目录
1. 背景
GPU在高性能计算和深度学习加速中扮演着非常重要的角色, GPU的强大的并行计算能力,大大提升了运算性能。随着运算数据量的不断攀升,GPU间需要大量的交换数据,GPU通信性能成为了非常重要的指标。NVIDIA推出的GPUDirect就是一组提升GPU通信性能的技术。但GPUDirect受限于PCI Expresss总线协议以及拓扑结构的一些限制,无法做到更高的带宽,为了解决这个问题,NVIDIA提出了NVLink总线协议。
这个系列文章会对以上GPU通信技术做详细的介绍,旨在帮助开发者更好的利用这些技术对自己的应用做相应的优化。
本篇文章会先介绍一下GPUDirect技术,并着重介绍GPUDirect Peer-to-Peer(P2P)技术。
2. GPUDirect介绍
2.1 简介
GPUDirect技术有如下几个关键特性:
- 加速与网络和存储设备的通信:
- GPU之间的Peer-to-Peer Transers
- GPU之间的Peer-to-Peer memory access
- RDMA支持
- 针对Video的优化
下面对最主要的几个技术做分别介绍。
2.2 Shared Memory
2010年6月最先引入的是GPUDirect Shared Memory 技术,支持GPU与第三方PCI Express设备通过共享的pin住的host memory实现共享内存访问从而加速通信。
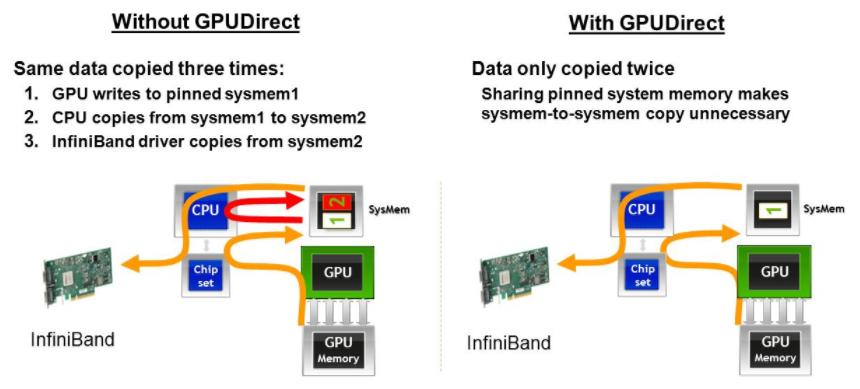
2.3 P2P
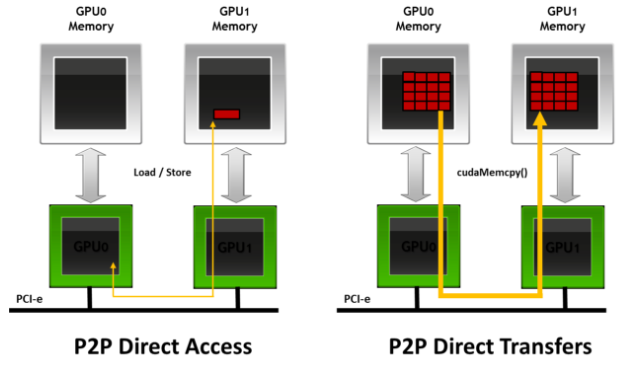
2011年,GPUDirect增加了相同PCI Express root complex 下的GPU之间的Peer to Peer(P2P) Direct Access和Direct Transers的支持。
2.4 RDMA
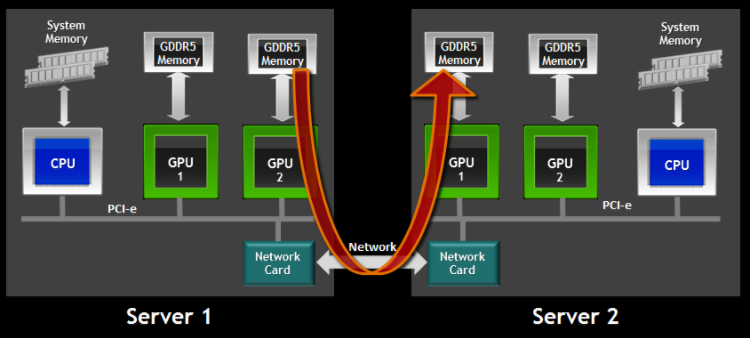
2013年,GPUDirect增加了RDMA支持,使得第三方PCI Express设备可以bypass CPU host memory直接访问GPU。
3. GPUDirect P2P
3.1 P2P简介
GPUDirect Peer-to-Peer(P2P) 技术主要用于单机GPU间的高速通信,它使得GPU可以通过PCI Express直接访问目标GPU的显存,避免了通过拷贝到CPU host memory作为中转,大大降低了数据交换的延迟。
以深度学习应用为例,主流的开源深度学习框架如TensorFlow、MXNet都提供了对GPUDirect P2P的支持,NVIDIA开发的NCCL(NVIDIA Collective Communications Library)也提供了针对GPUDirect P2P的特别优化。
通过使用GPUDirect P2P技术可以大大提升深度学习应用单机多卡的扩展性,使得深度学习框架可以获得接近线性的训练性能加速比。
3.2 P2P虚拟化
随着云计算的普及,越来越多技术迁移到云上,在云上使用GPUDirect技术,就要解决GPUDirect虚拟化的问题。
这里我们着重讨论下GPUDirect Peer-to-Peer虚拟化的问题
使用PCI Pass-through虚拟化技术可以将GPU设备的控制权完全授权给VM,使得虚拟机里的GPU driver可以直接控制GPU而不需要Hypervisor参与,性能可以接近物理机。
但是同一个虚拟机内的应用却无法使用P2P技术与其它GPU实现通信。下面分析一下无法使用P2P的原因。
首先我们需要知道一个技术限制,就是不在同一个Intel IOH(IO Hub)芯片组下面PCI-e P2P通信是不支持的,因为Intel CPU之间是QPI协议通信,PCI-e P2P通信是无法跨QPI协议的。所以GPU driver必须要知道GPU的PCI拓信息,同一个IOH芯片组下面的GPU才能使能GPUDiret P2P。
但是在虚拟化环境下,Hypervisor虚拟的PCI Express拓扑结构是扁平的,GPU driver无法判断真实的硬件拓扑所以无法开启GPUDirect P2P。
为了让GPU driver获取到真实的GPU拓扑结构,需要在Hypervisor模拟的GPU PCI配置空间里增加一个PCI Capability,用于标记GPU的P2P亲和性。这样GPU driver就可以根据这个信息来使能P2P。
另外值得一提的是,在PCI Pass-through时,所有的PCI Express通信都会被路由到IOMMU,P2P通信同样也需要路由到IOMMU,所以Pass-through下的P2P路径还是会比物理机P2P长一点,延迟大一点。
4. 实测
下面是我们在阿里云GN5实例(8卡Tesla P100)上对GPUDirect P2P延迟做的实测数据。
GPU P2P矩阵如下:

通信延迟对比如下:
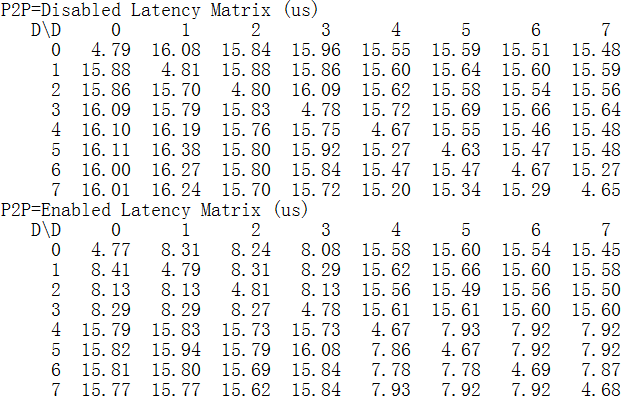
我们看到:使能GPUDirect P2P后GPU间通信延迟相比CPU拷贝降低近一半。
下图是在GN5实例上使用MXNet对经典卷积神经网络的图像分类任务的训练性能的加速比:
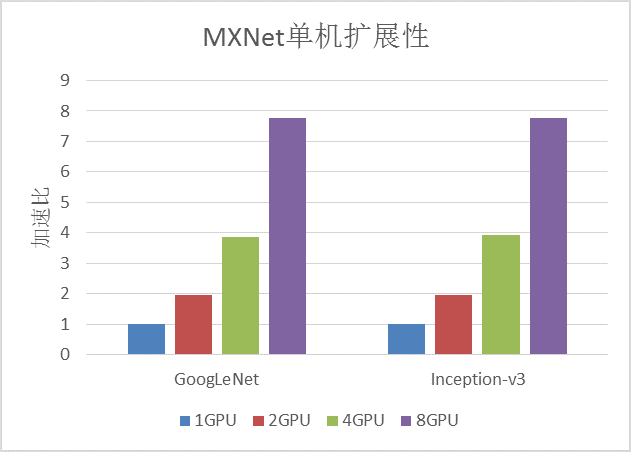
MXNet在支持P2P的GN5实例上有非常好的单机扩展性,训练性能接近线性加速。






