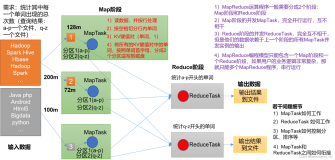
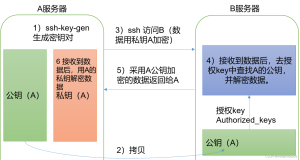
以EMR-2.0.1为例,对E-MapReduce的集群环境做个总结介绍
- E-MapReduce环境变量
登录集群,输入env 命令即可看到环境变量。跟hadoop相关的如下
JAVA_HOME=/usr/lib/jvm/java HADOOP_HOME=/usr/lib/hadoop-current HADOOP_CLASSPATH=/usr/lib/hbase-current/lib/*:/usr/lib/tez-current/*:/usr/lib/tez-current/lib/*:/etc/emr/tez-conf:/usr/lib/hbase-current/lib/*:/usr/lib/tez-current/*:/usr/lib/tez-current/lib/*:/etc/emr/tez-conf:/opt/apps/extra-jars/*:/opt/apps/extra-jars/* HADOOP_CONF_DIR=/etc/emr/hadoop-conf SPARK_HOME=/usr/lib/spark-current SPARK_CONF_DIR=/etc/emr/spark-conf HBASE_HOME=/usr/lib/hbase-current HBASE_CONF_DIR=/etc/emr/hbase-conf HIVE_HOME=/usr/lib/hive-current HIVE_CONF_DIR=/etc/emr/hive-conf PIG_HOME=/usr/lib/pig-current PIG_CONF_DIR=/etc/emr/pig-conf TEZ_HOME=/usr/lib/tez-current TEZ_CONF_DIR=/etc/emr/tez-conf ZEPPELIN_HOME=/usr/lib/zeppelin-current ZEPPELIN_CONF_DIR=/etc/emr/zeppelin-conf HUE_HOME=/usr/lib/hue-current HUE_CONF_DIR=/etc/emr/hue-conf PRESTO_HOME=/usr/lib/presto-current PRESTO_CONF_DIR=/etc/emr/presot-conf
- E-MapReduce 应用启停
- yarn
yarn的操作,都需要在hadoop账号下进行 su hadoop;ResourceManager/usr/lib/hadoop-current/sbin/yarn-daemon.sh start|stop resourcemanager
NodeManager/usr/lib/hadoop-current/sbin/yarn-daemon.sh start|stop nodemanager
JobHistoryServer/usr/lib/hadoop-current/sbin/mr-jobhistory-daemon.sh start|stop historyserver
WebProxyServer/usr/lib/hadoop-current/sbin/yarn-daemon.sh start|stop proxyserver
-
- hdfs
hdfs的操作,都需要在hdfs账号下进行 su hdfsNameNode/usr/lib/hadoop-current/sbin/hadoop-daemon.sh start|stop namenode
DataNode/usr/lib/hadoop-current/sbin/hadoop-daemon.sh start|stop datanode
-
- hbase
hbase的操作,都需要在hdfs账号下进行 su hdfsHMaster/usr/lib/hbase-current/bin/hbase-daemon.sh start master
HRegionServer/usr/lib/hbase-curren/bin/hbase-daemon.sh start regionserver
-
- hive
hive的操作,都需要在hadoop账号下进行 su hadoopMetaStoreHADOOP_HEAPSIZE=512 /usr/lib/hive-current/bin/hive --service metastore >/dev/null 2>&1 &HiveServer2
HADOOP_HEAPSIZE=512 /usr/lib/hive-current/bin/hive --service hiveserver2 >/dev/null 2>&1 &
-
- presto
presto 的操作,都需要在hdfs账号下进行 su hdfsPrestoServermaster节点/usr/lib/presto-current//bin/launcher --config=/usr/lib/presto-current/etc/worker-config.properties start|stop
worker节点/usr/lib/presto-current//bin/launcher --config=/usr/lib/presto-current/etc/coordinator-config.properties start|stop
- 小技巧
当需要对worker节点做统一操作时,可以写脚本命令,一键轻松解决左右问题。在EMR集群中,master到所有worker节点在hadoop和hdfs账号下是ssh打通的。
例如 需要对所有worker节点的nodemanager做停止操作,假设有n个worker节点,则可以这样做
for i in `seq 1 2`;do ssh emr-worker-$i /usr/lib/hadoop-current/sbin/yarn-daemon.sh stop nodemanager;done