本文为CS231n-2017 Convolutional Neural Networks for Visual Recognition中Note:Linear Classification的中文翻译
线性分类
在上一节中我们介绍了图像分类的问题,这个问题中讲述的任务是从一系列固定的图像目录中选取一个单独的样本给一副特定的图像进行分配。此外,我们还介绍了k近邻分类器(KNN),这个分类器通过将这些测试图像和训练集中的图像进行比较来对这些测试图像进行标记。我们可以看到,KNN算法有很多的缺点:
- 分类器必须记忆所有的训练数据,储存起来,以便和未来的测试数据进行比较。这个对空间效率性很不友好,因为数据集很容易达到G级别的大小;
- 对测试图像进行分类代价很大,因为它需要和整个的训练集图片进行比较;
概要,我们准备建立一种对图像分类更加强大的方法,最终自然地延伸到整个的神经网络和卷积神经网络。这个方法包含两个主要部分:一个具有计分功能的函数(分数函数),这个函数将原始数据转化为划分分类的分数;另外一个是损失函数,来衡量预测得到的分数和真实标记值。之后我们将会将这些转化为一个最优化问题:也就是结合计分函数中的参数来最小化损失函数的值。
线性分数函数(从图像到标签分数的参数化映射)
方法中的第一个部分是定义一个分数函数,从而将图像的像素值投影为代表不同类别的可信分数(这个分数越高,代表图像是这个类别的概率越大)。在这里我们通过采用具体例子来实现这个方法。就如上头所说,假设我们有一个图片的训练集xi∈RD,每个训练集关联一个标志yi ,即i=1…N ,yi∈1…K ,也就是说,我们有N个样本例子(D维数) 和 K个不同的目录。比如说,在CIFAR-10中我们有一个N = 50,000图片的训练集,每个图片的维数 D=32x32x3=3072 pixels,K为10,因为这里有10中不同的分类(狗,猫,汽车等),我们现在就对分数函数进行定义:
线性分类器。
在这个模块中我们将合适地从最简单的分类函数(possible function)开始,一个线性分类函数:
f(xi,W,b)=Wxi+b
上面的函数中,我们假设图像xi的所有像素都集中在一个单独列向量[D x 1]中。矩阵W(大小[K x D])和向量b(大小[K x 1])是这个函数的参数。在CIFAR-10中,xi 包括了第i副图像中所有的像素[3072 x 1],并且以单独的列呈现出来,而W为[10 x 3072],b为[10 x 1],所以这3072个数字变量输入到上面这个函数中(原始图像像素点)然后输出10个数字变量(类别分数),在W向量中的参数往往被称作weights,b被称作偏移向量,因为它对输出分数产生了影响,但是偏移向量与实际数据xi之间并没有直接联系(然而,你将会经常看到人们将术语weight和parameters交换使用)。
这里需要注意一些事情:
- 首先,注意这个单独的矩阵Wxi可以有效地对10组不同的分类数据同时进行处理,每一个类代表W向量中的一行;
- 同样注意,在这里我们认为输入数据(xi,yi)是特定的、经过修正的,但是我们可以对参数W,b进行任意修改。我们的目的是将这些参数进行设定,从而可以实现计算出来的分数匹配整个训练集中的真实数据。我们将会对这个内容进行深入分析,但是直观上我们希望正确分类的分数比其他错误分类的分数更高。
- 这种方法的一个优点是,训练数据用来学习参数W,b,但是一旦学习完成我们可以扔掉整个训练集而只需要保存参数。这是因为一个新的测试图像只需要进入进入这个方程中,被分类,得到计算后的分数即可。
- 最后注意,对测试图像进行分类中涉及到了一个矩阵乘法和矩阵加法,这比将测试数据和整个训练数据进行比较可快多了。
提示:卷积神经网络也是如上述般将图像像素转化为分数,但是这个转化函数mapping(f)会更加复杂包含更多的参数
线性分类器的解释
注意,线性分类器计算出来的分数是通过对图片三个颜色通道的像素值总和进行有权重地累计。这个很依赖我们当初设定了权重值(weights),这个分类函数可以对图像中特定位置的特定颜色进行判别(根据每个权重值的类别)。比如,你可以想象到“船”这个类别很有可能判定到一副四周全是蓝色的图片(也就是说跟很有可能与水有关)。你可能想这个“船”分类器会对蓝色通道的权重产生很多正向的权重值(蓝色的出现使船的分数增高),也会对红/绿通道产生负方向的权重值(红/绿颜色的出现使船的分数减少)。

这里有一个例子将图像转化为分类分数。为了直观的显示,我们假设这个图像只有4个像素点(4个单色像素点,为了简洁,在这个例子中我们不考虑颜色通道),然后我们有三个种类(红(猫),绿(狗),蓝(船))。(需要知道:这里的颜色仅简单表示三个分类,与RGB颜色通道没有关系)。我们抓取图像像素为一列,然后进行矩阵乘法从而得到每个分类的分数值。我们在这里设定的一系列权重值W效果很差:这些值将我们的“猫”图像分配给的“猫”类分数很低,这些权重值似乎确认这幅图像为“狗”。
以高维点来比较图像的相似性。既然图像被提取为高维列向量,我们可以将每幅图像解释为在这个空间中的一个独立点(例如,在CIFAR-10中的每个32x32x3 pixels的图像在3072维空间中是一个点)。相似地,整个数据集就是一系列(被标记的)的点。
因为我们定义每个分类分数为所有图像像素的权重和,每个类别分数在空间中为一个线性函数。我们不能把3072维的空间给展示出来,但是如果我们将那些所有的维压缩成仅仅二维,我们就可以尝试直观地看到这些分类器的作用。
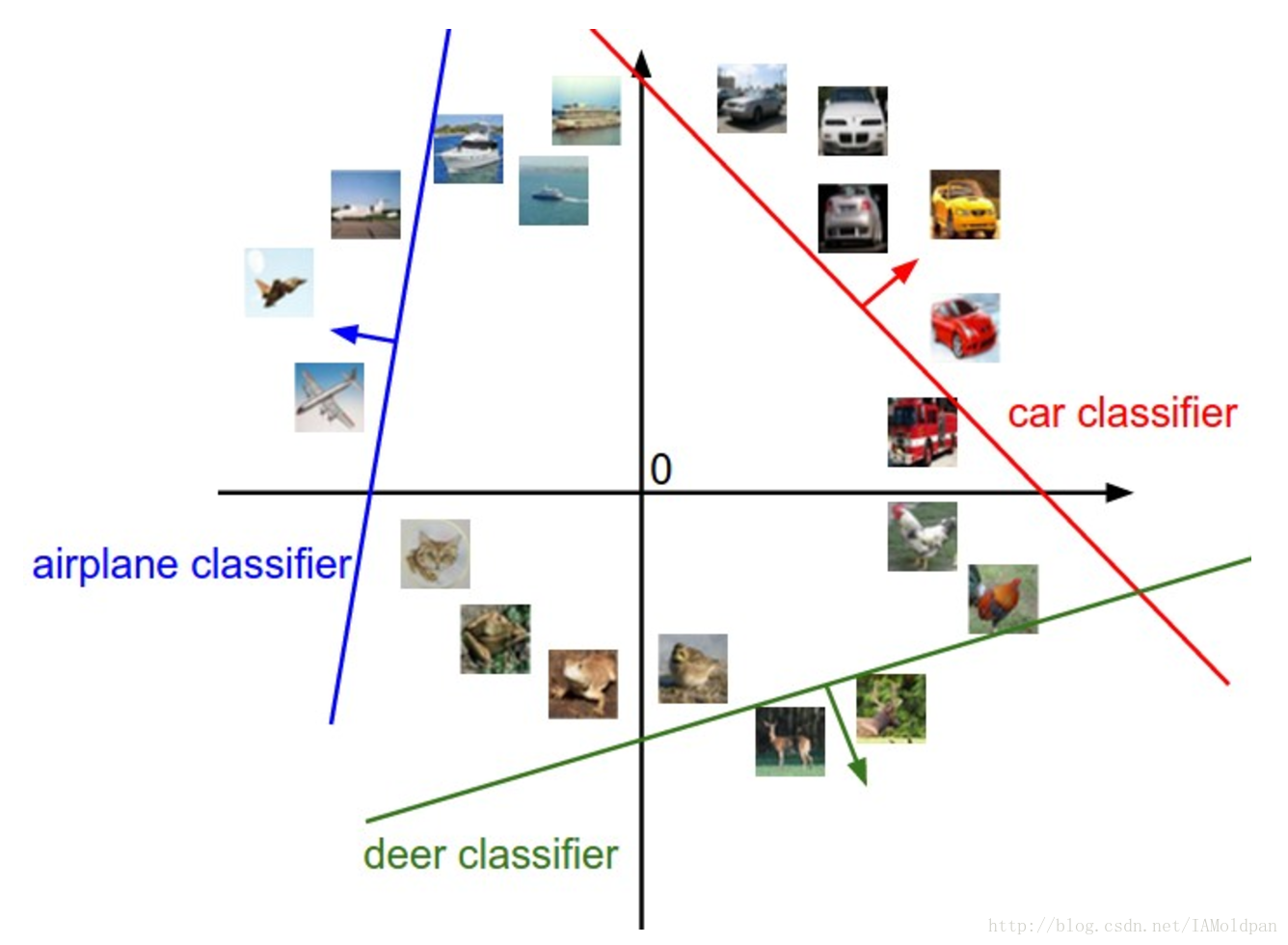
上图为图像空间的简单表示,其中每个图像是一个独立点,三个分类器也展示出来。以汽车分类器(在红色区域)为例,这条红线表示空间中所有汽车分类分数为0的点。红色箭头显示了增加的方向,所以所有朝着这个方向的点将会有正分数(线性递增),所有红线左侧的点将会有负分数(线性递减)。
如上所述,在W中每一行是其中的一个分类器。形象化来说,我们改变W其中一行的数据,上图像素空间中相应的线将会往不同的方向旋转。另一方面,偏移向量b可以让分类器去解释这条直线。特别注意,如果没有偏移向量,不管权重值是怎么设定的,输入xi=0将总会得到0分数,因此所有的直线将会被迫交到同一个起点。
以模板匹配来解释线性分类器。另一种对权重向量W的解释是,每一行的W与一种模板相对应(或者有时称作原型),代表类中的一个。每一类中图像的分数通过一个一个比较每个模板和图像的内积(或点积)去得到,去寻找那个最“符合”的。使用术语描述就是,这个线性分类器在做模板匹配,其中这个模板已经被学习了。另一种方式去思考这个问题就是我们依旧在有效地进行近邻分析,但不是和成千的训练图像,仅仅是每一个类别中一个单独的图像(虽然我们确实在学习,但是这个学习成果不一定非要是训练集中的一个图像),而且我们用(负)内积来表示距离,而不是之前的L1或者L2距离。

提前说一下:上面是在CIFAR-10中学习到的权重例子。可以看到比如船这个模板,如我们之前想到的,包含大量的蓝色像素。这个模板因此会在和有船图像进行内积匹配时产生很高的分数。
另外,注意马的模板似乎包含一个双头马,这是因为在训练集中的所有图像中,有的左边有马、有的右边有马。这个线性分类器将训练集中这些不同模式的马进行了融合为一个单独的模板。同样,这个汽车分类器似乎也将多种模式的车图像融合到了一个单独的模板中,这样就可以去从各种角度,各种颜色来确认车图片。特别的是,这个模板最终的颜色是红色的。这个线性分类器对于说明其他颜色的车就显得有点乏力了,但我们在之后将会看到神经网络会让我们实现这个任务。提前说一下,一个神经网络将能够在隐藏层建立一个中间神经,这个神经可以检测特定的汽车类别(比如,绿色的朝左边的车,蓝色的朝前面的车),然后下一层的神经可以通过一个独立车辆检测器的权重和将这些结合为一个更准确的汽车分数。
偏移技巧,在继续这个话题之前我们想提到一种常见的,去用一个元素表示两个参数W,b的简化方法,回顾一下我们定义的分数函数:
随着我们处理这些材料,去分别跟踪这两个参数集会有一点麻烦(偏移向量 b和权重向量 W),一个普遍地结合这两个参数集为一个矩阵的方法就是将向量 xi再加上一个维数用来放常数1——默认的 偏移维度。有了这个维度,新的分数方程将会简化为一个单独的矩阵乘法:
以我们的CIFAR-10例子, xi现在从[3072 x 1] 变成了[3073 x 1] -(其中有一个额外的维数用来存放常量1),还有 W现在是从 [10 x 3072]变成了[10 x 3073]。 W中额外的列就是偏移向量 b,用一个图示去帮助你理解:
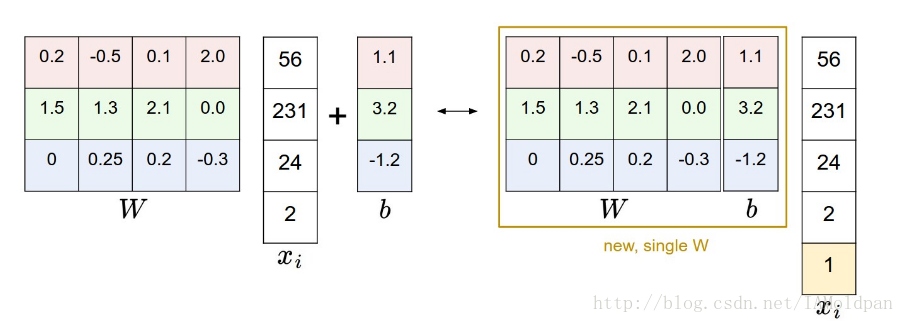
偏移技巧的图示,图左边做一个矩阵乘法然后再加上一个偏移向量,和图右面为所有的输入向量加上一个常量为1的偏移维数,将权重矩阵再加上一列是一样的。因此,如果我们想要在预处理过程中给所有的向量附上这些值,我们只需要学习一个单独的权重矩阵即可,而不是使用两个包含权重和偏移量的矩阵。
图像数据预处理,简单说明一下,在上面的例子中我们使用原始像素值(范围为 [0…255])。在机器学习中,非常常见的是对输入的特征数据进行标准化(对于图像来说,每个像素值被看做特征)。实际中,通过减去每个特征的均值来确定数据中心是很重要的。图像来说,就相当于计算整个训练集中的图像得到平均值图像,然后减去这个平均值图像,此时得到的图像的像素范围是 [-127 … 127]。更加常见的预处理是对每个输入特征进行比例调整,这样它的值范围就变成了 [-1, 1]。其中,零平均中点可以说更为重要,但是我们必须有它重要的理由,这个只有直到我们了解梯度下降的动态性才会得到证明。
损失函数
上一节中我们定义了一种函数将像素值转化为分类分数,其中的参数是权重向量W。此外我们知道我们没有控制数据(xi,yi)(这些给定数据是固定的)的能力,但是我们确实可以控制这些权重,想要去设置这些权重从而预测的分类分数和训练集中真实标记是一致的。
比如,回顾一下之前的猫图像的例子还有它被分成“猫”,“狗”,还有“船”的分数。我们看到在那个例子的特定权重集一点也不好:我们给予了描述猫的像素点,但是相比于其他分类(狗的分数437.9,船的分类分数61.95),结果中“猫”分类得到的分数却非常低(-96.8)。我们打算用一个损失函数(或有些时候我们称为代价函数或者目标函数)测量我们对于这个分类的不满意程度。直观上说,这个损失值随着我们分类失败变高,分类成功变低。
多类支持向量机损失
这里有很多方式去定义损失函数的具体过程。作为第一个例子我们将会首先建立一种被普遍使用的损失称作“多类支持向量机(SVM)损失”。这个SVM损失建立通过一些固定的边缘Δ来描述SVM“想要”每个类中正确的分类从而得到比不正确分类更高的分数。它在某些时候可以赋予损失函数类似人的感觉:SVM“想要”一个特定的输出,这个输出将会产生一个较低的损失(当然是好的)。
让我们更明确地说一下,回顾之前第i个例子样本,我们有图像xi的像素值和标记yi用来确认正确分类的索引。分数函数(score function)读取像素值然后计算向量f(xi,W)得到分类结果分数,我们将这个分数函数简写为s(score分数的简写)。比如,第j层元素是第j层的分类结果:sj=f(xi,W)j。第i个例子样本的多类支持向量机损失可以被调整为:
举个例子。让我们分解这个式子来看它是怎么工作的。假设我们有三个类,它们得到的分数s=[13,−7,11],对于第一个类别来说这是个真类(如,yi=0)。同时也假设Δ(一个超参数我们将会详细讲述)是10。上述表达式将所有不正确的分类全部求和,所以我们得到两个关系:
Li=max(0,−7−13+10)+max(0,11−13+10)
你可以看到上式第一项为0,因为 [-7 - 13 + 10]得到一个负值,这个负值会通过max(0,−)函数强制转化为0。第一项的损失分数为0,是因为正确分类分数(13)比不正确分类分数(-7)大,至少超过了边缘值10。实际上这个距离是20,比10可是打多了,但是SVM只关心距离至少是10就行了。任何其他在这个边缘值之上的距离都会被max操作函数强制为0。第二项计算 [11 - 13 + 10] 得到8。这说明,虽然正确的分类比不正确的分类大,(13>11),但是这个小于边缘值10。仅仅为2,这就是为什么损失分数为8的原因(这个8的意思就是还需要多少差值,就可以达到10了)。总之,SVM损失函数想要正确分类的分数比不正确分类的分数至少大Δ。如果不是,损失将会累计。
注意,在实际的模型中,我们使用的是线性分数函数f(xi;W)=Wxi,所以我们可以将损失函数改写为:
其中 wj是矩阵 W的第j行,转置为列。然而,这种情况在我们开始进行更加复杂的分数函数 f形式的时候并不是必要的。
在我们完成这个小节之前我们将要提出最后一个术语,那就是0门槛函数max(0,−),我们经常称之为铰链损失(hinge loss)。有时你会看到人们也会用平方铰链损失SVM(或者叫L2-SVM),使用的是这种形式:max(0,−)2,这种形式对于违反边缘值的参数会有更高的惩罚(不是线性,是二次方)。没有平方的版本更标准一些,但是在一些数据及当中平方铰链损失效果更好一些。这个可以在交叉验证中得到。
损失函数代表我们对训练集预测结果的不满度度

多分类支持向量机想要正确分类的值比所有不正确分类的值至少大一个delta的值。如果任何分类的分类分数都在红色区域上(或者更高),那么损失将会被累计。否则损失将会变成0。我们的目标就是找到一个既可以对所有样本满足上述的规则,又可以尽可能小的权重值。
正则化。我们之前展示的损失函数有一个问题。假设我们有一个数据集和一系列可以正确分类的参数W(所有的分数都和边缘值匹配,对于所有i都有Li=0)。这个问题就是上述一系列的W并不是独一无二的。有很多的类似的W也可以正确地分类样本。简单来说,如果一些参数W可以正确地分类所有的例子(也就是对于每个例子损失为0),那么任何和这些参数W的乘积参数λW,其中λ>1,都将会得到0损失,因为比例转化拉大了所有分数值,因此他们的绝对差也被拉大了。比如,如果正确分数和一个最近的错误分数相差15,那么对所有元素W进行乘积将会得到一个新的差值30。
换句话说,我们希望对特定权重集W加入一些偏好来消除二义性。我们可以通过额外添加一个带有正则化惩罚的损失函数来实现。最常用的正则化惩罚形式为L2,通过元素平方来惩罚所有参数,从而使较大的权重值减小。
在上面的表达式中,我们将所有元素W的平方加起来。注意这个正则化方程并不是包含数据,仅仅是基于权重的。包括了正则化惩罚才能算是完整的多分类支持向量机损失,它由两部分组成:数据损失(在所有样本中为平均损失Li)还有正则损失。这样的话,完整的多分类支持向量机损失变成:
或者扩展开变成这种形式:
其中N是训练样本的数量。可以看到,正则化惩罚被我们加入到了损失目标中,通过一个超参数λ来进行加权。设置这个超参数并没有一个简单的办法,通常通过交叉验证来确定它。
除了上述我们提供的可以达成一定目的的性质,还有很多值得我们利用包括正则化惩罚的性质,这些我们在之后的章节中会进行讲述。比如使用L2惩罚可以改变SVM中的最大边缘值( max margin)
得到最好效果的方法就是惩罚大权值来提高准确度,因为这就意味着没有一个输入维可以拥有一个对分数特别大的影响值。比如,下设我们有一些输入向量x=[1,1,1,1]还有两个权重向量w1=[1,0,0,0],w2=[0.25,0.25,0.25,0.25]。然后有wT1x=wT2x=1,这样两个权重向量都拥有相同的点积,但是L2对w1的惩罚是1.0,而L2对w2的惩罚仅仅是0.25.因此,根据L2对向量w2的惩罚值来说,它更加好一些,因此它可以得到一个很低的正则化损失。
直观上来看,这是因为在w2中的权重比较小,也容易扩散。因为L2比较偏向小的且发散的权重向量,所以最终的分类器我们会考虑使所有输入维变成多而小的数据而不是少而大的输入。我们在之后的分类中将会看到,这种影响将会提高在测试图像上分类的性能,也会降低过度匹配的概率。
注意,偏移量并没有这种影响,不像权重值,他们不能控制对输入维数的影响强度。因此,常常对权重W来进行规范而不是偏移b,然而,在实际中这样的效果其实往往可以忽略。最后注意,因此这种正则化惩罚,我们不可能在所有样本上实现损失刚好为0.0,因为这个只有将W不合适地设置为0才会出现。
代码下面是使用python写的损失函数(没有正则化)程序,包含无无向量和有向量两种形式:
def L_i(x, y, W):
"""
无向量版本,对一个简单的例子(x,y)进行多分类svm损失计算
- x是一个表示图像的列向量(e.g. 3073 x 1 in CIFAR-10),在3073列包含一个偏移向量(i.e. bias trick)
- y是一个给与了正确分类索引的整数(e.g. between 0 and 9 in CIFAR-10)
- w是权重矩阵(e.g. 10 x 3073 in CIFAR-10)
"""
delta = 1.0 # 在下节中再讲解这个值
scores = W.dot(x) # 得到的scores的形式为10 x 1, 也就是十个类别
correct_class_score = scores[y]
D = W.shape[0] #分类数量, e.g. 10
loss_i = 0.0
for j in xrange(D): # 对所有错的分类进行迭代
if j == y:
# 省略正确的分类,仅对不正确的分类进行迭代
continue
# 累计第i个分类的损失
loss_i += max(0, scores[j] - correct_class_score + delta)
return loss_i
def L_i_vectorized(x, y, W):
"""
一个快速的半向量优化,半向量指的是对一个简单的例子来说,对循环进行了优化,但是依然存在一个循环(在这个函数外头)
"""
delta = 1.0
scores = W.dot(x)
# 在一个向量操作中计算所有的分类的矩阵
margins = np.maximum(0, scores - scores[y] + delta)
# 在第y个位置 scores[y] - scores[y] 取消了,多了delta。我们想要忽略第y个位置,仅仅考虑在最大错的分类中的差值
margins[y] = 0
loss_i = np.sum(margins)
return loss_i
def L(X, y, W):
"""
标准向量优化 :
- X holds all the training examples as columns (e.g. 3073 x 50,000 in CIFAR-10)
- y is array of integers specifying correct class (e.g. 50,000-D array)
- W are weights (e.g. 10 x 3073)
"""
# evaluate loss over all examples in X without using any for loops
# left as exercise to reader in the assignment这一节的关键在于,SVM损失使用一种特别的方法去衡量训练数据和真实数据之间的连续性。另外在训练集上做出好的预测相当于最小化了损失。
所有我们必须要做的就是找到一种找到最小化损失权重的方法
个人翻译工作中止,因为有前辈已经在之前已经进行了翻译。:
https://zhuanlan.zhihu.com/p/20900216?refer=intelligentunit