组中的数据有变化时,会自动更新 List。
append 属性
如果仔细看一下上面 repeat 指令转换出来的代码,会发现 cell 节点上有一个 append 属性,这个属性在官方文档中写的比较详细了,它是用来控制渲染次序的,属于比较底层的属性,在内部指令中用到了,开发者通常不会用到。这里再总结一下:
-
append="tree"会先编译子节点,再编译自身。编译速度快,但是容易造成较长时间的白屏。 -
append="node"会先编译自身,再编译子节点。整体编译速度略慢,但是用户体验好一些。 - 默认的编译方式是
node,先创建容器,再创建内容。
不过 repeat 指令默认的编译方式是 tree;由于内容可变,它是先编译生成所有子节点,然后再编译自身,避免频繁地插入操作,这种编译方式也比较符合列表的特性。
编译组件
除了内置标签以外,Weex 还支持自定义的组件(标签),这是最基本也是最好用特性了。
编译自定义的组件
每个组件(.we 文件)都对应的是一个 Vm 实例,当编译过程中遇到某标签不是内置标签而是一个自定义的组件时,会创建一个新的 Vm 实例,合并父子组件中添加的样式,同时也添加了生命周期的钩子:
-
init: 设置子组件 id。 -
created:bindSubVm合并父子组件中定义的属性。 -
ready: 调用compileChildren开始编译子组件中的节点。
值得注意的是,创建新的 Vm,又会执行本文从开头开始讲的所有步骤:初始化数据、数据绑定、递归编译各种节点…… 所以说整个编译过程包含了大量的递归,函数调用栈比较深,会消耗大量的内存和时间。
编译生成原生组件
在 compile 函数结尾会调用 compileNativeComponent 绘制原生组件,也就是说,原生组件的绘制是在递归编译过程中进行的,不需要等待完整的 Virtual DOM tree 拼好之后再绘制原生 UI,页面可以实现流式渲染,持续不断的渲染碎片化的 Virtual DOM。
compile 的各种流程产出的是 Virtal DOM,而 compileNativeComponent 实现的是将碎片化的 Virtual DOM 通过 callNative 发送渲染指令给原生模块,通知其绘制 Native UI。原生模块在绘制 UI 的过程中,如果发生了错误,会返回 -1 存放在 app.lastSignal 中,此时 JS Framework 会终止编译。
结语
接前一篇讲 JS Framework 的文章,这篇文章详细介绍了组件的编译流程,涉及很多技术细节,这些细节有可能在以后的版本中有改动。了解 JS Framework 的实现细节,有助于开发者在使用时能避开不恰当的用法,少踩一些坑,希望这篇文章能对大家有所帮助,如果有疑问或者有不同看法,欢迎来找我探讨。