Facebook还针对这个论文,在youtube上发布了一段炫酷的视频,引爆了一众音乐人和科技从业者。文摘菌也把这个视频带回了墙内,让我们也来一睹为快这个有趣的转化过程。
这段视频很好的诠释了这个网络是如何进行自动音色转化的
点击查看视频
视频演示了这一通用的音乐迁移网络的转换效果。视频中演示了莫扎特的交响曲、海顿的弦乐四重奏,以及巴赫演奏的各种乐器,除了古典的音乐,甚至还包含了合唱团的声音、非洲音乐和吹口哨的声音。
你可以输入海顿的弦乐四重奏,然后输出莫扎特的交响乐曲、巴赫的清唱剧,亦或者是管风琴以及贝多芬的钢琴等风格多样的曲风。
视频里总共展示了21个样本,对乐器、人声、鼓声、交响、歌剧等各种风格的音乐进行了输入,输出的音乐有时候确实出乎你的意料。
这里用到的神奇魔法我们之前在图像领域已经使用过了。不久前,文摘菌刚刚介绍了英伟达发布的一篇很有趣的论文,通过迁移学习,将猫咪的图片转换生成狮子,老虎甚至汪星人的图像(点击查看报道)。
这次的小魔法依然是使用迁移网络进行的,和英伟达的研究不同,这次,风格迁移被用在了音乐界——不同曲风之间的转换上。

Facebook AI研究院的最新论文:一种通用的音乐迁移网络
不想啃生肉的同学,以下是论文精华内容:
本文提出了一种能在不同乐器,流派和风格之间实现音乐曲风迁移的方法。该方法基于一个多域WaveNet自编码器(注:WaveNet,谷歌公布的一种原始音频波形深度生成模型),一个共享编码器和一个经过训练的、端到端的隐式波形解码空间。
采用不同的训练数据集和大容量的网络,独立域的编码器甚至可以实现未经训练的音乐域内的曲风迁移。该方法具有无监督性,并且训练过程不依赖有监督训练中,目标域音频与输入音频之间的样本匹配。我们用NSynth数据集和一个由专业音乐家收集的数据集上评估了该方法,效果良好。
相关工作
域迁移
本文中,首先利用大量真实数据对自回归模型进行了训练(即teacher forcing算法),然后由该模型生成输出结果。我们仅在测试过程中进行了自回归推理,为了训练GAN网络,在实际生成音频时(机器输出的“假”音频),并没有使用自回归模型。
音频合成
在本文的编码-解码结构中,使用WaveNet 模型作为解码器的输出,并通过该模型将输出结果反向传播至编码器中。
与之间的研究结果不同,本文中的输入数据收集于消费类媒体,并且没有经过预先处理。我们的总体结构中增加了多解码器和用于训练退相干的辅助网络,并增加了重要的数据增强步骤。在前期工作中,为选择编码器和解码器选择相同的超参数,进一步增加了该方法的输出效果。
风格迁移
风格迁移的本质是,在输入和输出过程中,音频的“内容”保持不变,但音频的“风格”进行了改变。
本文中采用了目前较为成熟的经典分类方法,但是该方法仍不适用于单声道乐器(每次采集一个音符)。此类方法都是基于综合框架进行分析。首先,通过分析音频信号使用和声追踪方法提取出音调和音色,然后通过一个已知的音色模型,将其转换成另一种单声道乐器的音频。
论文方法
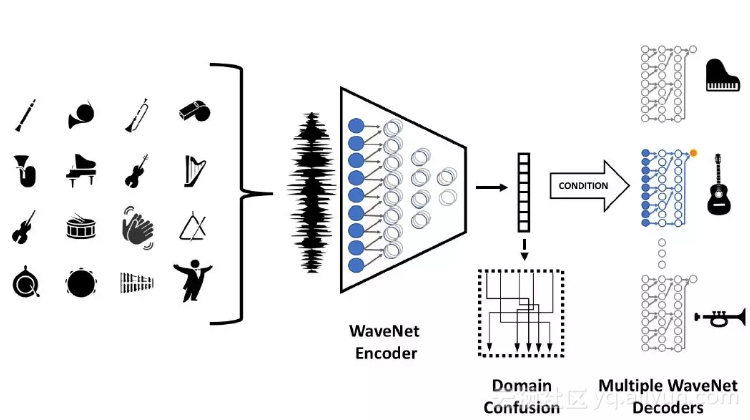
WaveNet 自编码器
模型中的编码器是一个完整的卷积网络,可以计算任意的长度的序列。该网络有三个区域,每个区域有10个残差层。每个残差层包含一个RELU非线性函数,一个随着核的尺寸而增加的卷积矩阵,进行二次计算的RELU函数,和一个1×1卷积矩阵,该矩阵用来表示第一次RELU函数计算之前激活函数的残差和。
该模型有128个固定宽度的通道,除了上面提到的三个区域,还有一个阶数是1×1附加区域。残差层下面是一个核大小为50毫秒(800个样本)的平均池,用来获得R64中的编码,并通过乘以12.5实现短时降采样。
模型结构
在编码过程中使用最近邻插值实现短时上采样,将音频调整到到原始比率,并作为WaveNet解码器的限制条件,通过对每个WaveNet层增加不同的阶数为1×1的附加层进行限制。
输入和输出的音频分别量化为8个比特的文件,然后利用mu-law法则进行编码,这也导致了一些音频质量的损失。该WaveNet解码器具有4个区域,每个区域都由10个残差层构成,因此该解码器一次可接收4093个样本,或者说时间步为250毫秒。
增强输入音频
为了提高编码器的泛化能力,并使它保留高级信息,我们使用专门的增强程序来改变音调。由此生成的音频,质量和源音频相差无几,只是略微有点跑调。具体来讲,我们将音频分割成长度为1秒的片段进行训练。在增强程序中,统一选择音频长度在0.25到0.5秒之间的片段,并使用Python中的librosa工具包生成-0.5到0.5之间的随机数,对音调进行调制。
训练过程和损失函数
在训练过程中,j代表不同的域,且j=1,2,……k。s^j表示输入样本,E表示共享编码器,D^j表示域j中的WaveNet解码器。C表示分类网络,O(s,r)表示将随机种子r用于增强程序中对样本s进行调制。
自编码器基于下列损失函数进行训练:
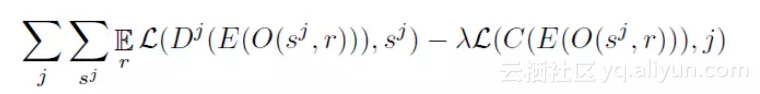
其中,L(o,y)是每个输出元素o与之相对应的目标元素之间的交叉熵损失。解码器D^j是一个自回归模型,根据输出结果E进行约束。在训练过程中,通过上一步的目标输出s^j对自回归模型进行调整。通过对分类网络C进行训练,使得分类损失最小化,其中分类损失为:
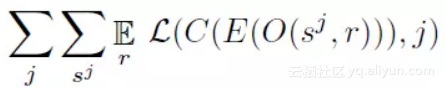
实验过程
训练过程
我们用六个域的古典音乐数据对网络进行了训练,分别是:
-
莫扎特的46首交响乐,由卡尔·伯姆(Karl B Hm)指挥;
-
海顿的27首弦乐四重奏,由Amadedus Quartet演奏;
-
约翰·塞巴斯蒂安·巴赫(J.S.Bach)的管弦乐队,合唱团和独奏曲目;
-
巴赫的管风琴音乐;
-
贝多芬的32首钢琴奏鸣曲,由丹Daniel Barenboim演奏;
-
巴赫的键盘音乐,用羽管键琴(Harpsichord)演奏。
通过将音轨(或音频文件)分为两个数据集,分别进行了模型的训练和测试。
迁移质量的评估
E表示由多种演奏背景的三个专业音乐家演奏的作品,他们都是从音乐学院毕业且在音乐理论和钢琴演奏上都有深厚的背景,同样也精通音乐改编。M表示由一位在音乐改编方面的专家演奏的作品,同时他也专业的音乐制作人、作曲家、钢琴家和录音工程师。A表示由一位音乐制作人演奏的作品,同时也是音乐剪辑师,并能熟练演奏键盘和其他乐器。
音乐改编的任务是,将5秒长的音频分成60个音乐片段,并分别用钢琴进行弹奏。音乐片段来自不同的数据集。其中20个片段来自巴赫的键盘作品,用羽管键琴演奏;另外20个片段则来自莫扎特的交响乐,属于管弦乐作品。
最后20个片段是三个不同领域音乐的组合——摇摆爵士乐,吉他即兴演奏音乐和中国乐器演奏的音乐,而且没有使用该数据集对模型进行训练。
60个音乐片段由通用编码器进行编码,并由经过Daniel Barenboim演奏的由贝多芬钢琴奏鸣曲训练的WaveNet进行解码。
我们使用平均意见值(Mean Opinion Scores (MOS))来评估音频质量,并通过使用CrowdMOS工具包采集了音频的MOS。评估过程中考虑两个标准:
-
音频的质量;
-
改编后的音频与源音频的相似度。
改编音频的MOS评分表
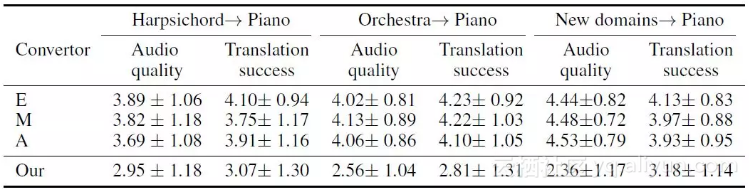
实验结果如上图所示。结果表明,模型生成的音频质量低于由人类演奏的电子键盘的音频质量。
此外,从羽管键琴迁移生成的音频的MOS高于从管弦乐迁移生成的音频。令人惊喜的是,从混合域迁移生成的音频,其MOS高于其他任何域的迁移音频。在所有条件下,人类演奏家的音频质量均高于我们模型生成的音频,他们的演奏音频即将作为一个公共数据集进行公布。
接着,我们评估了不同条件下,人类演奏音频和模型生成音频与源音频的音色之间归一化相关性,其结果如下图所示。
改编音频的归一化相关系数
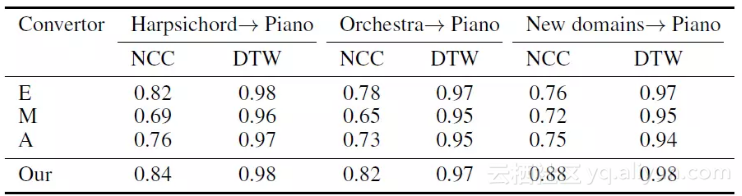
由上图可以看出,模型生成的音频的音色与源音频更接近,并且高于人类演奏家的得分。而且在动态时间规划(Dynamic Time Warping,DTW)方法评估下,差距将进步一缩小。
结论
我们的研究成果对一些高级任务提供了参考,如由机器实现音乐的改编和自动谱曲。对于第一项任务,通用编码器应该可以胜任,因为它能够以某种方式捕获所需的信息,正如上面的MOS评分表。对于第二项任务,我们已经得到了初步结果。通过减小隐式解码空间的大小,解码器变得更加“富有创造性”,输出的音频也会表现出自然而新颖的特性,换句话说,不考虑输出音频和原始音频之间的匹配关系,通用编码器也有望实现第二项任务。
文发布时间为:2018-05-24
本文作者:文摘菌