数十款阿里云产品限时折扣中,赶快点击这里,领券开始云上实践吧!
以下为精彩视频内容整理:
超大规模的全球网络
目前,运行在阿里云网络上的阿里云产品已经多达上百种,并且,阿里云部署的地区已经从原来国内的几个城市和region发展到现在遍布全球多个国家和地区,阿里云网络作为最基础的设施,需要负责将所有地区的阿里云产品连接起来,还需要为这些阿里云产品提供高质量的多种互联网访问方式,让阿里云用户能够从多个地方快速高效的访问云上产品。
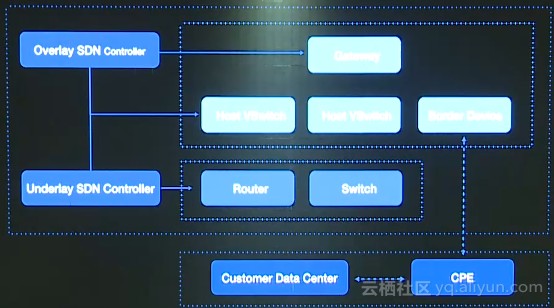
阿里云网络是基于SDN思想设计和实现的,大概分为两大部分,overlay和underlay。在overlay中,有一些我们自研的虚拟网络组件,包括SDN控制器、虚拟网关、host vswitch;underlay中有一系列的物理网络设备,包括物理路由器、物理交换机等。我们的host vswitch性能非常高,领先于业界,是我们实现东西向流量的关键,同时,虚拟化网关让云可以南北下访问,最后,虚拟关键设备是实现云上云下互动的关键。
超大规模的全球网络由数百万级网络设备、数千万级网络实例、1000+个网络指标组成,各种各样的网络产品在上面分配的IP正常运行在我们的网络上,上千个网络指标,每种指标都有自己不同的含义,不同的指标之间有不同的关系,如何管理好这样一张大网?这是非常具有挑战性的。我们想要知道任何时刻这张网络是否有异常,希望知道整张网络的运行状况,从全球的状况到每台设备、每台实例的状况,我们都想要知道。随着业务的快速发展,我们也希望了解我们的网络资源是否满足下一个月或季度的规划,资源质量如何,供应商为我们提供的互联网访问能力如何等,这些都需要我们去分析和解决。
为了解决以上问题,我们基于大数据技术,结合多年网络工作经验,设计并实现了一套数据分析系统,它可以帮助我们智能管理好这张网络。其特点是可以吞吐海量网络数据,并将这些网络数据转化成可视化的信息和决策,帮助我们诊断网络中的问题,了解网络上的运行状况,以及帮助我们规划网络中的发展方向。
数据驱动的智能网络-齐天
我们称设计的这套智能网络为齐天,寓意从天空的角度来看这张网络,从整个地球到每一台设备都可以看得清清楚楚。齐天智能网络包括以下四个部分:
1.网络大盘。了解阿里云网络运行状况,了解每个网络、每个实例的用户正在发生什么事情。
2.网络异常。多维度了解阿里云网络异常情况,实时监控阿里云网络稳定性。
3.网络资源。提取规划阿里云网络资源,让我们及时知道有的地方资源不够,有的地方互联网质量下降,有的地方连接用户专线侧网络出现抖动等情况,及时 联系合作运营商,帮助用户解决资源质量上的问题。
4.网络运营。结合BI团队的技术和经验,融合我们对网络的理解,来分析我们的网络产品、成本和用户画像,了解用户如何使用我们的产品,了解我们产品的发展情况,了解用户如何在云上部署网络应用的。
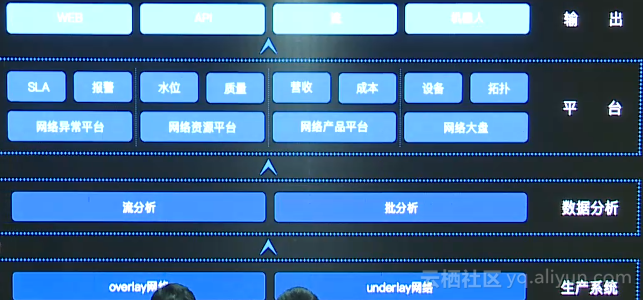
齐天1.0产品架构如图所示,最底层为虚拟和物理网络生成组件,包括overlay和underlay两块,overlay和underlay组件会产生海量的网络数据,这些数据非常原始,大多以指标或日志形式推给上层,数据分析系统会实时消费这些网络数据和日志,并将这些网络数据进行清洗、聚合、加工以及多维度计算后生成语义丰富的多维度网络数据,这些网络数据随后会进入各类离线数据分析中,包括时序分析数据和Maxcompute数据分析等。经过这些分析后,我们会交给上层平台,从异常维度、资源维度、产品维度和大盘维度分别作二次分析,帮助我们从四个方向为用户提供业务,最后输出包括Web、API、流和机器人。
网络大盘
我们的网络大盘覆盖了阿里云全球所有地区,涵盖所有虚拟网络组件,覆盖所有核心指标,包括专有云和公有云,它负责将所有的网络生产组件的核心指标经过多层分析,甚至趋势图统计图和拓扑图等,我们可以了解每一个集群每一个region甚至每一个IP的流量和实时运行情况,网络大盘结合了虚拟网络和物理网络拓扑情况,当任何一个地区发生网络拓扑变化时,整套数据分析系统可以感知到它的变化,并将变化体现在数据聚合算法当中,不需要重启程序,也不需要重新提交变更,我们的网络拓扑和数据分析平台时实时连动的。
为了能够从多个角度看问题,我们把数据拆分成1分钟到1年等多个维度的数据颗粒度,这样我们就可以从多个时间跨度了解网络情况,比如过去三年,阿里云某个地区网络峰值在什么时候,什么时候发生了网络抖动等,这都需要我们拉长时间维度去分析,甚至用两三年的时间来看网络发展方向。多种颗粒度的时间序列数据帮助我们实现在不同时间维度了解我们整个网络运行状况。
网络异常
网络异常分析系统是了解阿里云整个网络稳定性的关键组件,它也是其中最复杂的组件。既要做到准确提取出异常,同时又要避免过多噪音,不要让研发和用户收到过多的报警,我们遵循以下四方面:
1.主动探测。阿里云全球部署了很多探测节点,包括overlay和underlay,并对overlay和underlay进行持续探测,一旦出现设备问题就会立刻发现并报警,管理网络人员会立即进行处理恢复。
2.指标波动。当网络出现问题时,指标异常是在所难免的,每种指标可能发生不同的异常和问题,由于一个数据分析链路非常长,从采集到数据聚合到清洗到加工,需要经过很多工序,依赖很多中间件,中间可能会存在数据链的抖动或指标毛刺。针对这些问题,我们设计实现了一套算法,即使中间链路发生抖动或产生指标毛刺,都可以过滤掉,把真正可疑的出现问题或发生故障的指标波动提取出来,作为异常暴露出来。
3.区间预测。我们与浙大合作设计并实现了一套基于机器学习的区间预测新算法,可以基于过去指标历史数据,来分析出每一种指标的流量特性,形成数据模型,基于数据模型,可以预测出接下来一段时间内该实例在哪个区间波动。随后,当我们的实际指标达到那个时间后,我们会根据实际指标的数值以及区间偏移量来评估异常分数,这个分数作为网络异常因子生成可疑的网络异常。
4.异常聚合。异常聚合不是一个算法,它是基于网络拓扑聚合异常事件,收敛异常并定位异常范围。通过所有异常结合网络拓扑以及网络链路,将所有异常收敛成一个高等级异常,这个异常会精确囊括过去一分钟哪个地方发生什么问题,影响了多少台设备和实例,影响了多少用户和多少产品,因此而使流量下跌多少,产品业务受到了多久影响。
网络资源
资源分析是我们专门用来作资源规划、资源质量分析等的组件。我们结合了当前所有产品的售卖数据和实际集群运行指标,确定资源水位,分析过去一段时间内每种指标的平均消耗速度,最快的指标什么时候会消耗完,然后预测接下来的一定时间内哪个地区集群会因此容量达到上限。
我们还做了全球资源消耗多维度统计和资源质量分析,通过对一系列的网络资源质量分析,包括阻能探测、边缘节点丢包和延时情况来了解全球所有网络资源质量情况。
此外,我们还做了资源规划,我们基于历史数据预测库存消耗,确定资源消耗量并购买资源,为接下来的业务发展作准备。
网络运营
网络运营包括以下四个方面:
1.营收分析,我们可以分析出每天收入波动原因,哪些行业和用户导致营收发生增长或变化的,这些用户是如何使用我们的产品的。
2.用户分析,对网络产品的用户画像进行分析,分析每个用户的资源使用情况。
3.实例分析,分析网络产品实例。
4.成本分析,分析网络产品成本是否符合预期。
规划和演进
未来,我们想要变得更快、更准、更智能。具体体现在以下几方面:
1.秒级监控:我们想要秒级甚至亚秒级速度分析所有指标,想要做到这一点,我们还会遇到更大量的数据冲击,比如超过现在百倍的数据吞吐量。
2.指标分类:对各类指标进行特征分类,分析相关性,帮助用户找出网络特性,告知用户购买什么样的网络产品。
3.全链路诊断:与虚拟网络和物理网络一起合作,把网络上问题直接定位出来。
4.智能调度:灵活调度网络流量,当某处业务出现问题时,实时调度流量到其它地区。
本文由云栖志愿小组毛鹤整理编辑





