直播视频:点此进入
PDF 下载: 点此进入以下为演讲内容整理:
什么是OceanBase
OceanBase是在2010年6月份开始立项的,OceanBase不是NoSQL系统,它是结合传统关系型数据库功能上的优点和分布式系统在可扩展性、可靠性上的优点打造的一款分布式关系型数据库。OceanBase支持完整的ACID,可扩展、高可用,兼容MySQL协议。
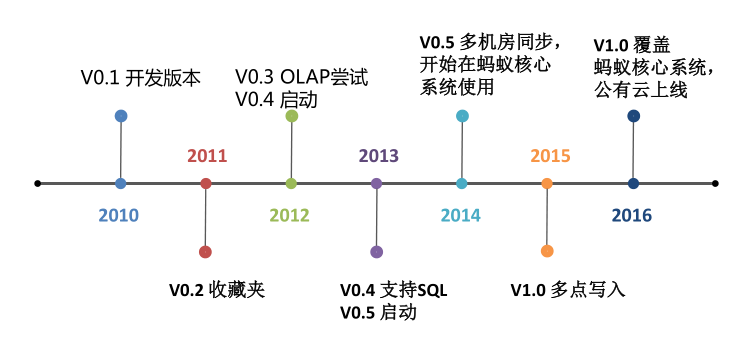
OceanBase的发展历程
互联网对传统关系型数据库的挑战
可扩展性
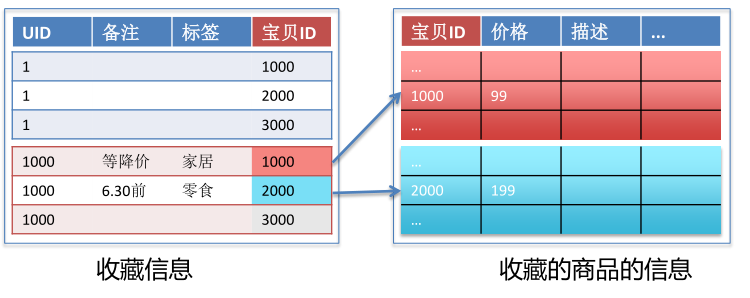
传统关系数据库本质上是单机数据库,当你的性能或容量不足时,需要换一台更大的机器,我们是一直向上扩展。想要水平扩展需通过读写分离 & 分库分表来解决,这也极大的增加了应用层的复杂度。以图中收藏夹业务为例,收藏一个商品称为收藏信息,包括收藏本身和收藏商品的信息,收藏的商品信息是变化的,商品降价需要在用户收藏夹里体现出来,收藏信息只能按用户区分,商品只能按商品ID区分,当一个用户收藏了多个表的商品时,需要在中间件层完成join操作,这样会加大业务的负担,相当于在中间件层或业务层完成了数据库本该完成的工作。
可靠性
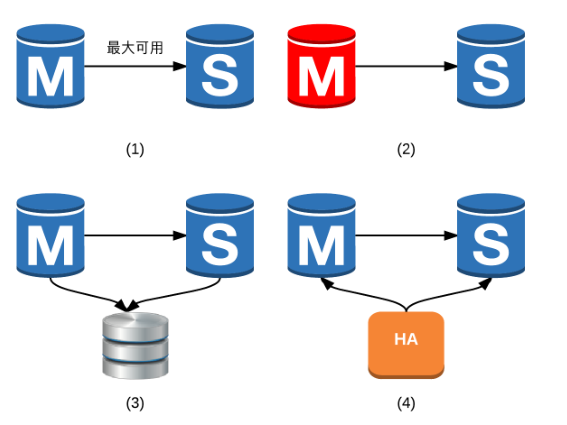
传统关系型数据库本质上是一个单机系统,主备间是需要进行数据同步的,数据同步有三种模式:最大可用模式、最大保护模式、最大性能模式。最大保护模式要求主库和备库都写成功后才会应答客户,一旦网络抖动或者备机宕机等,整个服务就中断了,互联网行业中用这种模式比较少。最大可用模式要求主库写成功后就立即应答客户,然后把数据异步同步给备库,一旦主库宕机,极有可能造成数据不一致的情况,为了解决数据不一致的问题,一般会加共享存储等保证可靠性;主备机无法决策出谁是主谁是备,如果主机宕机,备机无法自己切换成主机,需要通过第三方组件切换。
OceanBase的目标
在使用普通PC服务器,不使用共享存储、小型机等昂贵硬件,以及服务器、磁盘、网络、机房(IDC)等并非持续可用的情况下,OceanBase的目标是:
首先要保证关系型数据库的功能、支持跨表跨行事务,其次要保证数据可以分布式水平扩展,对应用透明,另外,数据库要高可靠、数据强一致,可抵御单机、机架、机房(IDC)故障,且高性能。
OceanBase主要面临的问题
- 数据库的功能:传统关系型数据库发展时间较长,功能丰富
- 分布式一致性:分布式系统的多副本如何保持一致性;最终一致性、弱一致性不符合用户需求
- 分布式事务:理论成熟,工程与性能上的优化
数据库数据总量非常大,但增删改量很少。
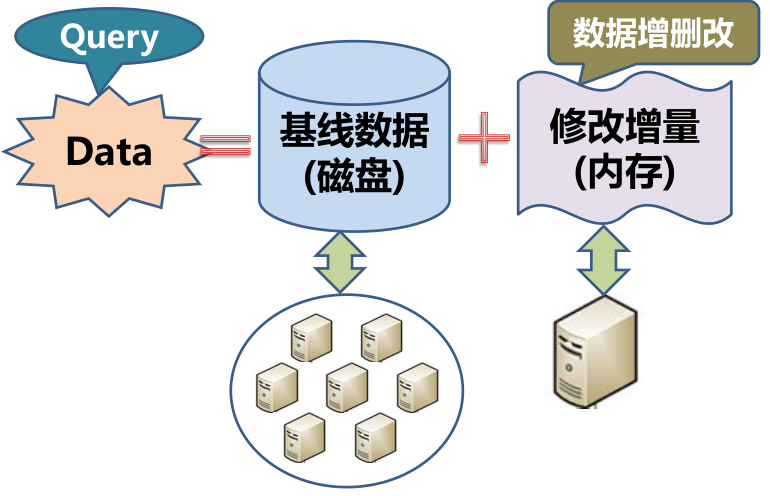
我们设计了如图架构,把数据分成两个部分,一部分为基线数据,另一部分为增量数据。每次的修改我们就放到一个单机的内存中,基线数据拆分到多个机器上,这样就避免了分布一致性的问题。
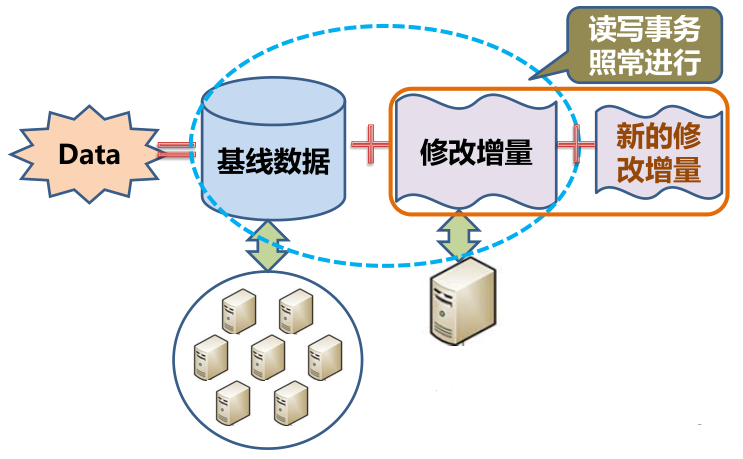
增量数据不可能永远放在内存中,所以内存写到一定程度后会做每日合并,合并会在数据库每天的访问低谷时进行,对业务没有影响。
最初版本V0.2
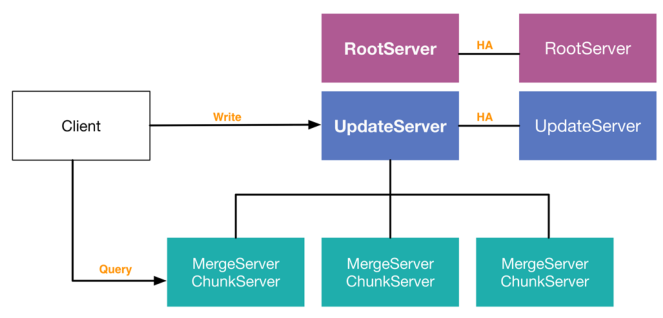
- 存在两个单点RootServer和UpdateServer,通过HA(http://linux-ha.org/)来实现高可用
- 基线数据节点可任意扩展
- 写节点半同步,不能区分insert / update
V0.2相对较原始,我们的客户端代码由业务同学来写,我们的更新直接会到UpdateServer端,不能区分insert / update,这样解决了收藏夹的一个业务痛点(通过数据冗余+Join更新信息消灭随机读/写)。
V0.3 多IDC & OLAP
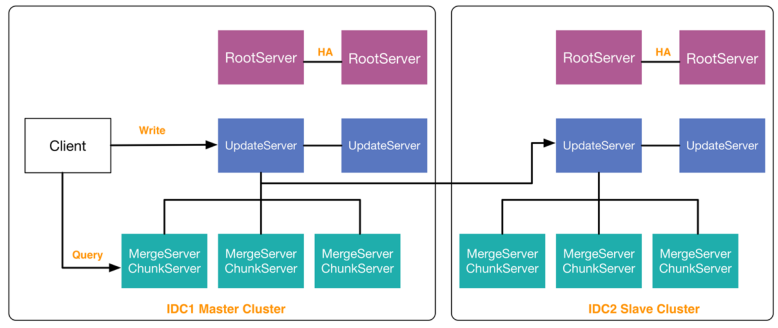
- 相比于V0.2不同的是,V0.3去除UpdateServer的HA,改由RootServer来决定谁是Master
- 支持多IDC部署、但IDC切换需要人工介入
- 在查询层面对并发作了优化,可满足轻量级的OLAP
V0.3绑定的业务是广告报表,主要是把数据在离线的平台计算好后导到关系数据库中,实现数据分块、并发查询,旁路导入数据。V0.3达到了千亿条记录和百T规模数据,但客户端的表现力差。
V0.4 支持SQL
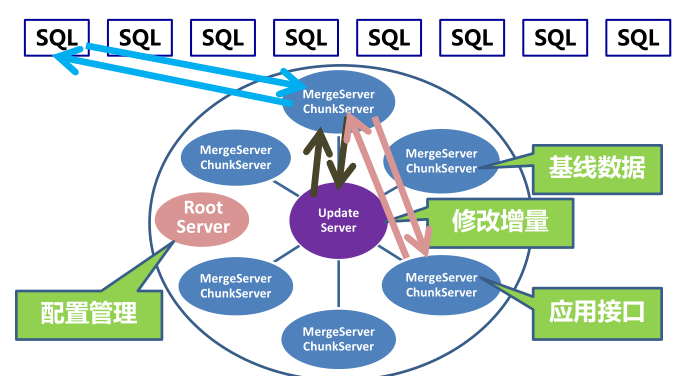
V0.4支持SQL,并不是单纯改一个接口那么简单,我们在数据库功能方面迈出了一步。V0.4兼容MySQL协议,区分update/insert,支持并发更新。
V0.4去除自定义协议的客户端,没有特别多的核心业务,主要是历史库、结构化Key/Value类型的非核心业务,我们也对外开源,并开始核心业务的尝试。
V0.5 多机房同步
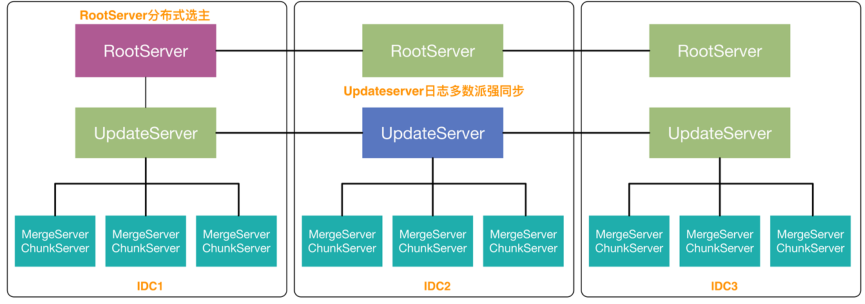
- RootServer分布式选主,不再依赖HA
- 多机房部署,少数派机房故障自动容灾,数据不丢失
- 覆盖蚂蚁多个核心系统
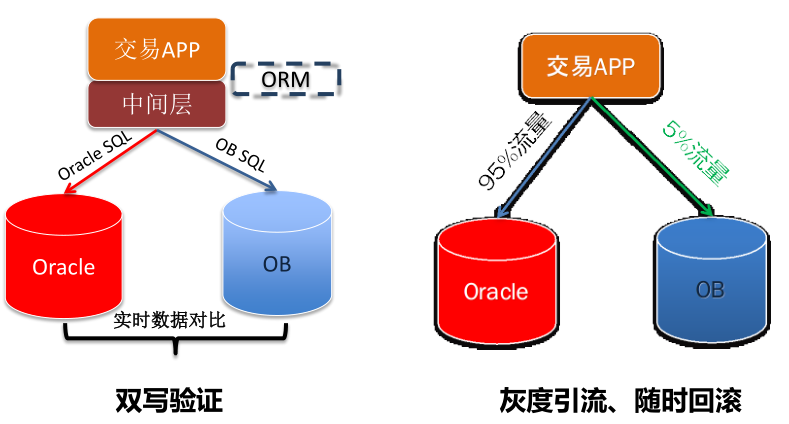
在迁入核心业务系统时,我们也积累了经验,形成一套模板。比如最开始上线的蚂蚁交易核心系统;当年双11承担20%的流量;2015完成支付在内的多个核心系统迁移;第一个支撑的银行的非商业数据库。我们积累了一整套迁移方法,比如用蚂蚁中间层向应用屏蔽掉了SQL的差异,中间层通过访问数据的类型去调用不同的模板,灰度引流,随时回滚,我们称蚂蚁为流水型的系统。
回过头考虑0.5之前的架构,得出单UpdateServer的意义手至关重大的,极大简化实现,避免分布式事务,具有较简单的数据模型。当然在集群规模、数据导入上也有诸多限制。
V1.0
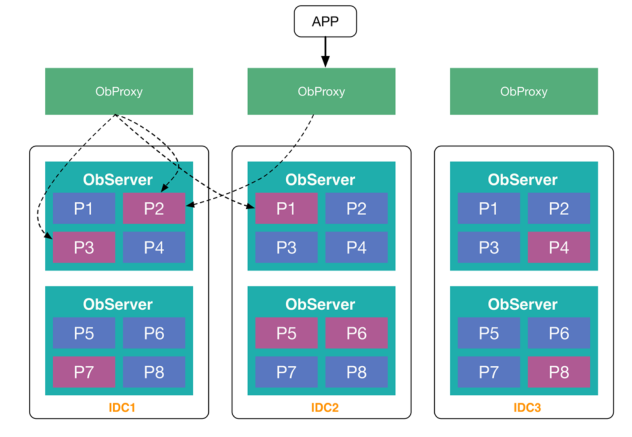
V1.0变更了数据模型,我们把数据分布引入了传统观念数据库的分区表,交给用户来定义,根据业务特点可能把数据分成一片一片,这时,我们把四种角色都合并到一个角色中,称为ObServer。每个ObServer是对等的,它可以负责一个分区或者多个分区的数据,每个分区会部署在3个机房,这三个副本之间会自行通过分布式选举,选举出一个组来提供服务,此时我们具备很高的灵活性,用户可以根据业务逻辑来分区。
同步机制
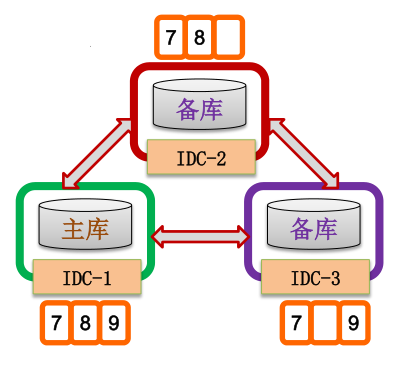
主库执行写事务并同步到备库,超过半数成功则事务成功。
错峰合并
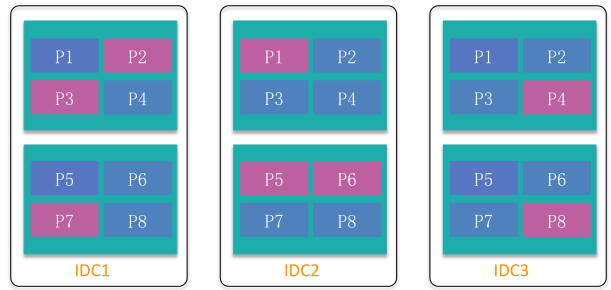
- 逐IDC合并,灰度引流,缓存预热,对用户没有影响
- 同样的用在升级流程上,往往是在备库升级好,再切到主库中
OceanBase有着天然的优势,无论是在版本升级还是维护,都可以应用到这套机制,整个维护或者故障都可以做到对用户透明,用户感知不到变化。
降低每日合并耗时
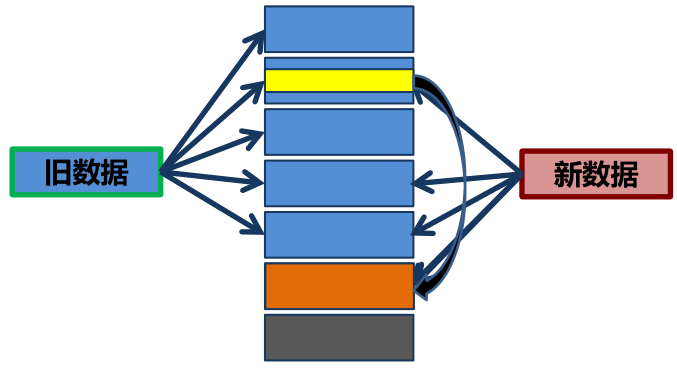
最开始数据分布采用范围分布,一条记录修改,整个数据重写。我们在每日合并上也做了优化,采用了更细粒度的分片,把数据分块,如果某块数据发生更改,只对这条数据进行重写即可。
云数据库OceanBase
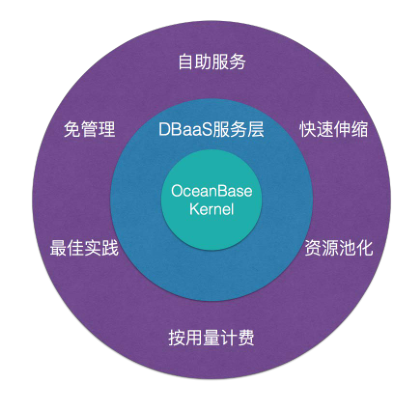
云数据库OceanBase是一款阿里巴巴自主研发的高性能、分布式的关系型数据库,支持完整的ACID特性。它高度兼容MySQL协议与语法,让用户能够以最小的迁移成本使用高性能、可扩展、持续可用的分布式数据库服务,同时对用户数据提供金融级可靠性的保障。云数据库OceanBase相对于传统数据库的特点如下:
- 基于OceanBase的DBaaS:提供自助化服务,一键即可拥有OceanBase实例;免管理;提供使用建议
- 在蚂蚁和集团长期使用,原生态输出
- 具备输出到专有云的能力:网商银行
总的来说,云数据库OceanBase具备多可用区部署,与内部最新版本保持同步,以及生态支持和集群共享模式、无缝动态伸缩、即时生效。
未来发展
- OceanBase目前仍然在快速迭代
- 灰度升级对应用透明
- 让数据库的归数据库,一切以简化用户使用为目标
未来OceanBase主要应考虑以下几个方面:
完善功能:以业务需求驱动,业务不符合什么功能我们就做什么功能;满足内部业务的平滑迁移,完善数据库兼容性问题;OceanBase重点完善支持FlashBack。
历史库:历史库是关系型数据库的一些瓶颈造成的,OLTP系统有典型的冷热数据;为了降低成本等,冷数据需要迁移,OceanBase正在做冷热数据自动识别、异构机型等。
OLTP & OLAP混合负载:OceanBase比较适合OLAP的,OceanBaseK可以做在线数据和离线数据同时进行分析,可以做ObServer内的资源隔离、大查询限流、利用备副本等。
成本:保持高可用的情况下,降低副本数。

