主成分分析(PCA:Principal Component Analysis)非常有助于我们理解高维数据,我利用Stack Overflow的每日访问数据对主成分分析进行了实践和探索,你可以在rstudio :: conf 2018上找到其中一篇演讲的录音。演讲的重点主要是我对于PCA的理解,而这篇文章中,我将主要介绍我是如何实现PCA的,以及我是如何制作演讲中使用到的图表的。
rstudio :: conf 2018
https://www.rstudio.com/resources/videos/understanding-pca-using-shiny-and-stack-overflow-data/
高维数据
此次分析使用的是去年Stack Overflow上注册用户访问量前500的标签数据。为了简化处理,本文只使用了10%的注册流量数据进行分析,但实际上我已经对所有流量数据进行了类似的分析,并获得了几乎相同的结果。
标签数据
https://stackoverflow.com/tags
现在,把每个注册用户都想象成高维空间中的一个点,空间的坐标轴是R、JavaScript、C++等技术。那么,在这个高维空间中,做相似工作的人对应的点就会彼此接近。接下来PCA会把这个高维空间转变成一个新的具有特殊特征的“特殊”高维空间。
在数据库中适当地抽取数据后,最开始的数据看起来就像下面这样:
library(tidyverse)
library(scales)
tag_percents
## # A tibble:
28
,
791
,
663
x
3
## User Tag Value
## <
int
> <chr> <dbl>
##
1
1
exception-handling
0.000948
##
2
1
jsp
0.000948
##
3
1
merge
0.00284
##
4
1
casting
0.00569
##
5
1
io
0.000948
##
6
1
twitter-bootstrap
-3
0.00569
##
7
1
sorting
0.00474
##
8
1
mysql
0.000948
##
9
1
svg
0.000948
##
10
1
model-view-controller
0.000948
## # ... with
28
,
791
,
653
more rows
可以看出,数据很干净,每行只有用户编号和技术标签。这里的User列是随机ID,而非Stack Overflow的标识符。在Stack Overflow中,我们公开了大量数据,但流量数据(即哪些用户访问过哪些问题)是没有公开的。
对高维数据进行真正的匿名化其实是非常困难的,而这里为了进行脱敏处理,我的做法是随机化数据顺序,并用数字替换Stack Overflow的标识符。Value列表示过去一年该用户对该标签的浏览量占该标签总浏览量的比例。
部分数据链接:
https://stackoverflow.blog/2010/06/13/introducing-stack-exchange-data-explorer/
https://cloud.google.com/bigquery/public-data/stackoverflow,
https://meta.stackexchange.com/questions/19579/where-are-the-stack-exchange-data-dumps
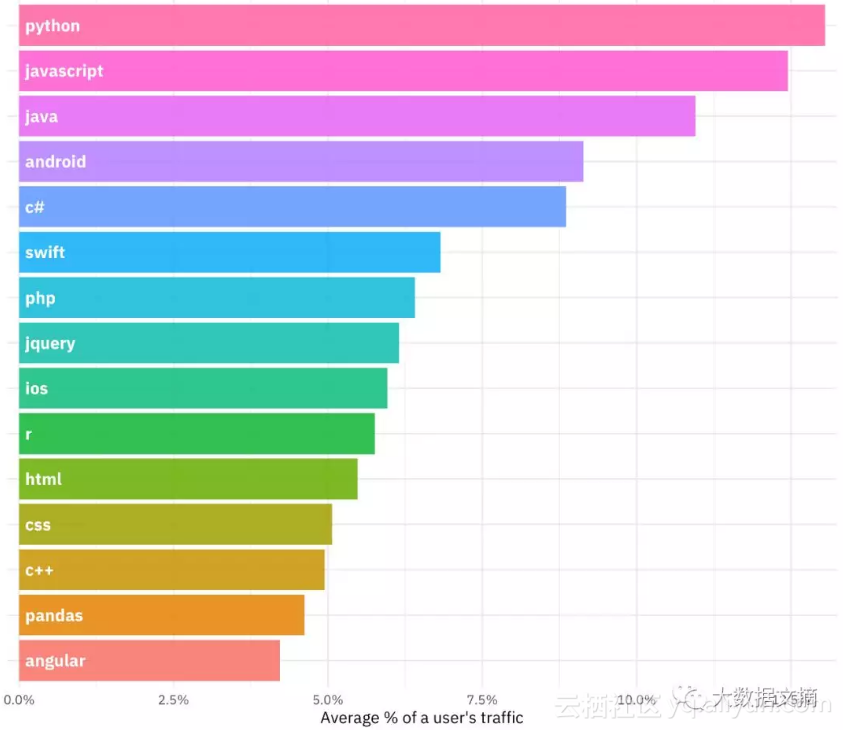
先不考虑脱敏的问题,我们首先看看用户主要浏览的技术标签有哪些,这张图表给了我们一个直观的概念。.
tag_percents %>%
group_by(Tag) %>%
summarise(Value = mean(Value)) %>%
arrange(desc(Value)) %>%
top_n(
15
) %>%
mutate(Tag = reorder(Tag, Value)) %>%
ggplot(aes(Tag, Value, label = Tag, fill = Tag)) +
geom_col(alpha =
0.9
, show.legend = FALSE) +
geom_text(aes(Tag,
0.001
), hjust =
0
,
color =
"white"
, size =
4
, family =
"IBMPlexSans-Bold"
) +
coord_flip() +
labs
(x =
NULL
, y =
"Average % of a user's traffic"
) +
scale_y_continuous(labels = percent_format(), expand = c(
0.015
,
0
)) +
theme(axis.text.y=element_blank())
实施PCA
我们喜欢干净的数据,一是因为它就是我们查询数据库的结果,二是因为它可用于实现PCA等机器学习算法的探索性数据分析。为了实现PCA,我们需要一个矩阵,在这个例子里稀疏矩阵(sparse matrix)就是最佳选择——因为大多数开发人员只访问一小部分技术标签,因此我们的矩阵中会有很多零。tidytext软件包中有一个函数cast_sparse(),它可以把上面的数据转换为稀疏矩阵。
sparse_tag_matrix <- tag_percents %>%
tidytext::cast_sparse(User, Tag, Value)
R中有几个实现PCA的算法是体会不到稀疏矩阵的美感的,比如prcomp()——此算法的第一步就是将刚刚制作好的稀疏矩阵强制转换成一个常规矩阵,然后你要在那里干坐一辈子等它运行完,因为在它运行的时候电脑根本没有内存让你去做其他事了(别问我是怎么知道的)。当然,R中也有一个程序包利用了稀疏矩阵的优势——irlba。
在建立模型前,也别忘记先用scale()函数将你的矩阵规范化,这对于PCA的实现非常重要。
tags_scaled <- scale(sparse_tag_matrix)
tags_pca <- irlba::prcomp_irlba(tags_scaled, n =
64
)
其中prcomp_irlba()函数的参数n代表我们想要得到的主成分个数。
那么这一步究竟发生了什么?我们会在接下来的章节中慢慢介绍。
class
(tags_pca)
## [
1
]
"irlba_prcomp"
"prcomp"
names(tags_pca)
## [
1
]
"scale"
"totalvar"
"sdev"
"rotation"
"center"
"x"
PCA的结果分析
我喜欢处理数据框格式的数据,所以接下来我要用tidy()函数来整理我的PCA结果,以便用dplyr包处理输出结果和用ggplot2绘图。 broom包并不能完美地处理irlba的输出结果,所以我会将它们与我自己的数据框经过一点修整后合并到一起。
library(broom)
tidied_pca <- bind_cols(Tag = colnames(tags_scaled),
tidy(tags_pca$rotation)) %>%
gather(PC, Contribution, PC1:PC64)
tidied_pca
## # A tibble:
39
,
232
x
3
## Tag PC Contribution
## <chr> <chr> <dbl>
##
1
exception-handling PC1
-0.0512
##
2
jsp PC1
0.00767
##
3
merge PC1
-0.0343
##
4
casting PC1
-0.0609
##
5
io PC1
-0.0804
##
6
twitter-bootstrap
-3
PC1
0.0855
##
7
sorting PC1
-0.0491
##
8
mysql PC1
0.0444
##
9
svg PC1
0.0409
##
10
model-view-controller PC1
0.0398
## # ... with
39
,
222
more rows
注意到这里我的数据框的每一行只有一个技术标签及它构成的主成分。
那么从整体来看,这些结果又是什么样子的呢?请见下图:
tidied_pca %>%
filter(PC %in% paste0(
"PC"
,
1
:
6
)) %>%
ggplot(aes(Tag, Contribution, fill = Tag)) +
geom_col(show.legend = FALSE, alpha =
0.8
) +
theme(axis.text.x = element_blank(),
axis.ticks.x = element_blank(),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank()) +
labs
(x =
"Stack Overflow tags"
,
y =
"Relative importance in each principal component"
) +
facet_wrap(~ PC, ncol =
2
)
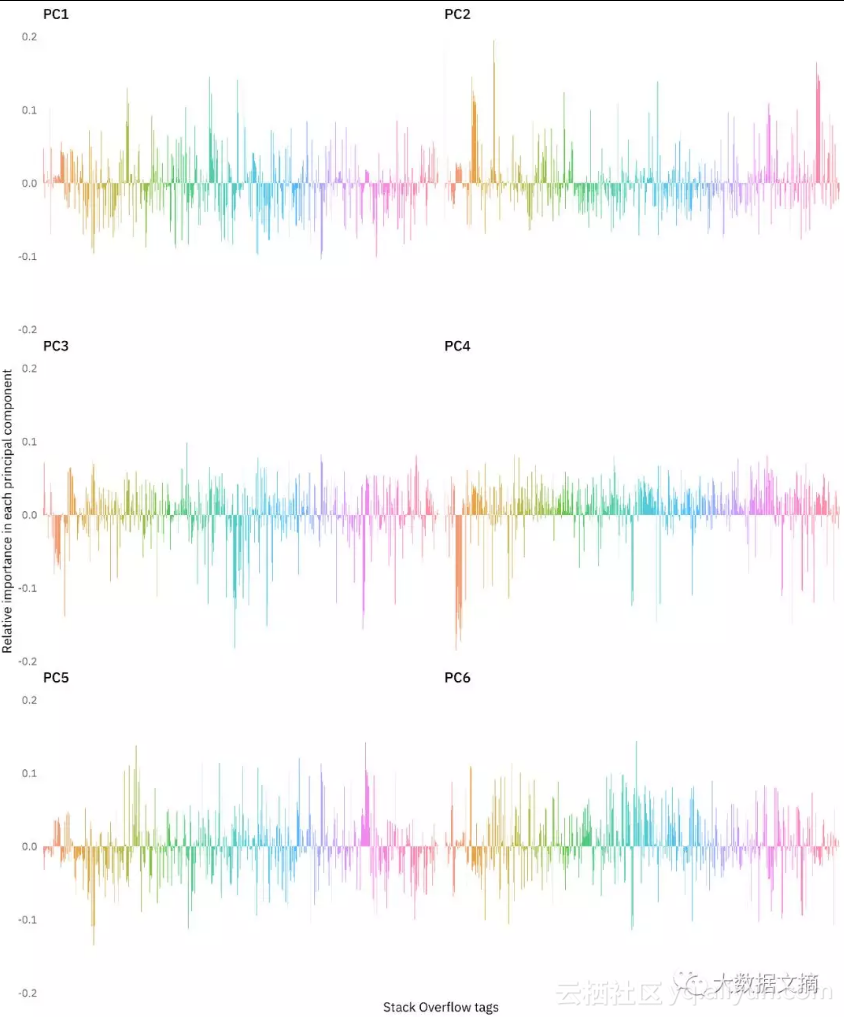
很漂亮吧有木有!我们上面看的是前六个主成分,图中x轴上是按字母顺序排列的单个Stack Overflow标签,纵轴表示该技术标签对这一PC的贡献度。我们也可以看出有关联的技术可能是以相同的字母开头,故而会排列在一起,例如PC4中的橙色等。
下面让我们主要分析一下第一个主成分的构成。
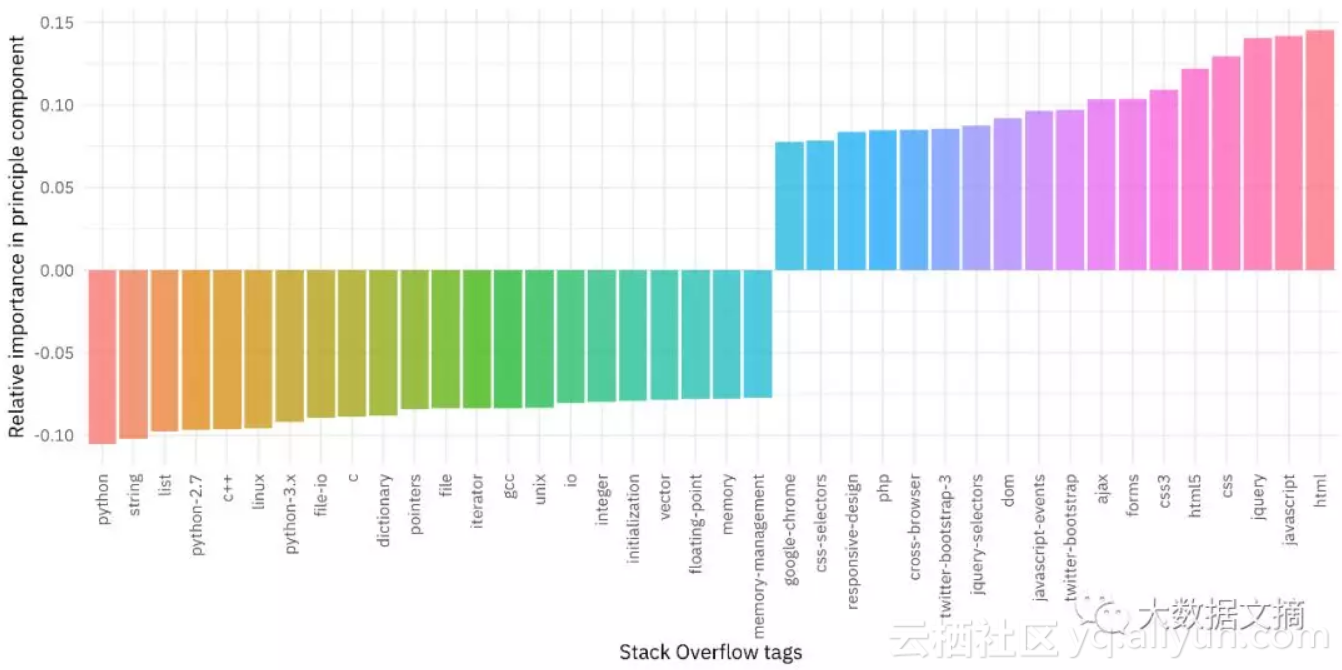
tidied_pca %>%
filter(PC ==
"PC1"
) %>%
top_n(
40
,
abs
(Contribution)) %>%
mutate(Tag = reorder(Tag, Contribution)) %>%
ggplot(aes(Tag, Contribution, fill = Tag)) +
geom_col(show.legend = FALSE, alpha =
0.8
) +
theme(axis.text.x = element_text(angle =
90
, hjust =
1
, vjust =
0.5
),
xis.ticks.x = element_blank()) +
labs
(x =
"Stack Overflow tags"
,
y =
"Relative importance in principle component"
)
现在我们可以看到哪些技术标签对这个成分有贡献。从贡献为正的标签来看,主要有前端Web开发技术,如HTML、JavaScript、jQuery、CSS等。从贡献为负的标签来看,主要有Python,C ++以及低级技术词汇,如字符串(strings)、列表(lists)等。这意味着Stack Overflow的用户之间最大的差异在于他们是使用前端Web技术更多一些还是Python和一些低级技术更多一些。
那么第二个主成分又是怎样的呢?
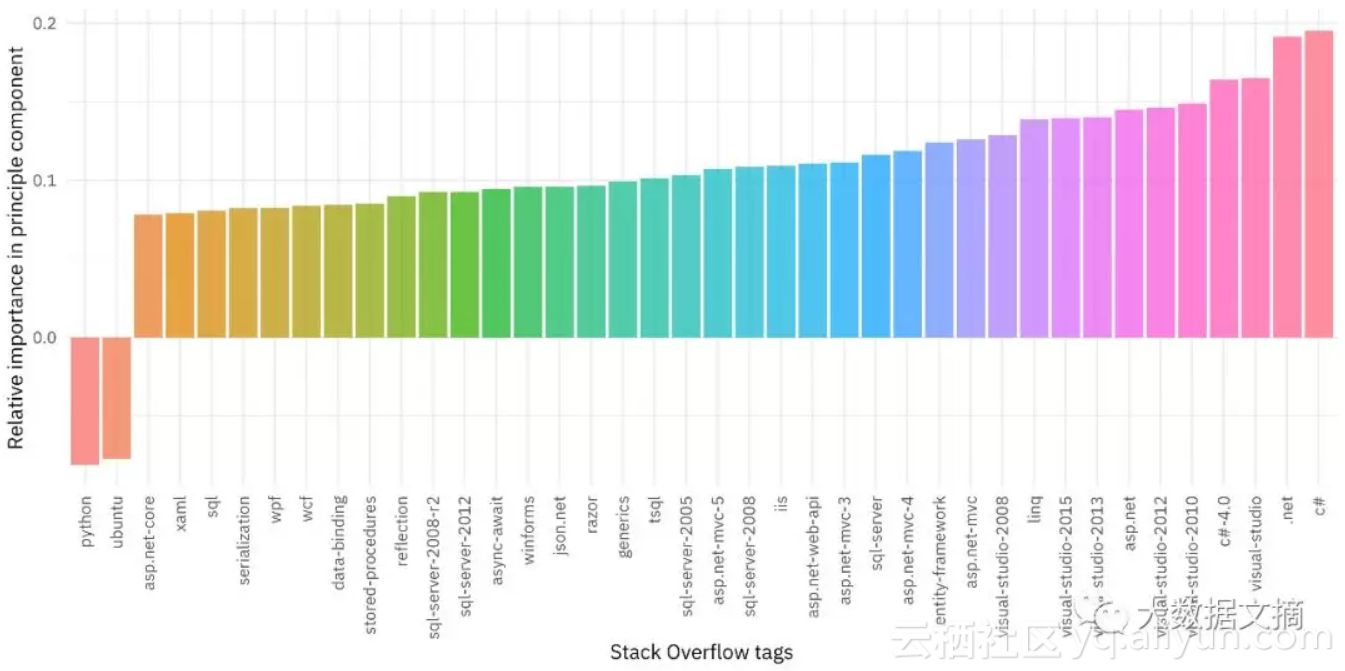
tidied_pca %>%
filter(PC ==
"PC2"
) %>%
top_n(
40
,
abs
(Contribution)) %>%
mutate(Tag = reorder(Tag, Contribution)) %>%
ggplot(aes(Tag, Contribution, fill = Tag)) +
geom_col(show.legend = FALSE, alpha =
0.8
) +
theme(axis.text.x = element_text(angle =
90
, hjust =
1
, vjust =
0.5
),
axis.ticks.x = element_blank()) +
labs
(x =
"Stack Overflow tags"
,
y =
"Relative importance in principle component"
)
第一个主成分是两种软件工程的对比,但第二个主成分则更像是一个结果为是/否的二分类变量。它告诉了我们开发人员工作中是否使用C#、.NET、Visual Studio和Microsoft技术堆栈的其余部分。这意味着Stack Overflow的用户之间的第二大差异在于他们是否访问了这些类型的微软技术问题。
我们可以继续研究其他的主成分,了解更多关于Stack Overflow技术生态系统的知识,但其实我已经在视频中进行了相关内容的讲解,也研究了那些与我们数据科学人员相关的技术。我还制作了一个名叫Shiny的应用程序,在上面你可以随意选择你想研究的主成分。而且我敢打赌,只要你用过一次Shiny,你就能想象到我是如何开始这项研究的!
高维平面的映射
PCA最酷的地方在于它能帮我们思考和推理高维数据,其中一项功能就是将高维数据映射到可绘图的二维平面上。接下来我们来看看它是如何做到这一点的。
其实这一步用broom :: augment()就能实现,并且还能计算出每个成分对整个数据集方差解释的百分比。
percent_variation <- tags_pca$sdev^
2
/ sum(tags_pca$sdev^
2
)
augmented_pca <- bind_cols(User = rownames(tags_scaled),
tidy(tags_pca$x))
augmented_pca
## # A tibble:
164
,
915
x
65
## User PC1 PC2 PC3 PC4 PC5 PC6 PC7 PC8 PC9
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
##
1
1
2.16
5.70
1.63
0.967
0.0214
-1.37
-1.98
-2.94
-0.860
##
2
2
0.350
3.38
-6.12
-10.0
1.39
0.882
5.35
-3.30
-2.73
##
3
3
2.75
-3.91
0.801
1.73
1.24
-0.837
2.03
2.76
0.300
##
4
4
3.27
-3.37
-1.00
2.39
-3.59
-2.68
0.449
-2.82
-1.25
##
5
5
9.44
-4.24
3.88
-1.62
-2.96
4.01
-1.32
-3.54
3.25
##
6
6
5.47
-5.13
1.57
2.94
-0.170
0.342
3.34
6.09
1.72
##
7
7
4.30
-0.442
-1.52
0.329
-2.13
0.908
-3.30
-5.02
-1.39
##
8
8
-0.691
0.668
-1.76
-7.74
-2.94
-5.28
-9.71
5.28
0.732
##
9
9
3.84
-2.65
0.760
1.34
2.06
-0.927
1.35
5.11
-2.69
##
10
10
3.23
4.13
2.81
2.68
-1.12
-1.30
-0.319
-1.23
-0.723
## # ... with
164
,
905
more rows, and
55
more variables: PC10 <dbl>,
## # PC11 <dbl>, PC12 <dbl>, PC13 <dbl>, PC14 <dbl>, PC15 <dbl>,
## # PC16 <dbl>, PC17 <dbl>, PC18 <dbl>, PC19 <dbl>, PC20 <dbl>,
## # PC21 <dbl>, PC22 <dbl>, PC23 <dbl>, PC24 <dbl>, PC25 <dbl>,
## # PC26 <dbl>, PC27 <dbl>, PC28 <dbl>, PC29 <dbl>, PC30 <dbl>,
## # PC31 <dbl>, PC32 <dbl>, PC33 <dbl>, PC34 <dbl>, PC35 <dbl>,
## # PC36 <dbl>, PC37 <dbl>, PC38 <dbl>, PC39 <dbl>, PC40 <dbl>,
## # PC41 <dbl>, PC42 <dbl>, PC43 <dbl>, PC44 <dbl>, PC45 <dbl>,
## # PC46 <dbl>, PC47 <dbl>, PC48 <dbl>, PC49 <dbl>, PC50 <dbl>,
## # PC51 <dbl>, PC52 <dbl>, PC53 <dbl>, PC54 <dbl>, PC55 <dbl>,
## # PC56 <dbl>, PC57 <dbl>, PC58 <dbl>, PC59 <dbl>, PC60 <dbl>,
## # PC61 <dbl>, PC62 <dbl>, PC63 <dbl>, PC64 <dbl>
注意到这里我其实有更广阔的数据框可供使用,并且我还没有使用gather()函数——为了便于绘图。对象percent_variation是一个矢量,它包含了每个主成分对整个数据集的方差解释的百分比。
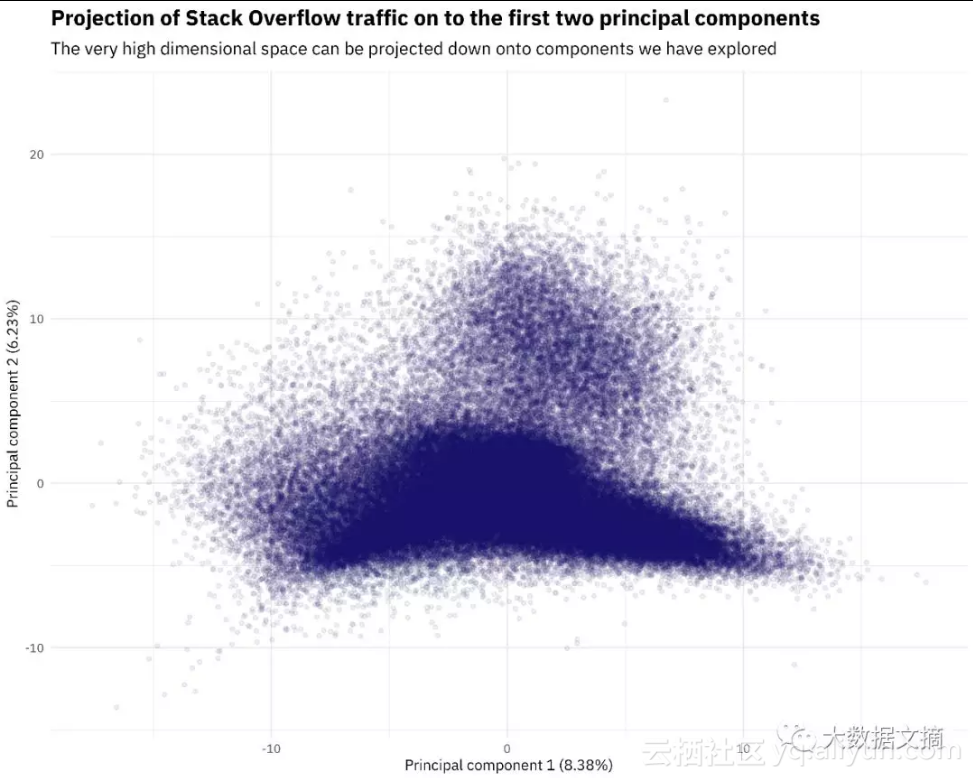
augmented_pca %>%
mutate(User = as.integer(User)) %>%
filter(User %%
2
==
0
) %>%
ggplot(aes(PC1, PC2)) +
geom_point(size =
1.3
, color =
"midnightblue"
, alpha =
0.1
) +
labs
(x = paste0(
"Principal component 1 ("
, percent(percent_variation[
1
]),
")"
),
y = paste0(
"Principal component 2 ("
, percent(percent_variation[
2
]),
")"
),
title =
"Projection of Stack Overflow traffic on to the first two principal components"
,
subtitle =
"The very high dimensional space can be projected down onto components we have explored"
)
可以看出,为了尽量减少过度绘图,这个图里我把每两个人用一个点表示。还记得第一个主成分是前端开发人员到Python和低级技术人员的横向拓展,而第二个主成分则全部是关于微软技术堆栈的。由上我们可以看到描述Stack Overflow标签的高维数据是如何投影到前两个主成分的。可以注意到我已在每个轴中添加了方差百分比,同时这些数字并不是很高,这也与我们现实生活中的情况相吻合,即事实上Stack Overflow的用户之间差异很大,如果你想将这些主成分中的任意一个用于降维或作为模型中的预测变量,请慎重考虑。
应用
说到现实生活,我发现PCA非常有助于我们理解高维数据集。比如说,基于完全相同的数据,我最近在使用PCA探索的另一个问题是亚马逊可能考虑让哪些城市成为其第二总部。实际上,PCA给出的主成分结果以及不同技术对其的贡献率已经不尽相同——因为几个月已经过去了,而且用户们在高维空间中也不是完全静止的。如果你有任何问题或反馈,请及时联系我。
原文发布时间为:2018-05-31
本文来自云栖社区合作伙伴“大数据文摘”,了解相关信息可以关注“大数据文摘”。