热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
[设计模式 Go实现] 行为型~中介者模式
[设计模式 Go实现] 行为型~观察者模式
[设计模式 Go实现] 行为型~状态模式
[设计模式 Go实现] 行为型~模板方法模式
[设计模式 Go实现] 行为型~策略模式
[设计模式 Go实现] 行为型~职责链模式
[设计模式 Go实现] 行为型~访问者模式
[设计模式 Go实现] 创建型~ 原型模式
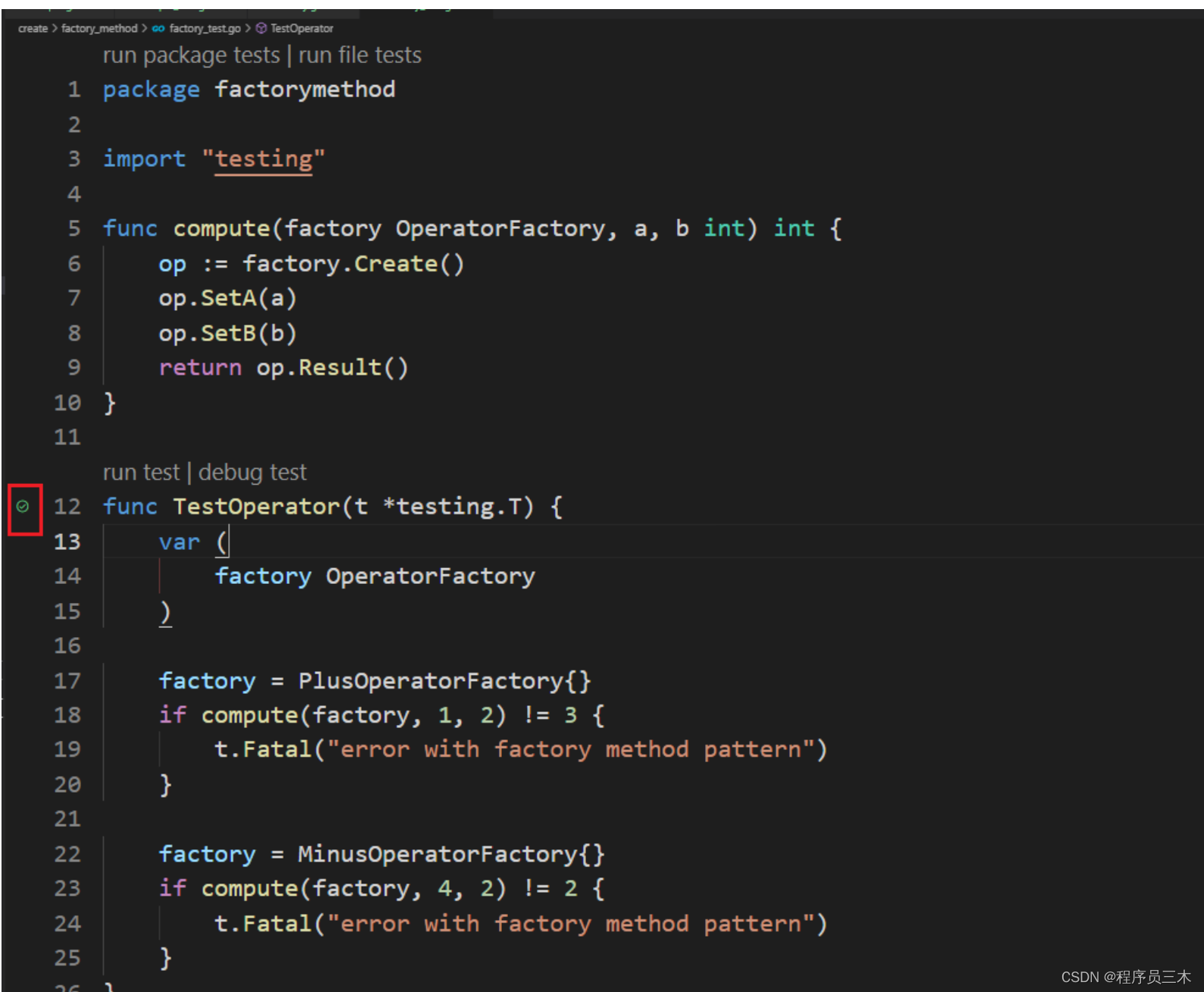
[设计模式 Go实现] 创建型~工厂方法模式
[设计模式 Go实现] 创建型~建造者模式
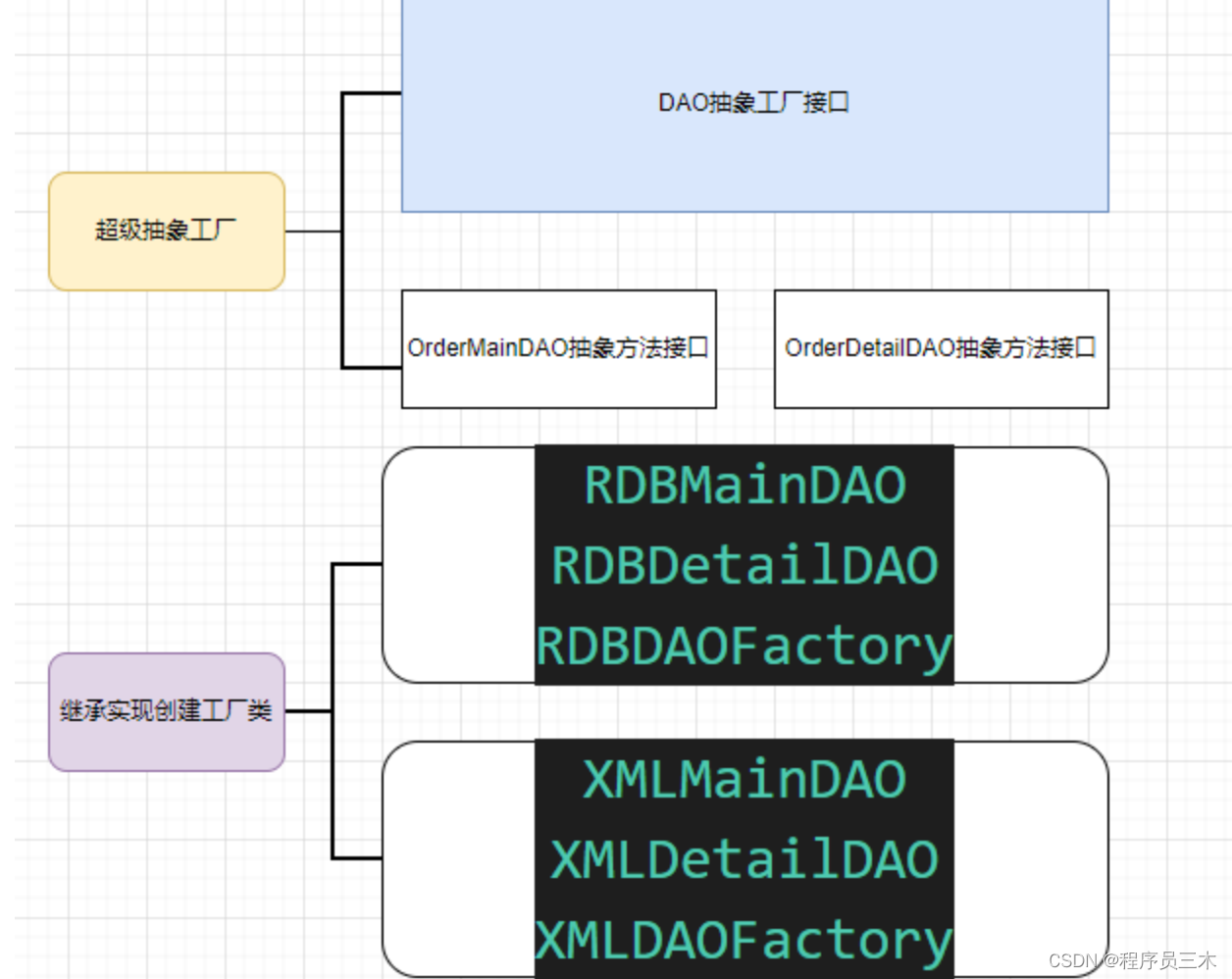
[设计模式 Go实现] 创建型~抽象工厂模式
组合API:掌握Vue的组合式API(Composition API)
[设计模式 Go实现] 创建型~单例模式
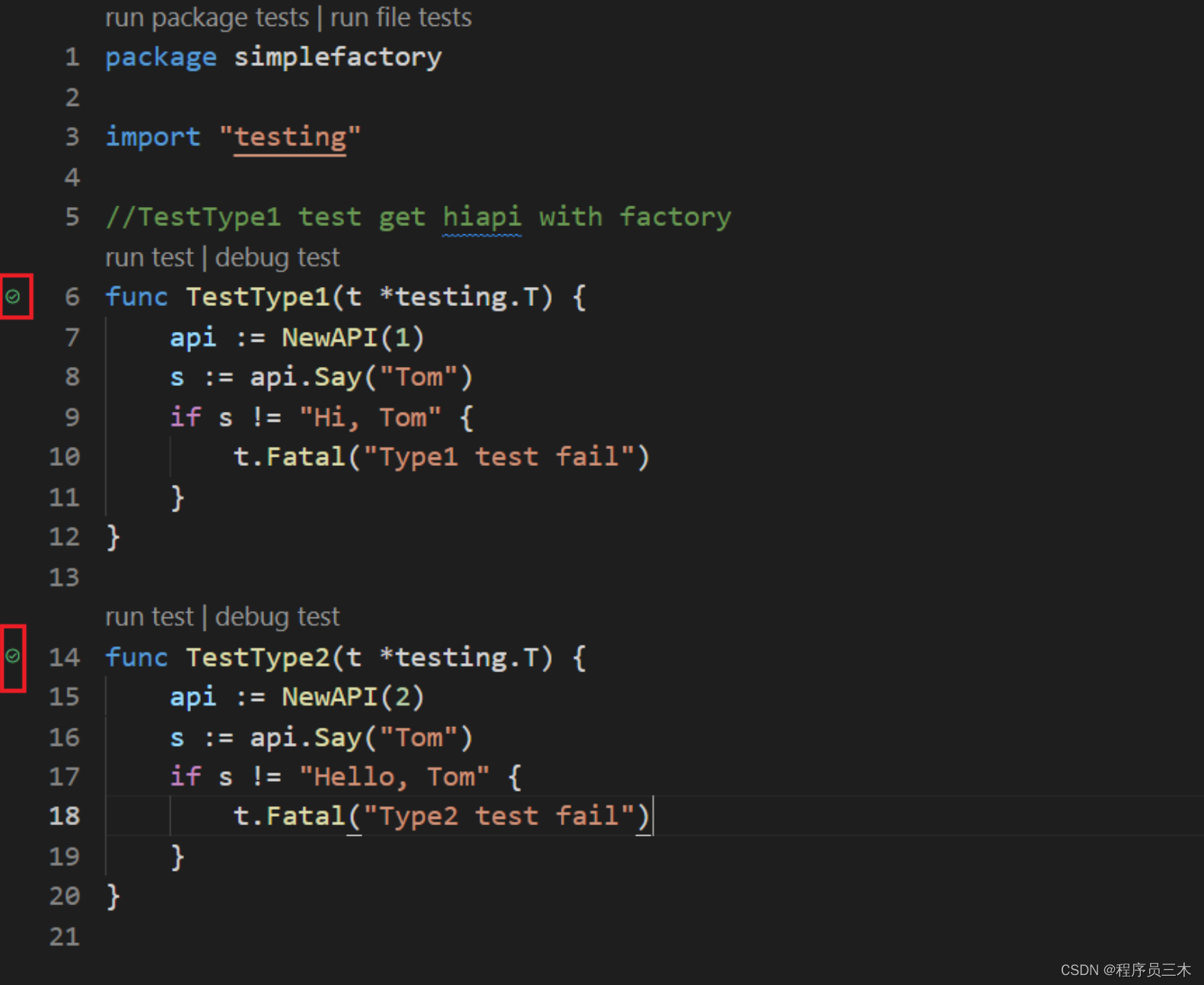
[设计模式 Go实现] 创建型~简单工厂模式
[leetcode ~go]三数之和 M
[leetcode] 四数之和 M
Go语言TCP Socket编程(下)
Python从入门到精通:3.3.2 深入学习Python库和框架:Web开发框架的探索与实践
服务器部署访问出错的原因和解决办法
mysql索引失效的原因以及解决办法
CVPR 2024:分割一切模型SAM泛化能力差?域适应策略给解决了
[云原生] Go web工作流程
从API获取数据并将其插入到PostgreSQL数据库:步骤解析
性能监控之常见JDK命令行工具整理
Python从入门到精通:3.1.1多线程与多进程——进程和线程的概念
Python从入门到精通:2.3.2数据库操作与网络编程——学习socket编程,实现简单的TCP/UDP通信
[云原生] Go 定时器
xiaodisec day020
xiaodisec day019
xiaodisec day018
xiaodisec day017
[云原生] Go并发基础
容器服务 Pod 处于 CrashLoopBackOff的原因及解决方法
xiaodisec day016
为什么Redis使用单线程 性能会优于多线程?
类型检查:结合TypeScript和Vue进行开发
xiaodisec day015
xiaodisec day014
xiaodisec day013
webflux之webclient踩坑tablefield
[AIGC] ArrayList介绍
xiaodisec day012
服务器通信:使用WebSocket与后端实时交互
xiaodisec day 011
xiaodisec day010
Servlet 教程 之 Servlet 编写过滤器 6