先从概念层次介绍下Hadoop的各个组件,下一部分会深入Hadoop的每个组件,并从实战层次讲解。
一、Hadoop构造模块
运行Hadoop的意思其实就是运行一组守护进程(daemons),每个进程都有各自的角色,有的仅运行在单个服务器上,有的则运行在集群多个服务器上,它们包括:
- NameNode
- Secondary NameNode
- DataNode
- JobTracker
- TaskTracker
Hadoop是一个分布式存储与计算系统,分布式存储部分是HDFS,分布式计算部分是MapReduce,它们都是遵循主/从(Master/Slave)结构,上面前3个组件属于分布式存储部分,后面2个组件属于分布式计算部分,下面详细介绍一下它们。
二、NameNode
前面说了,NameNode属于HDFS,它位于HDSF的主端,由它来指导DataNode执行底层I/O任务。NameNode相当于HDFS的书记员,它会跟踪文件如何被分割成文件块,而这些块又是被哪些节点存储,以及分布式文件系统整体运行状态是否正常等。
运行NameNode会消耗大量内存和IO资源,因此为减轻机器负载,驻留NameNode的服务器通常不会存储用户数据或者进行MapReduce计算任务,这也就意味着一台NameNode服务器不会同时是DataNode或者TaskTracker服务器。
不过NameNode的重要性也带来了一个负面影响---单点故障。对于其他任何守护进程,其驻留节点发生软件或硬件故障,Hadoop集群还可平稳运行,但是对于NameNode来说,则不可以。不过后面版本(2.0以后的版本)已经解决此问题。
三、DataNode
集群中每一个从节点都会驻留一个DataNode的守护进程,用来将HDFS数据库写入或读取到本地文件系统中。当对HDFS文件进行读写时,文件会被分割成多个块,有NameNode告知客户端每个数据驻留在哪个DataNode,客户端直接与DataNode进行通信,DataNode还会与其它DataNode通信,复制这些块以实现冗余。

NameNode跟踪源数据,DataNode提供数据块的备份存储并持续不断地向NameNode报告,以保持元数据最新状态。
四、 Secondary NameNode
SNN是一个监测HDFS的辅助进程,它只与NameNode进程通信,根据集群配置时间间隔获取HDFS元数据快照,我们知道HDFS有单点故障,SNN快照有助于减少宕机而导致的数据丢失风险,其一般也单独占一台服务器。
五、 JobTracker
它是应用程序和Hadoop之间的纽带,监控MapReduce作业执行过程,一旦提交代码到集群,JobTracker就会确定执行计划,包括决定处理哪些文件、为不同的任务分配节点以及监控所有任务运行。每个集群只有一个JobTracker进程,一般运行在主节点。
六、 TaskTracker
TaskTracker管理各个任务在从节点上的执行情况。它负责执行有JobTracker分配的单项任务,虽然每个从节点只有一个TaskTracker运行,但每个TaskTracker可以生产多个JVM来并行地处理多Map或Reduce任务。TaskTracker的一个职责是不断的与JobTracker通信,即“心跳”。
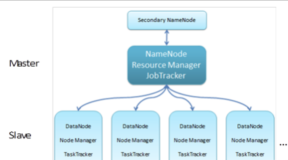
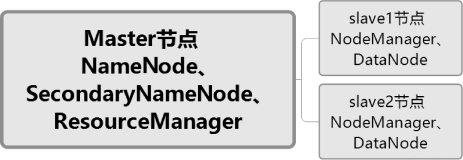
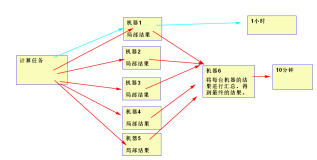
下面再来整体看一下整个Hadoop拓扑结构
下面就是一个典型的Hadoop拓扑图,主动结构,NameNode和JobTracker位于主端,DataNode和TaskTracker位于从端。

客户端向JobTracker发送Job任务,JobTracker会把Job切分,并分配不同的Map和Reduce任务到每一台机器。

想更深一步了解HDFS相关组件,请参考我的另一篇文章:《HDFS架构设计》