简介
众所周知,人工神经网络(ANN)的设计思路是模仿人脑结构。但是直到10年前,ANN和人类大脑之间唯一的共同点是对实体的命名方式(例如神经元)。由于预测能力较弱并且实际应用的领域较少,这样的神经网络几乎毫无用处。
但是随着近十年来技术的飞速进步,神经网络越来越接近人脑,这使得ANN在各个行业中应用得越来越多。
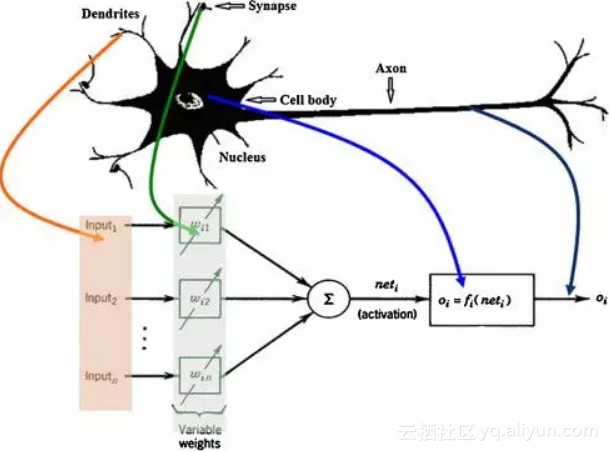
本文中,我们将介绍人工神经网络(ANN)领域的两大革新,这些革新使得ANN更接近于人类大脑。
目录
ANN领域的两大革新
我们能否在ANN中引入“思想”的概念呢?答案是肯定的,本文将进一步讨论这个理念。
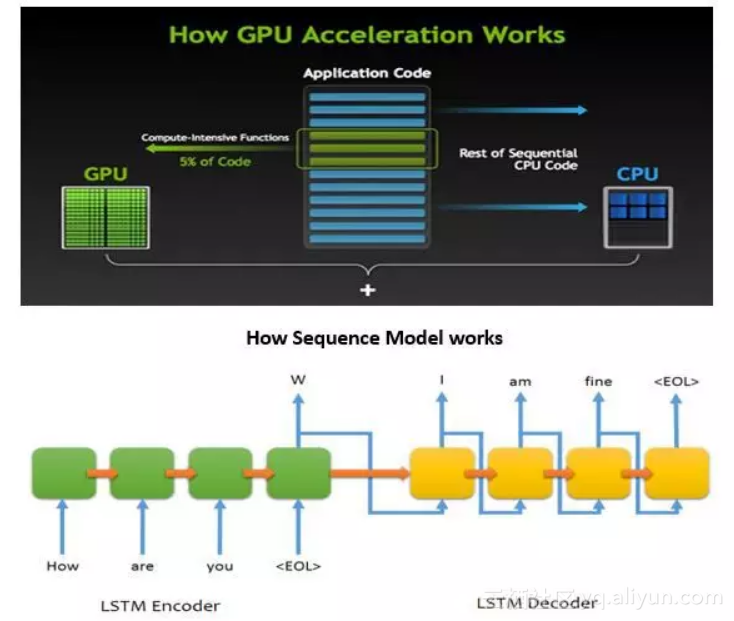
现实世界的大部分数据都是以序列的形式出现的,这使得序列模型受到越来越多的关注。序列可能是数列、图片像素序列、视频序列或者是一段音频序列。
在过去的十年间,我们已经存储了近1000PB(或者超过109GB)的非结构化数据,以前我们很难从中提取信息,幸运的是,我们现在有序列模型这样新型的神经网络结构,它可以把数据变成金矿。
本文并不讨论序列模型背后所有复杂的数学原理,或是提供一些运行序列模型的示例代码(我将把代码留给以后的文章)。本文想要提供一些行业内应用序列模型的实际案例,从而帮助你识别出可以通过此类模型解决的商业问题。
为了更好地理解本文,接下来希望你能想象一个场景。请开启你的分析推理模式吧!
思想实验
假如现在沃尔玛指派你负责一个新项目 – WalKiosk,希望你带领团队开发出无人自助超市,顾客只需要和沃尔玛的Kiosk互动就可以完成购物,就好像自动售卖机一样。沃尔玛想把这样的Kiosk应用在美国各地。
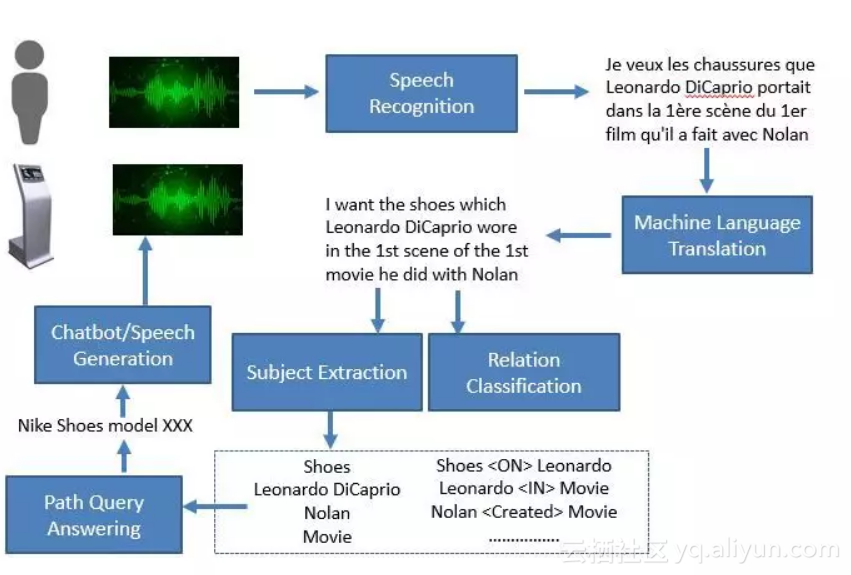
Kiosk和普通自助售卖机的关键区别是Kiosk不会展示售卖商品的名录,而是通过音频开启一个类似Google 的搜索引擎。顾客走到Kiosks面前,以“OK Walmrt, xxxxxx”这样的关键字开头,然后说出或输入想要的商品。下面是一个交互案例(你可以试着评估一下人类售货员是否能比Kiosk 做的更好):
顾客说“OK Walmrt,,我想要Leonardo DiCaprio 和Nolan搭档的第一个电影中,第一幕里他穿的那双鞋。”使用的是某国语言。
你的团队要做的是让Kiosk快速搜索,如果找到一个可靠的答案,就通过客户咨询时使用的语言来回复,比如“Leonardo DiCaprio穿的是黑色xxxxx款的Nike鞋。点击链接观看您所需物品的短视频介绍。好消息--我们目前有您需要的款式和鞋码,价格是200美元。由于您是沃尔玛的忠实用户,我为您找到了合适的折扣!立即购买仅需150美元。”
如果顾客说“好的我买了”,Kiosk会在顾客付款后立刻交货。
Kiosk最后说道“感谢XYZ先生今日的惠顾,请为我们的服务提供宝贵建议,以便我们不断改进”,然后顾客通过文字或语音留下对本次交易的反馈后离开。
这样一个简单的交易现在如今的世界里要占据你大块的时间,但是今后只需要不到两分钟(如果一切正常的情况下)。
这听起来是不是很超前?实现Kiosk的功能主要通过一个简单的结构--序列模型。以下是Kiosk需要具备的功能列表:
![]() 产品销售预测用于补充库存。
产品销售预测用于补充库存。
完成Walkiosk所需的不仅仅是以上九个功能,但是它们足以实现核心想法。九个功能中的任意一个都可以通过单一结构----序列模型构建。
你可以将序列模型想象为一个几乎保持不变的黑匣子,只需要按这九个功能改变输入和输出数据,每个功能的模型架构是相同的。我们可以进一步生成以任何语言为输入的单一模型,一并完成自助服务过程、报告过程、库存管理过程。
如果这还不足以帮助你完整了解序列模型,让我们整理一个序列模型可以实现哪些功能的详尽列表。
序列模型的实际应用
为了确保列表尽可能涵盖序列模型的潜在用例,我们基于输入和输出序列的类型进行分类。输入和输出可以是以下任意一种:标量(Scalar)、趋势、文本、图像、音频和视频。如果以上六种都可以作为输出和输入,我们一共得到36种分类,然而不是每一种组合的研究都已经成熟。
在阅读下面这个列表之前,你可以先停下来。尝试写出你自己的用例列表(可以参考前文的思想实验)。
列表如下:
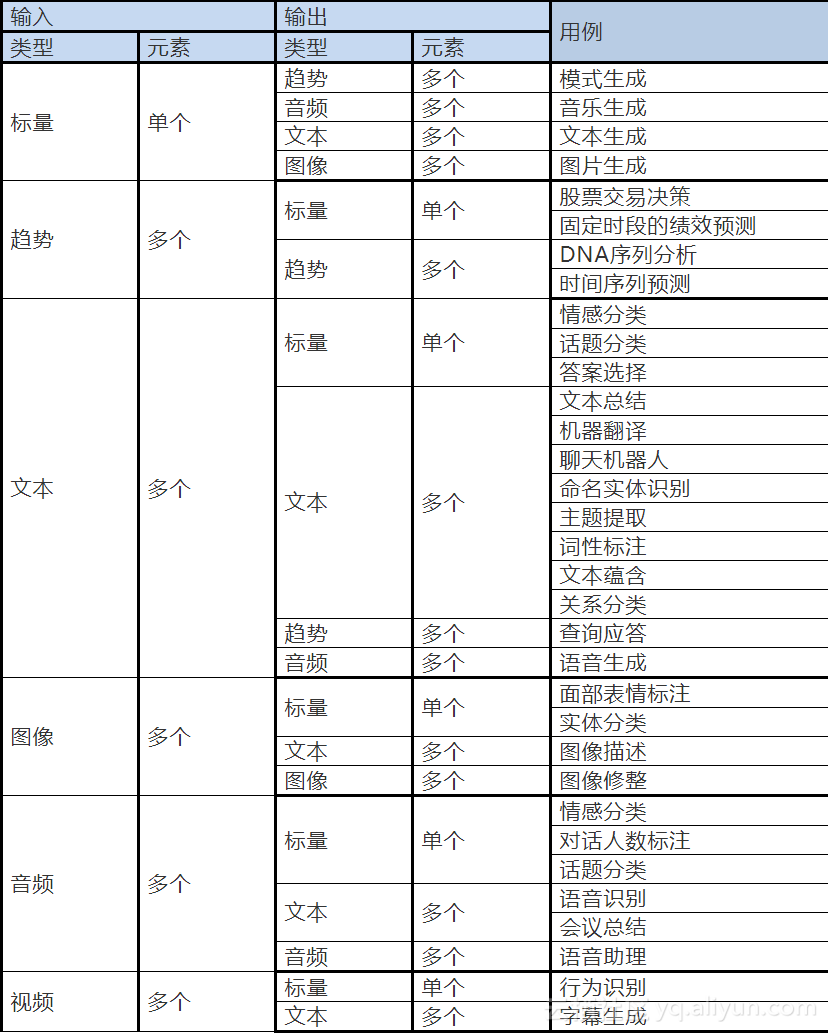
表格中的名词解释:
类型是输入或输出的类型。
元素是输入或输出序列中元素的数目。
用例是分类中可能的应用方向。
下面我们将介绍一些实际案例,带你领略序列模型的超能力。
首先,我们先介绍最简单的—序列生成器
这些生成器通常采用标量作为输入,标量输入可以是任意的随机种子或数据。以下是一些生成器的案例:
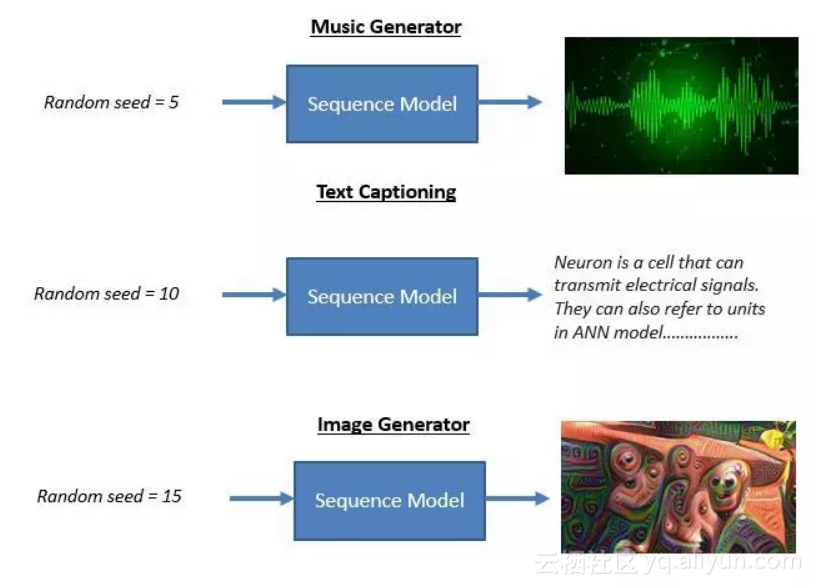
值得注意的是,我们可以用任何特定类型的数据来训练模型。例如,如果我们用哈利波特的书来训练文本生成器(Text generator),很可能会得到一段有关于哈利波特主人公的奇幻文字。如果你足够幸运,可能会得到一个有实际意义的章节,于是你创造了属于你的独创内容。
如果你用爵士乐训练模型,你可能会通过模型生成同一风格的新曲子。如果你用动物的图片训练模型,你可能会看到杂交物种的样子。
其次,我们介绍最受欢迎的-序列到序列 NLP模型
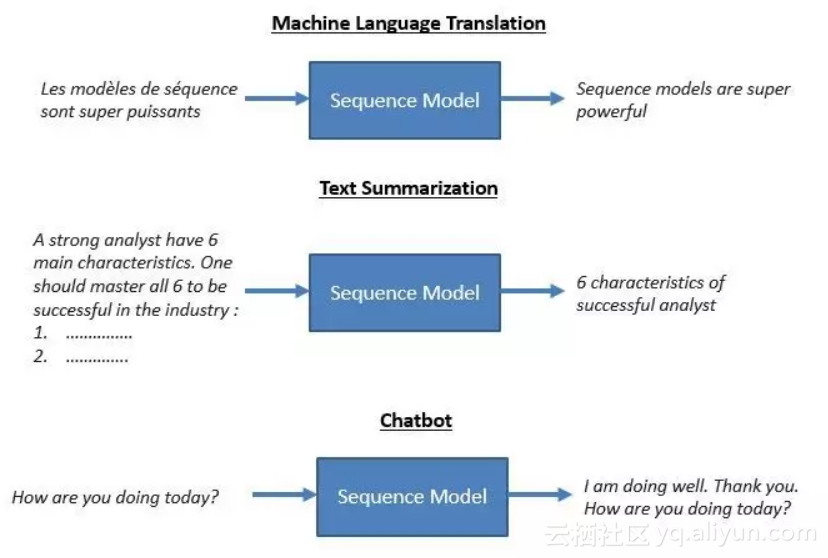
机器语言翻译(Machine Language Translation)已经达到新的高度,现在正和人工翻译展开激烈的竞争。如今,你可以轻松找到基于序列到序列模型(Sequence to sequence, seq2seq)核心概念的实时翻译机器。
文本总结(Text Summarization)是序列模型的另一个重要用例。文本总结可以显著减轻以下工作负担--阅读顾客冗长的投诉、电话/通讯监控、汇总顾客对产品的反馈等。
聊天机器人(Chatbot)是另一个重要的用例,目前被广泛地应用于经营活动、呼叫中心、交流中心和类似Siri、Google Home、Alexa类型的用户辅助。
最后,我们介绍更多非文本的序列到序列模型
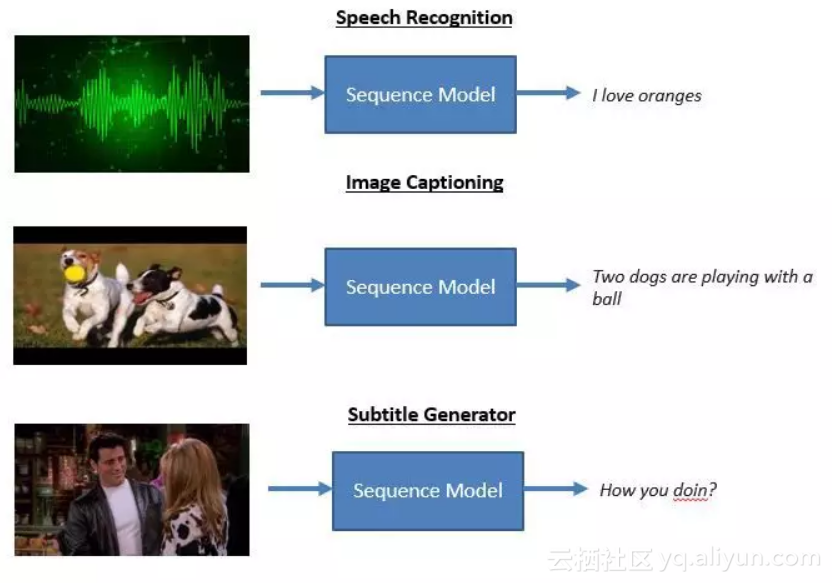
语音识别(Speech Recognition)是目前最受投资追捧的一个领域,其在个人Al助理(Alexa、Google Home等)和呼叫中心语音记录工具等用例中扮演了非常重要的角色。
在上图提到的三项技术中,目前有市值约10亿美元的企业以语音识别为核心竞争力,语音识别中广泛地使用序列到序列模型。图像描述(Image Captioning)是最热门的研究领域之一,它在社交媒体领域有广泛应用。至于字幕生成(Subtitle Generator),这项技术尽管还没有达到产品阶段,但是目前也在积极地探索中。
尾记
如今数据科学领域的很多牛人都在致力于解决已经存在的问题。然而对于任何成功的数据科学家或分析员来说,识别并提出可以分析解决的问题是同样重要的任务。后者是非常不同的工作,并且不需要过多的编程经验或数学背景。你唯一需要做的是通过给定的工具了解哪些是可能实现的,而哪些不能。
问题识别是资深的分析专业人士必备的技能。我希望这篇序列模型的入门文章可以激励你去寻找领域内能以此工具解决的新问题。
原文发布时间为:2018-05-28
本文作者:数据派
