本文主要记录了fair调度器drf调度策略作业不执行问题的解决过程,重点介绍了调查方法和调查过程细节,希望对大家了解fair调度器有所帮助 。
除本人知乎专栏外,转载请联系我。
一.问题背景
yarn的调度器有capacity和fair两种,之间的区别可以自行谷歌。fair调度器(附录1)是企业级hadoop用户常用的资源池类型,该调度器默认的队列内部调度策略(SchudelingPolicy)是fair,即分配资源时只考虑内存限制。
对一个跨部门多个团队共同使用的大集群来说,如果存在cpu密集型作业,不进行cpu控制肯定会影响其他作业的运行。想要在分配资源时同时计算内存和cpu限制,需要指定队列的调度策略为drf,即DominantResourceFainessPolicy(附录2)。一般配合cgroup使用,控制容器实际的cpu资源(附录3)。
使用drf时遇到一个问题,配置非常简单的一个fair-scheduler示例,但作业提交后不分配资源。
配置如下:
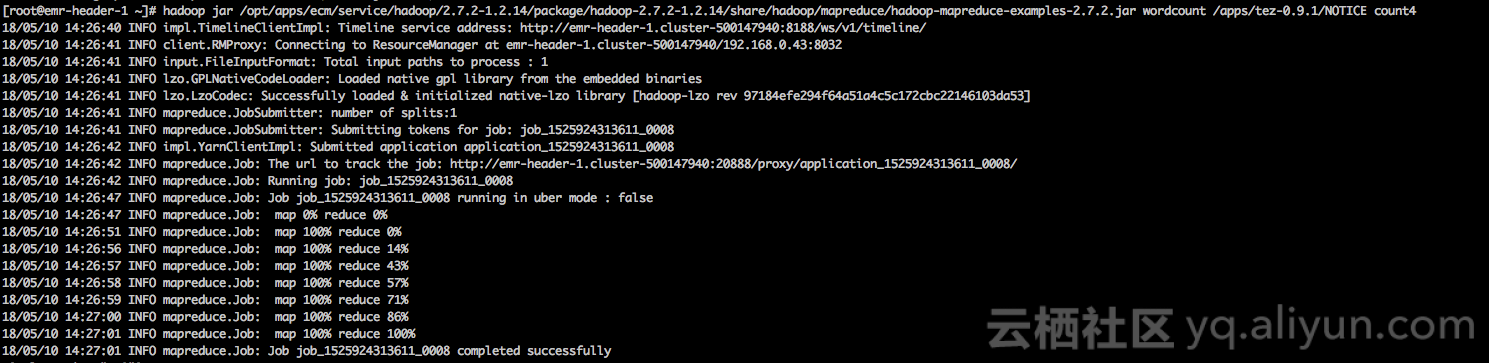
运行wordcount卡住

将调度策略由drf改成fair或不设置(默认还是fair),作业运行正常
下面详细分析调查过程,不关心分析过程的可直接看五.结论章节。
二.发现表象原因
1. 查fair官网文档,没发现有什么问题。
2. 搜谷歌,没找到类似问题。搜github hadoop的issue,也没找到类似问题。
3. 看了官网文档和其他技术网站的各种示例,灵光一闪,将queue的name从default换成root,作业运行正常了。难道是不能叫default?
4. 尝试queue的name为“defaul”等等,作业都正常。就是default不行。但调度策略换回fair后,default可以。
5. 搜hadoop源码,没找到有类似对default做特殊业务处理的地方。
6. 测试集群用的emr-hadoop 2.7.2版本,是hadoop定制版。换成apache原生的hadoop 2.7.2,queue名字为default作业也不运行。说明原生hadoop也有同样问题。
那么为什么队列叫default作业就不运行呢?
三.深入调查的方法
通过加打印日志的方式定位问题。
1. 下载hadoop源码(附录四),fair调度器的源码在./hadoop-yarn-project/hadoop-yarn/hadoop-yarn-server/hadoop-yarn-server-resourcemanager子项目下,org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair包里。
2. 参考一些源码分析的文章(附录五,六,七)看fair调度器的源码,在合适的地方加打印日志。
3. 对子项目打包,执行mvn package –DskipTests,target目录下生成hadoop-yarn-server-resourcemanager-2.7.2.jar。
4. 上传到服务器,代替hadoop目录下的share/hadoop/yarn/hadoop-yarn-server-resourcemanager-2.7.2.jar。
5. 重启resourcemanager。
6. 修改fair-scheduler的配置,提交作业,查看resourceManager的日志输出。
四.调查过程
4.1作业为什么不执行
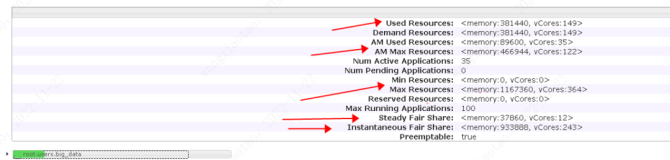
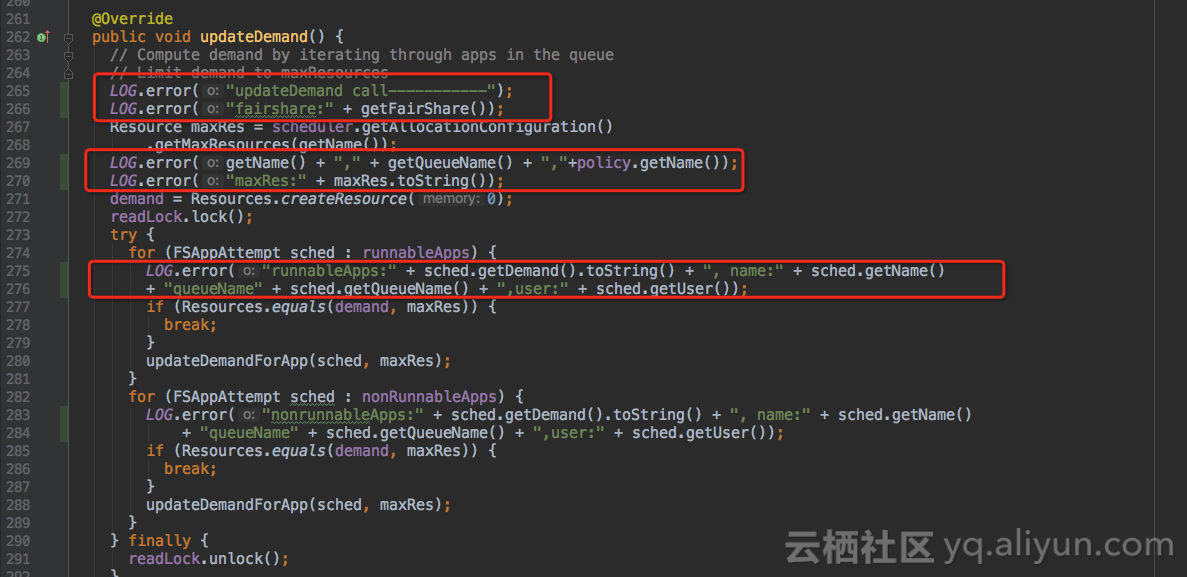
FSLeafQueue类的updateDemand()方法会刷新子队列的资源请求,加打印如图,查看队列实时资源,队列名,调度策略,最大资源,作业信息等。
看日志发现,
1. 不管配置文件的队列名是什么,作业都提交给了root.default这个队列。说明作业默认都是提交到这个队列。
2. 该队列的实时资源fairShare只有内存,vcores一直是0.
3. 当配置文件显式配置了default队列调度策略为drf时,root.default队列的调度策略为drf。作业申请AM要一个vcores资源,没资源一直等待。
4. 当配置文件没显式配置default时,root.default队列的调度策略为默认的fair,作业申请AM只计算内存资源,成功分配资源。
那么只有root.default这个队列会vcores一直为0吗?
配置文件设置另一个队列test,调度策略为drf,作业提交时指定test队列:
hadoop jar /opt/apps/ecm/service/hadoop/2.7.2-1.2.14/package/hadoop-2.7.2-1.2.14/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar
wordcount -D mapreduce.job.queuename=test /apps/tez-0.9.1/NOTICE count10
发现依然vcores为0,作业一直等待。
作业不执行的原因确定了,是队列一直没有vcores资源。drf调度策略,am需要一个vcores资源,没有就一直等待资源。那为什么所有队列都没有vcores资源呢?
4.2.队列为什么没有vcores资源
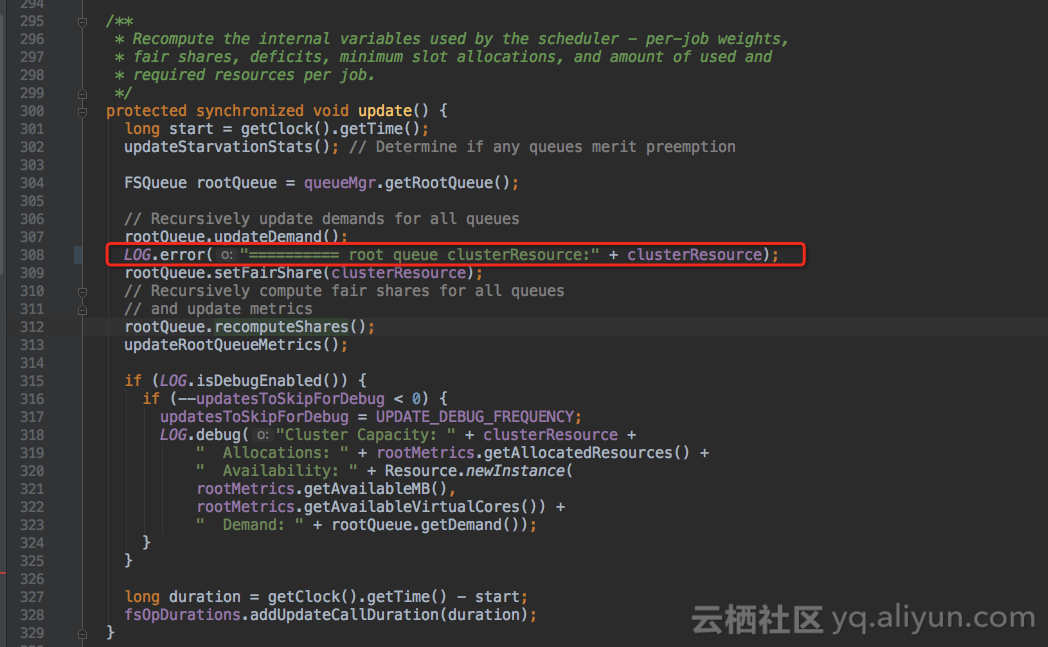
继续加打印,FairScheduler类的update()方法会更新各队列的资源分配,加打印查看root根队列的集群资源。
ComputeFairShares类的computeShares()方法会计算队列内部各子队列/作业的资源分配,加打印。
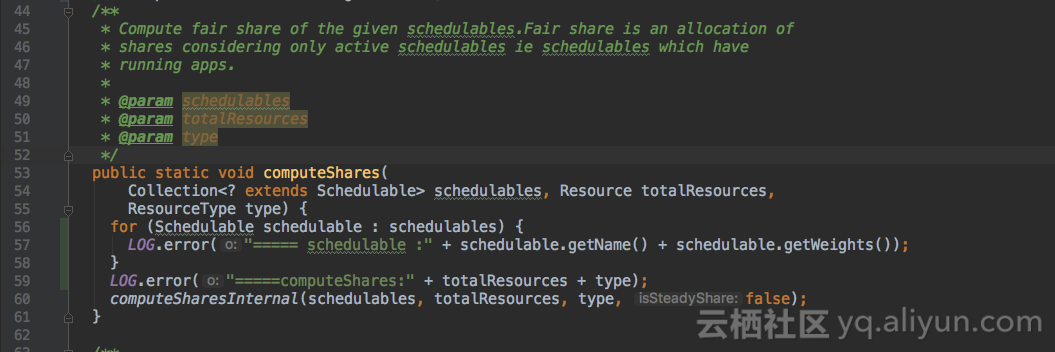
日志看到,root根队列的集群资源是有vcores的,但root.default队列一直没有分配到vcores资源!
继续加打印,FSLeafQueue类和FSParentQueue类的recomputeShares()方法是重新计算队列内部资源的入口,加打印。
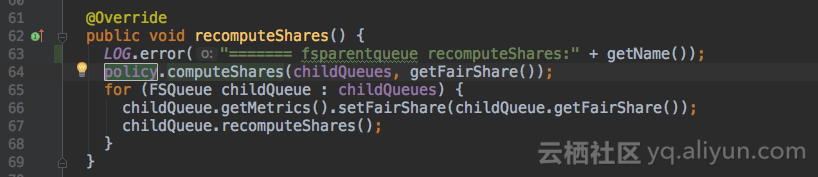
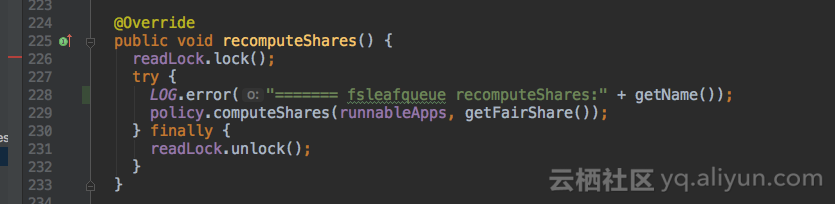
终于发现问题了,root根队列调度策略是默认的fair,给子队列分配资源时,FairSharePolicy类的computeShares()方法只会分配内存类型的资源,所以root.default队列只有内存资源,一旦配置子队列调度类型为drf计算vcores资源,会因为没有vcores资源一直等待。

验证,配置文件配置root和default两个队列,调度策略都是drf。提交作业到default队列,正常运行,日志显示default队列分配到了vcores资源。
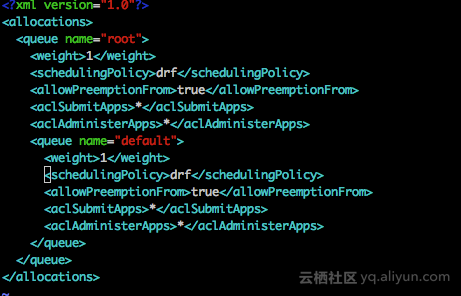
4.3.调度器初始化细节
QueueManager类的initialize()方法,会用队列默认属性初始化了一个root根队列,和一个root.default子队列。

配置文件里写的队列名的规则是如果不是以root.开头或就是root,就增加“root.”前缀放到root根队列下。

读配置文件时,如果有root队列或default/root.default队列,会覆盖这两个队列的默认配置。
五.结论
如果想用drf调度策略计算vcores资源,那么必须从root根队列递归到叶子队列,显式配置所有队列调度策略都为drf。如果父队列没配置用了默认fair,那么只会给子队列分配内存资源,子队列用drf调度策略作业就都会没资源卡住。
六.Fair调度器源码详解
待补充
七.附录
1. fair调度器官方文档
3. yarn的cpu资源隔离
4. hadoop源码
6. fair调度器源码分析