高可用架构
ZSearch是目前公司内最大的Elasticsearch服务平台,随着业务的深入,越来越多的关键链路用户对数据的可用性和容灾能力提出更高的需求,而在这块领域 社区一直没有完整的解决策略,原生的 Snapshot And Restore 只能做快照的恢复,不能做到实时同步;业内主流的队列分发模式(通过消息队列缓存请求数据,多个集群消费数据实现请求复制)也只能做到请求的同步,一个不可预期的操作如delete_by_query 集群间便会产生数据差异。归根到底我们需要一个类似Mysql的binlog同步方案, 从底层机制上保证数据的最终一致性,为此 ZSearch核心团队经过数月源码研究 精心打造了Elasticsearch-XDCR,一款基于translog原生复制协议的跨集群同步产品。
Elasticsearch-XDCR
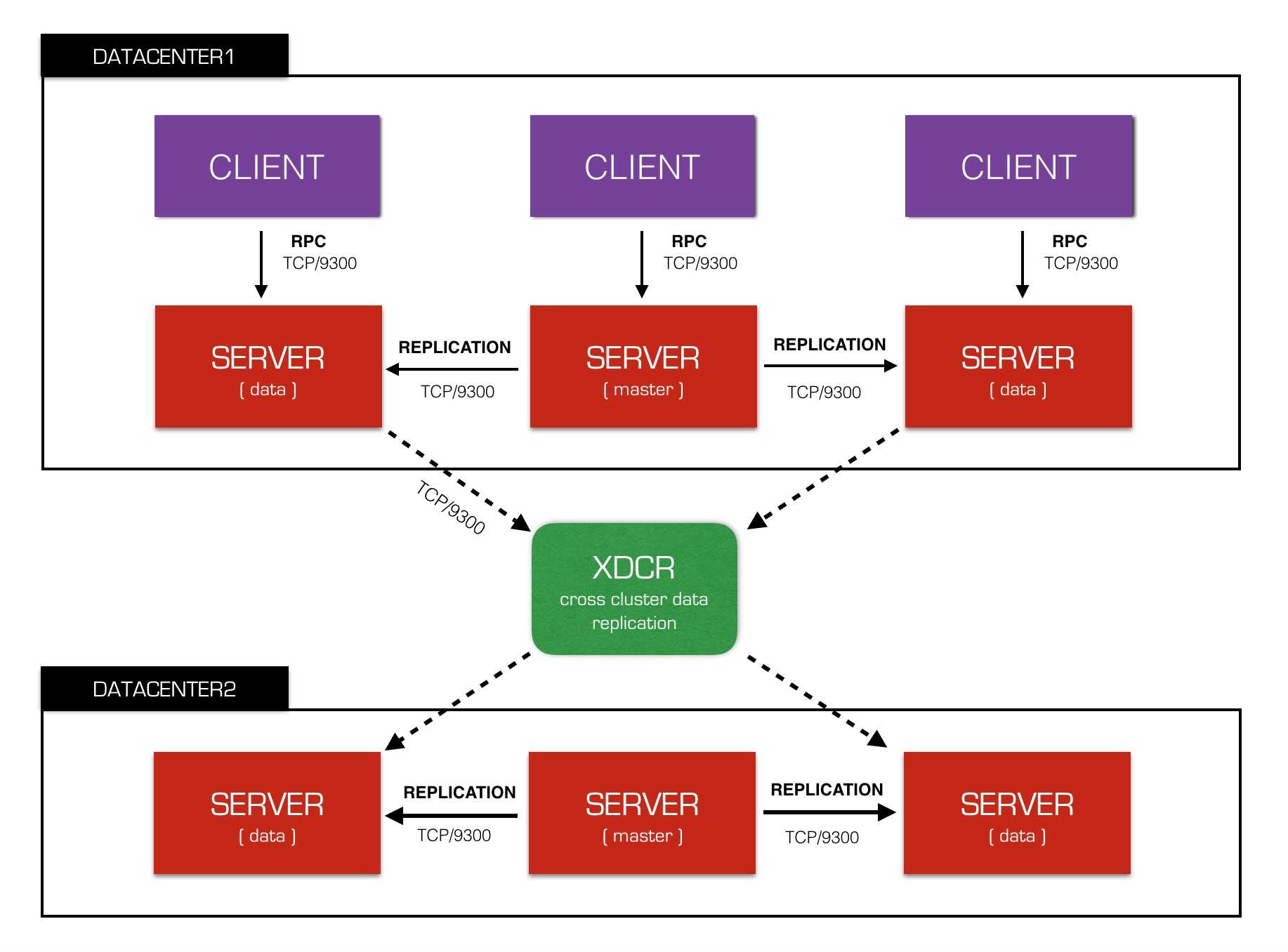
elasticsearch-xdcr 采用插件形式,产品形态上依然保留了ES社区一贯的简单风格。
- 安装简单,只要在两个集群安装插件重启即可。
- 使用简单,两个restful操作完成数据同步。
- 数据一致,基于原生复制协议,支持实时同步。
- 稳定方便,支持mapping自动更新以及断点续传。
使用样例
第一步 在主集群创建备份集群仓库
PUT _xdcr/{cluser_name} -d {
"settings": {
"seeds": [{node_1}, {node_2}, ... ]
}
}第二步 开启索引同步
_xdcr/{cluster_name}/{job_name} -d '
{
"indices": "index_1,index_2 ..."
}
'源码实现
本文将通过Elasticsearch源码分析,结合其原生复制处理过程来讲解xdcr的设计思路,首先我们了解ES的一些基础概念。
- 一份索引(index)可分成多个分片(shard)并分配在不同节点上(node) 。
- 一份shard可由一个主分片(primary)和多个备副本(replica)组成。
- 数据先写到主分片,写入成功则同步到各个备副本上。
elasticsearch-xdcr的实现思路便是分析primary到replica的内部复制处理流程,将复制目标扩展到外部集群达成跨集群数据同步效果。

集群调度模型
- 类似于k8s|hippo,ES的分布式调度模型也采用一种目标式的资源管理方式,即master发布一个全局状态(ClusterState),工作节点共同协作,直到整体集群状态达到一致。
- RoutingTable(路由表)是状态的一个子模块,他管理了所有索引的路由状态,如新建的索引放在那些节点上,某些节点磁盘快满了应该迁移出去等等。
- ShardRouting 是RoutingTable的具体表现,他表示一个分片的路由规则,如分片是否为主分片、放在哪个节点、现在处于什么状态等等。
当我们为一个索引建立一个新的副本,Master节点便会发布一个新的集群状态,被分配的Work节点根据ShardRouting找到主分片位置并建立恢复任务,此过程在ES中被称之为peer_recovery。

核心源码指引: org.elasticsearch.indices.cluster.IndicesClusterStateService
“推模式”索引拷贝流程
了解了总的处理流程,我们可以把关注点聚焦到主-副间的具体恢复流程。ES采用的是一种推模式,主分片在接收到副本节点发来的start_recovery请求,会源源不断的往目标分片推送索引数据,直到全部结束后,备节点将shard更新到可服务状态 完成peer_recovery流程,推的过程分为三个阶段:
- phase1: 同步索引文件,已经构建好的最终索引文件。
- phase2: 同步translog,需要做恢复形成最终索引文件。
- finalize: 同步checkpoint,更新全局提交点,保持和主分片的Sequnce位点同步。
源码及调用关系参照下图

核心源码指引
org.elasticsearch.indices.recovery.*
跨集群改造
ES的原生PeerRecovery过程只能在索引的创建初始化阶段(init),而跨集群方案中外部集群通常已经建好了对等的索引,处于服务状态(started)的shard不允许做任何后台任务。最初的方案我们是想设计一种新的ShardRouting,在索引核心加载层扩展新的Recovery类型支持远程recovery,但这样的改动会侵入到ES core层源码,不利于后续的版本迭代。如果想无侵入以插件形式实现跨集群复制,只能利用二阶段的translog recovery,shard在服务状态translog可伪装成primary操作写入引擎,但是纯translog recovery在速度上远不及索引文件拷贝,经过各种利弊权衡,我们最终还是采用零侵入的translog方式,毕竟不绑架用户的产品更具生命力。
代码片段
Engine.Operation.Origin.PEER_RECOVERY -> Engine.Operation.Origin.PRIMARY
for (Translog.Operation operation : operations) {
Engine.Result result = shard.applyTranslogOperation(operation, Engine.Operation.Origin.PRIMARY, update -> {
mappingUpdater.updateMappings(update, shard.shardId(), ((Translog.Index) operation).type());
throw new ReplicationOperation.RetryOnPrimaryException(shard.shardId(), "Mapping updated");
});
}SequnceNumber & 断点续传
ES 6.0之后引入了一个非常重要的特性 SequnceNumber,shard上任何类型的写操作,包括index、create、update和delete,都会生成一个连续递增的_seq_no。这使得Node异常或重启时,能够从最后的位点(checkpoint)快速恢复,这个特性同样也使的跨集群复制具备了第二个重要条件 - 断点续传 。利用该特性,在多机房容场景抵御各种不可预知的问题,如网络抖动、网络故障、集群宕机等等,恢复后的recovery流依然可以通过seqNo快速恢复。
代码片段
Translog.Snapshot snapshot = translog.newSnapshotFromMinSeqNo(startingSeqNo);结尾
由于篇幅有限,本文介绍了实现ES跨集群同步的两个重要条件和实现思路,后期可结合思路详细讲解实现的过程。




