本文将介绍 AAAI 2018 中的五篇关于应答生成方面的论文,希望对大家有所启发。

写作动机
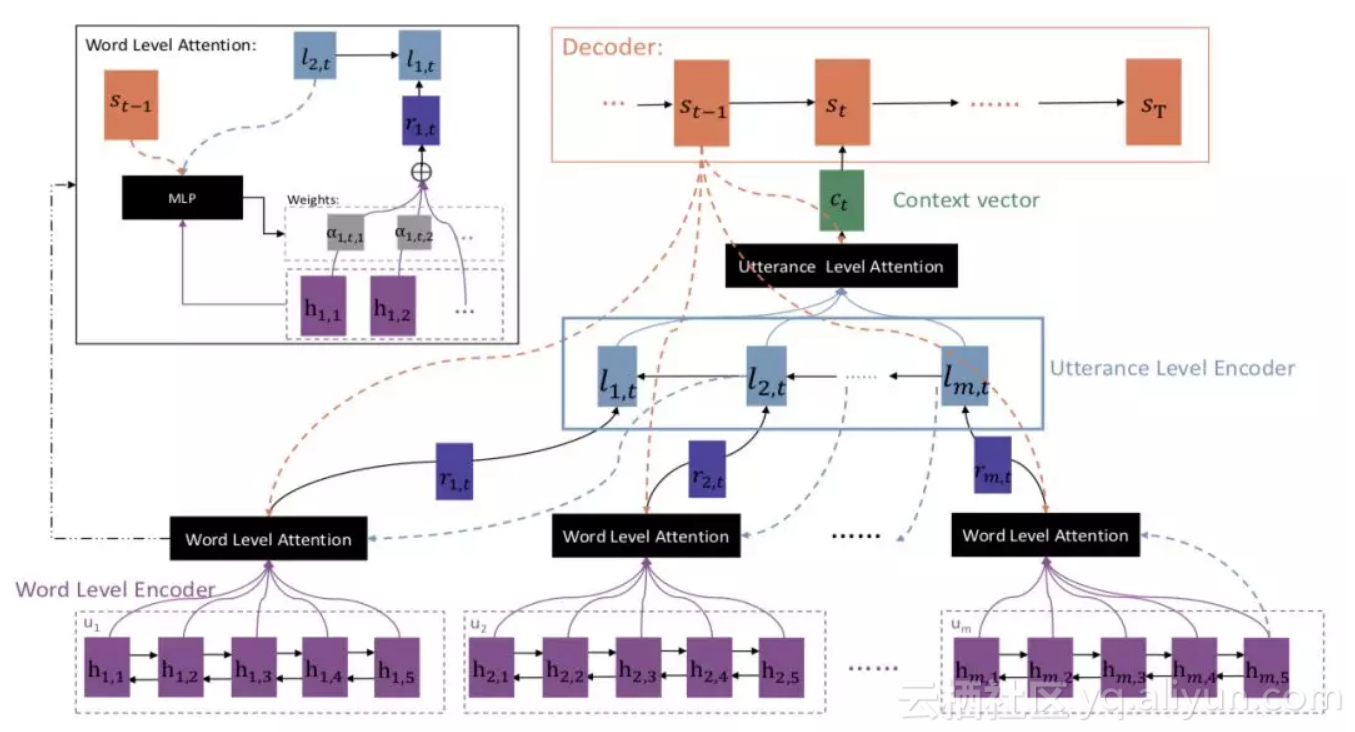
作者认为,虽然之前的论文对多轮对话的层次结构进行了建模,知道应答的生成应该考虑到上下文(context)信息,但是却忽略了一个重要的事实,就是上下文中的句子(utterance)和单词(word)对应答有着不同分量的影响。
所以,作者提出了一种层次化的注意力机制来对多轮对话中不同层面的影响进行刻画,分别是句子级注意力机制(utterance level attention)和单词级注意力机制(word level attention)。
具体模型

写作动机
作者认为,在基于检索的应答生成场景中,加入社会常识可以改善检索结果的质量。
具体模型
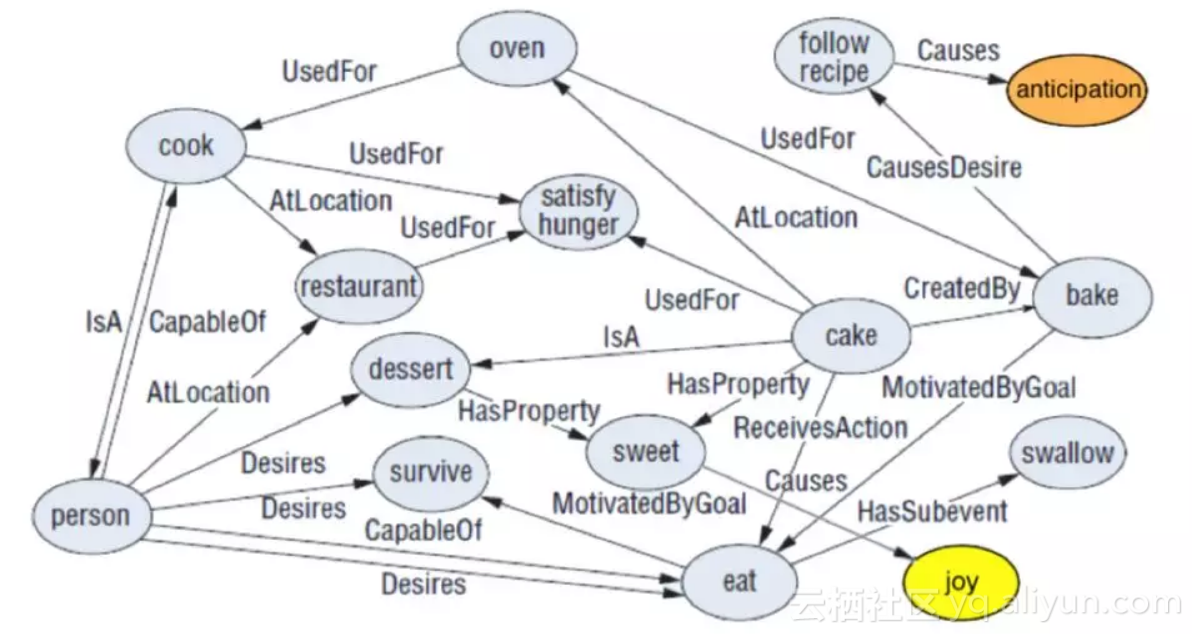
上图表示一个常识库。它是一个语义网络,concept 是它的节点,relation 是它的边,三元组 <concept1,relation,concept2> 称为一个 assertion 。
问题定义
x 是一个message(context), [y1,y2,...,yK]∈Y 是一个应答候选集。
基于检索的应答生成系统就是要选出最合适的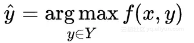 ,其中 f(x,y) 是衡量 x 和 y 之间的“相容性”的函数。
,其中 f(x,y) 是衡量 x 和 y 之间的“相容性”的函数。

那么,如何将常识库融入我们的问题定义中呢?
以上图为例。首先,事先定义好一个 Assertion={c:<c1,relation,c2>} 词典,它的 key 是 concept c ,value 是三元组 assertion <c1,relation,c2> ,其中 c=c1 或者 c=c2 。
然后,论文里又定义一个 Ax ,表示所有与 message(context)x 有关的 assertion 三元组。
这个 Ax 的建立规则是:对 message 文本 取 n-gram(所有uni-gram,bi-gram,...,n-gram)短语,然后从 Assertion 词典选取那些与 n-gram 短语匹配的 key 所对应的 value,加入到 Ax 中。
至此,我们就得到了所有与 message 有关的常识。
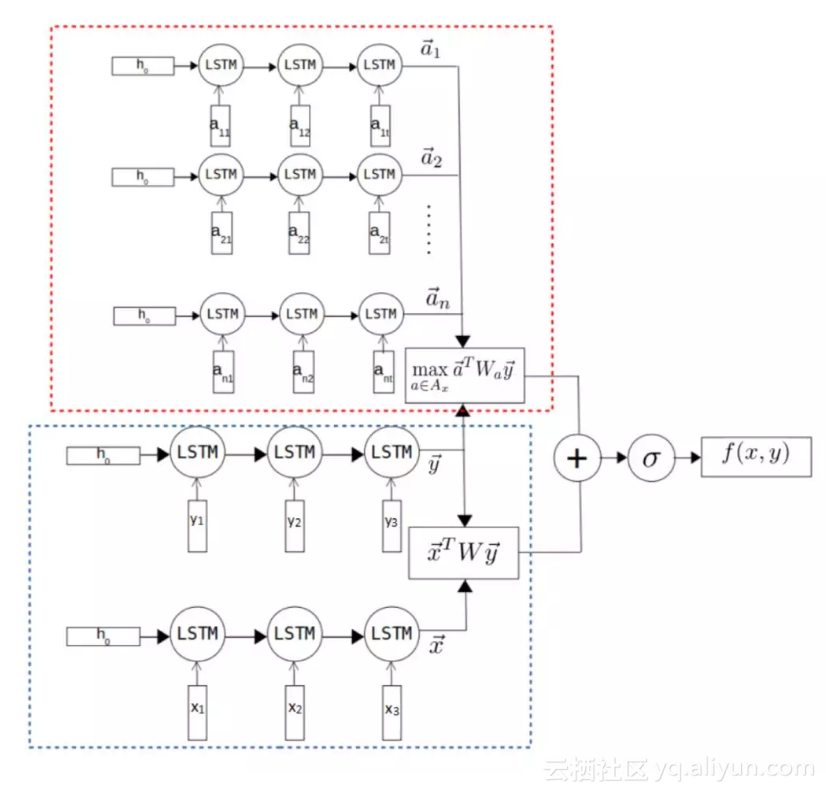
Dual-LSTM Encoder
上图中下面的方框。利用 LSTM 结构对 message x 和 response y 进行编码,得到和
向量,
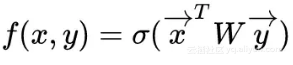 计算两者之间的“相容性”。
计算两者之间的“相容性”。
Tri-LSTM Encoder
上图中上面的方框。因为 c1 和 c2 都有可能是几个单词通过下划线连在一起的concept,所以我们将 c1 拆成 [c11,c12,c13,...] , c2 拆成 [c21,c22,c23,...] ,至于为什么不拆 relation?因为 concept 是由多个常见词连接起来的单词,如果将这个合成词直接作为词典中的单词,那么词典将会很大,而 relation 则没有几种。
最终,三元组 <c1,r,c2> 将变为 [c11,c12,c13,...,r,c21,c22,c23,...] 的序列,我们对每个 assertion 序列利用 LSTM 进行编码,得到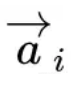 向量,然后,我们取 response 与所有常识“相容性”最大的值
向量,然后,我们取 response 与所有常识“相容性”最大的值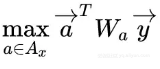 。
。
最后,将两个 Encoder 的“相容性”值加起来,最终选择总和最大的 response。

写作动机
作者认为,以前的生成模型在生成单词时,模型需要遍历整个词典。如果词典非常大,那么每次遍历都非常耗时。所以,作者提出,每次生成单词时,都可以根据输入的情况灵活地选择需要遍历的词典的大小以及它里面的词,这样将可以节省大量时间。
具体模型
问题定义

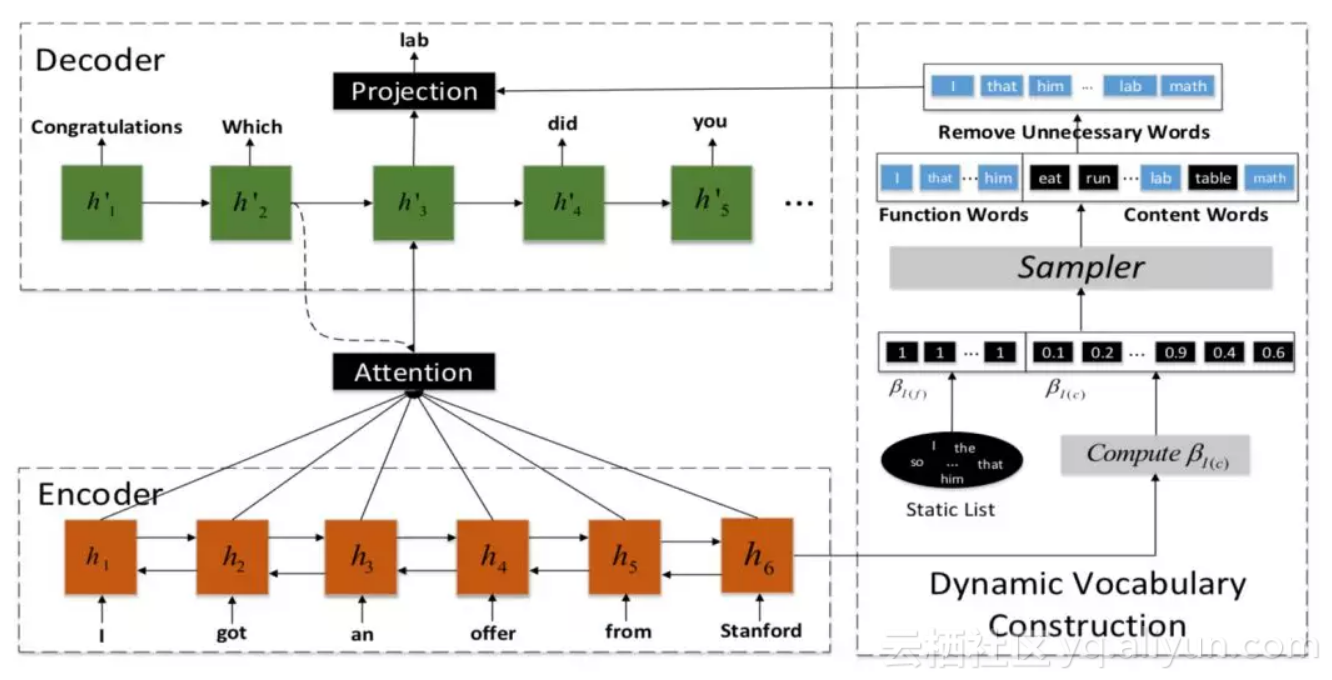
那么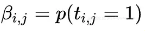 又是怎么得到呢?
又是怎么得到呢?
如上图,在词典 V 中,单词可以分为两类:function words 和 content words。
其中,function words 出现 10 次以上,除了名词、动词、形容词、副词,它们保证了 response 的语法正确性和流畅性,在每个 response 中都可能出现,所以,这些单词的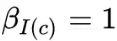 , I(c) 是这些单词的索引;content words 则是词典中其他的词,它们的
, I(c) 是这些单词的索引;content words 则是词典中其他的词,它们的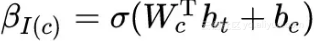 。
。
最后,根据得到的多元伯努利分布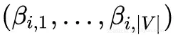 随机采样得到 Ti ,进而得到目标词典。得到词典后,剩下的过程则和以前传统的过程类似了。
随机采样得到 Ti ,进而得到目标词典。得到词典后,剩下的过程则和以前传统的过程类似了。

写作动机
这篇论文解决的问题是,基于检索的应答生成场景下如何从候选应答集选择合适应答的难题。论文使用的方法是多臂老虎机模型。
多臂老虎机模型
一个赌徒,要去摇老虎机,走进赌场一看,一排老虎机,外表一模一样,但是每个老虎机吐钱的概率不一样,他不知道每个老虎机吐钱的概率分布是什么,那么想最大化收益该怎么办?这就是多臂赌博机问题(Multi-armed bandit problem, K-armed bandit problem, MAB)。
如何解决呢?论文中使用的是汤普森抽样方法。
假设每个臂产生收益的概率为 p,我们不断地试验,去估计出一个置信度较高的*概率p的概率分布*就能近似解决这个问题了。
怎么估计概率 p 的概率分布呢? 假设概率 p 的概率分布符合 beta (wins, lose) 分布,它有两个参数:wins,lose。
每个臂都维护一个 beta 分布的参数。每次试验后,选中一个臂,摇一下,有收益则该臂的 wins 增加 1,否则该臂的 lose 增加 1。
每次选择臂的方式是:用每个臂现有的 beta 分布产生一个随机数 b,选择所有臂产生的随机数中最大的那个臂去摇。
具体模型
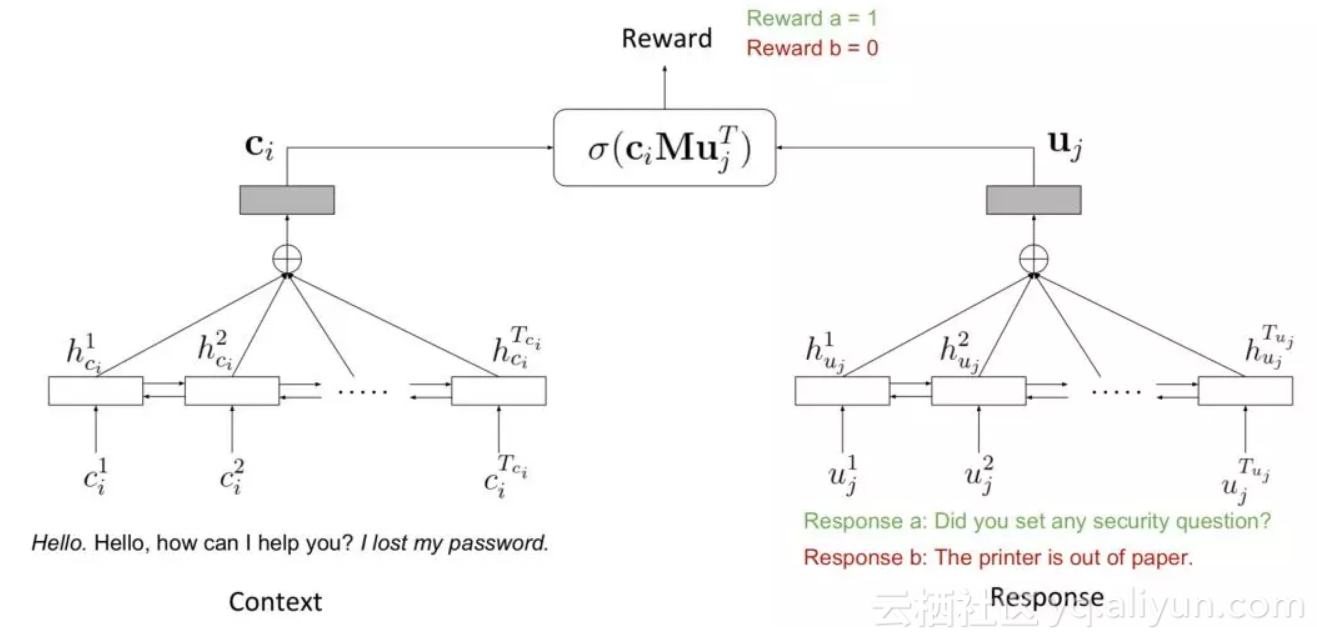
如上图,左边是 context,使用双向 LSTM 编码, ci 表示 context 向量,等于所有单词向量的平均和。右边是 response,也使用双向 LSTM 编码, uj 表示 response 向量,等于所有单词向量
的平均和。如果是传统的离线学习过程,那么训练过程应该为:
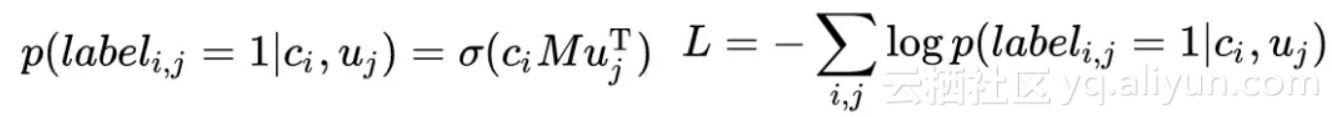
对损失做反向传播即可。
但本文解决的是在线学习场景,模型随机选择一个 context,然后检索到一个 response,用户对这个选择做出打分,正确则 reward=1,错误则 reward=0。然后,作者企图利线性逻辑回归汤普森采样对 reward 进行拟合。

写作动机
作者觉得,生成 response 时应该生成多种 style 的 response,所以,作者提出了一种 Elastic Responding Machine (ERM) 模型,生成多种类型的 response。
具体模型
-
Encoder-Decoder
-
Encoder-Diverter-Decoder
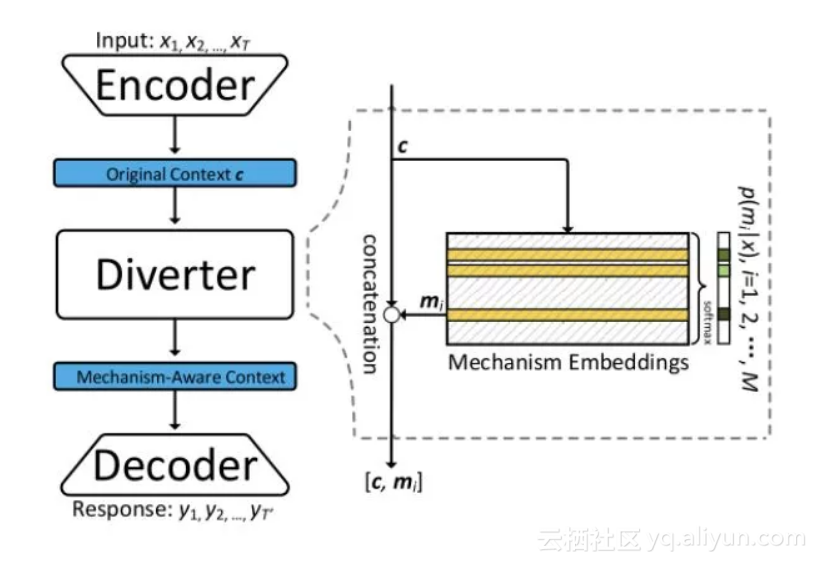
这个模型来自 Zhou et al. 2017 的 Mechanism-Aware Neural Machine for Dialogue Response Generation。表示 M 个 mechanism 的集合,mechanism 可以理解为 style。
Diverter 的作用是选出最适合 context c 的 mechanism,通过公式:
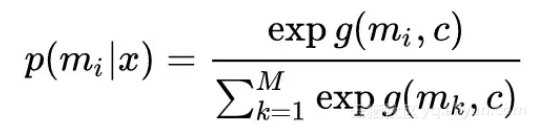
选择评分最高的 mechanism,最终生成 response y 的概率为:
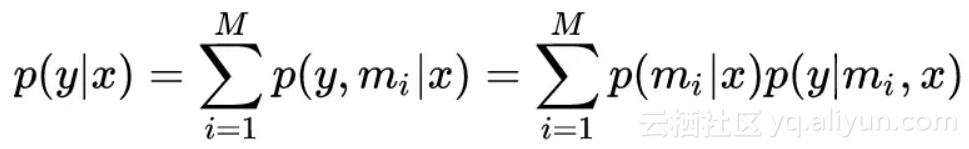
-
Encoder-Diverter-Filter-Decoder
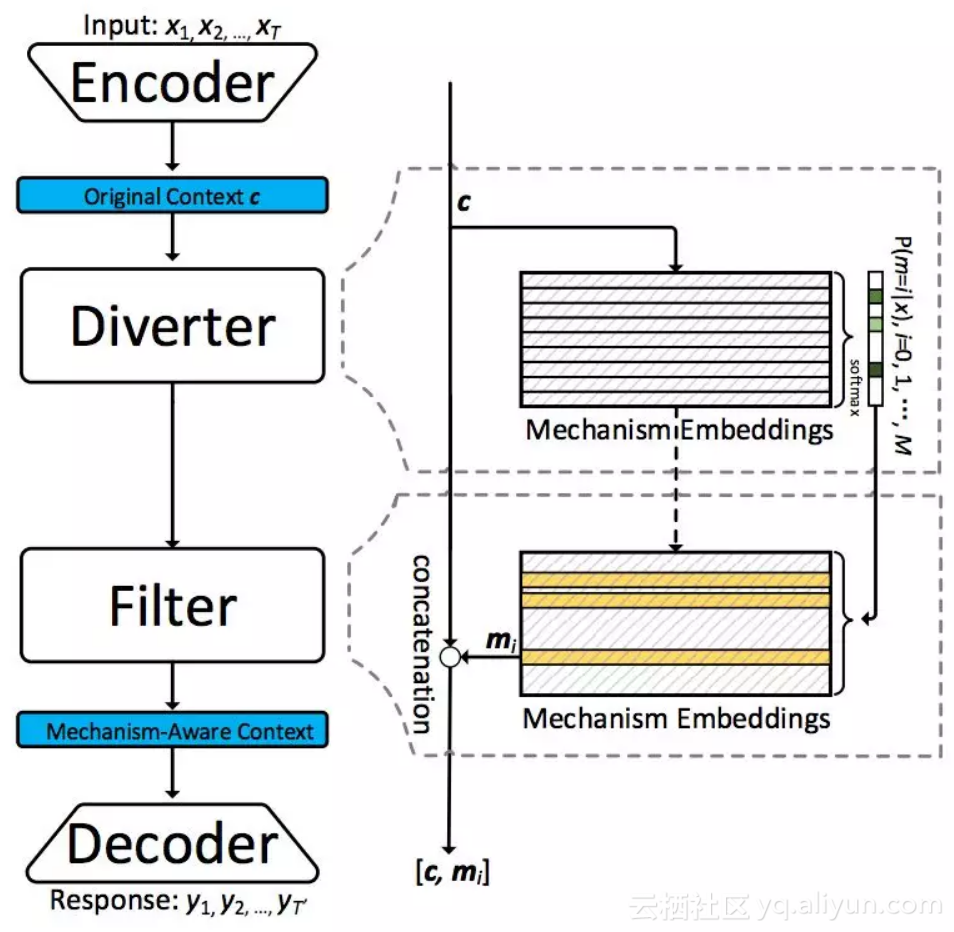
本文作者在前文的基础上,又加入了 Filter 模块,作者的目的是从所有 mechanism 集合中选出一个子集 Sx ,包含足够多的 mechanism,能够生成多种 style 的 response。
这个子集 Sx 需要满足两个条件:1)包含足够多的 mechanism;2)子集的 mechanism 没有太高的重复性,没有冗余。选中了子集 Sx 后,生成 response y 的概率为:
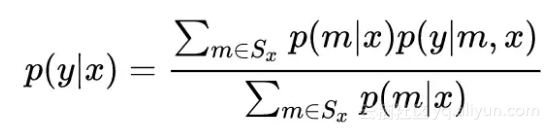
那么,怎么选择子集 Sx 呢?论文使用的是强化学习的方法。
Action:at 表示停止动作, ac 表示继续动作;
State: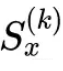 表示子集中包含 top k 个 mechanism 的状态;
表示子集中包含 top k 个 mechanism 的状态;
Policy: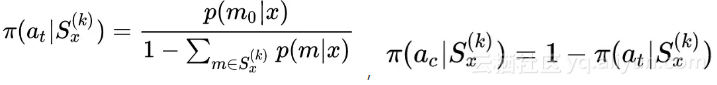 ,m0 表示停止的 mechanism;
,m0 表示停止的 mechanism;
Reward:作者认为,如果子集没有达到要求的 K 个 mechanism 的规模,则没有奖励。
![]()
选出包含 K 个 mechanism 之后,依次将 c 和 mi (mi∈Sx) 连接在一起输入到 decoder 中生成各自 mechanism 对应的 response。下面是具体的算法流程: